联邦学习算法详解:概念、优化与挑战
版权申诉
"联邦学习算法综述"
联邦学习是一种新兴的机器学习框架,旨在解决数据孤岛问题,即在保持数据本地化的同时实现模型的协同训练。近年来,由于其在金融、医疗健康和智慧城市等领域的应用潜力,联邦学习受到了广泛关注。本文从三个主要层面深入探讨了联邦学习算法。
首先,联邦学习的定义强调了它与传统的分布式学习的区别。分布式学习通常要求数据集中到一个中心节点进行训练,而联邦学习则允许数据在各个设备上本地处理,仅交换模型参数,从而保护数据隐私。联邦学习的架构通常包括服务器端和多个客户端,服务器协调模型更新,客户端则执行本地训练。
其次,联邦学习可以基于机器学习和深度学习算法进行分类。在机器学习领域,可以有基于梯度下降的联邦学习算法,如FedSGD,以及基于模型聚合的算法,如FedAvg。在深度学习方面,可以采用卷积神经网络(CNN)或循环神经网络(RNN)等结构,结合联邦学习策略进行训练。这些方法在确保数据安全的同时,提高了模型的泛化能力。
然后,文章关注了联邦学习的优化算法,主要从通信成本、客户端选择和聚合方式三个方面展开。通信效率是联邦学习的一大挑战,通过压缩技术、异步通信模式和选择性同步等方式可以降低通信开销。客户端选择策略可以依据设备的计算能力和数据量进行优化,确保训练的效率和公平性。聚合方式的优化则包括了权重平均、元学习等策略,以提升全局模型的性能。
联邦学习目前面临的主要挑战包括通信效率低、系统异构性和数据异构性。通信效率问题可以通过更有效的编码和压缩技术来缓解;系统异构性是指参与训练的设备硬件和网络条件差异大,需要适应性算法来应对;数据异构性是指各客户端数据分布不均匀,可能导致模型偏见,解决办法包括个性化模型和数据增强。
文章最后总结了联邦学习的研究现状,并对未来的研究方向给出了展望,包括更高效的通信协议、更好的隐私保护机制、适应异构环境的优化算法以及针对特定领域的联邦学习应用。联邦学习作为一个快速发展的领域,将继续推动数据隐私和机器学习的平衡,为实际应用提供更加安全和高效的解决方案。
STUDY 研究 67
行聚合,使用一定的加密技术对参数进行
加密,这些方法将会在后面的章节中详细
讨论。
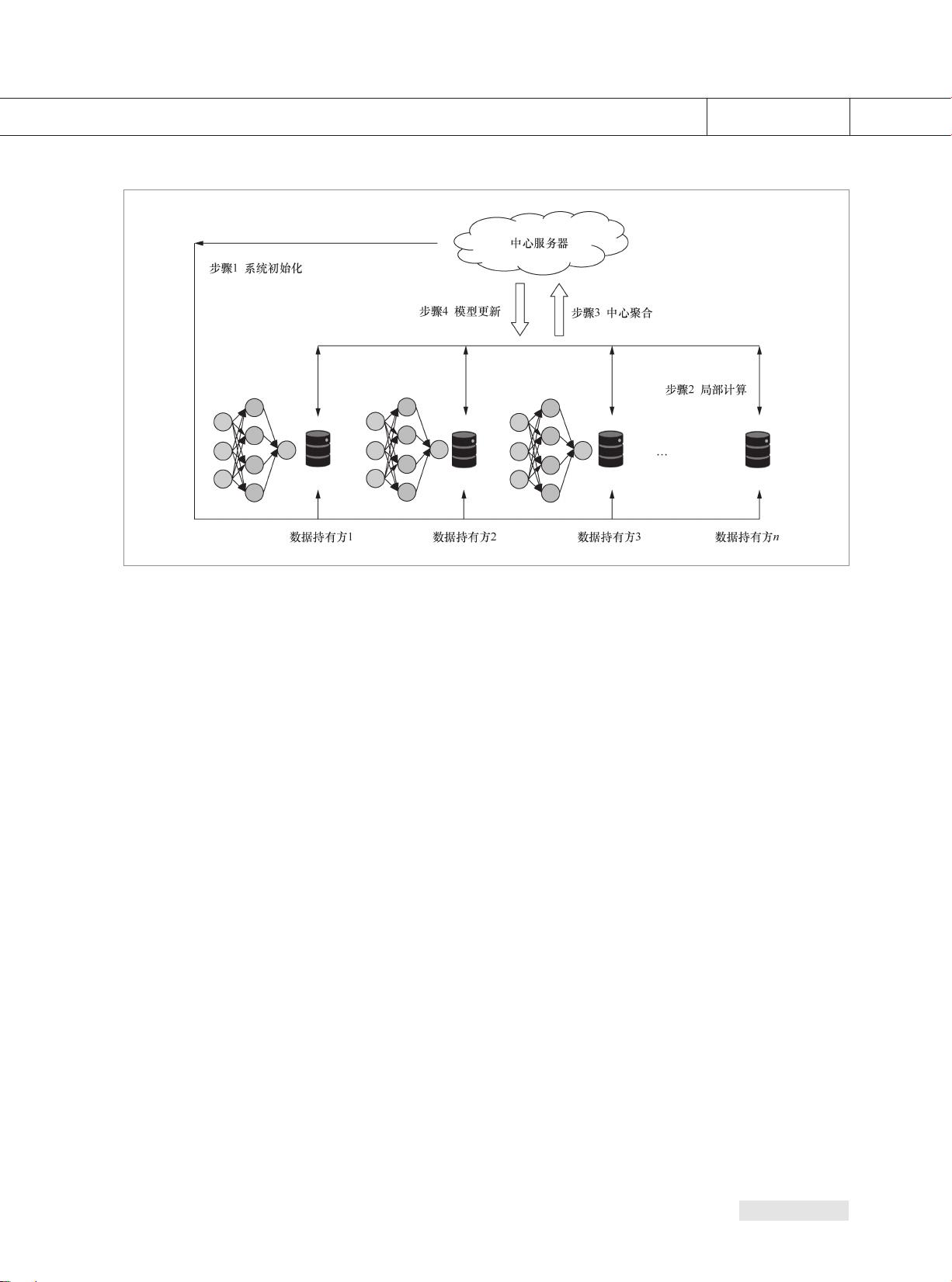
步骤4:模型更新。中心服务器根据聚
合后的结果对全局模型进行一次更新,并
将更新后的模型返回给参与建模的数据
持有方。数据持有方更新本地模型,并开
启下一步局部计算,同时评估更新后的模
型性能,当性能足够好时,训练终止,联合
建 模 结 束 。建 立 好 的 全 局 模 型 将 会 被 保 留
在中心服务器端,以进行后续的预测或分
类工作。
上述过程是一个典型的基于客户端-
服 务 器 架 构 的 联 邦 学 习 过 程 。但 并 不 是 每
个联邦学习任务都一定要严格按照这样的
流程进行操作,有时可能会针对不同场景
对流程做出改动,例如,适当地减少通信
频率来保证学习效率
[26-31]
,或 者 在 聚 合 后
增加一个逻辑判断,判断接收到的本地计
算结果的质量
[32-35]
,以提升联邦学习系统
的鲁棒性
[36]
。
2.3 联邦学习与传统分布式学习的区别
基于客户端-服务器架构的联邦学习
和分布式机器学习
[37]
都是用来处理分布式
数据的,但在应用领域、数据属性和系统
构成等方面,其与分布式机器学习存在差
异 ,主 要 如 下 。
(1)应 用 领 域
大量的数据或者较大的模型往往对计算
资 源 有 较 高 的 要 求 。单 一 的 计 算 节 点 已 经 不
能满足需求。分布式机器学习将训练数据或
模型参数分布在各个计算或存储节点,利用
中心服务器对节点进行调度,加速模型的训
练。而当数据具有隐私敏感属性时,分布式机
器学习的中心调度将会给用户数据带来极大
的隐私泄露风险
[38]
。联邦学习始终将数据存
储 在 本 地 ,相 比 需 要 将 数 据 上 传 到 服 务 器 的
方式,可以最大限度地保障数据隐私。
(2)数 据 属 性
机器学习的主要目的是寻找数据的概
图 2 客户端 - 服务器架构的联邦学习流程
2020055-4
下载后可阅读完整内容,剩余18页未读,立即下载
相关推荐
422 浏览量
766 浏览量
211 浏览量
113 浏览量
113 浏览量
107 浏览量
2025-01-16 上传
248 浏览量

weixin_38672962
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开








最新资源
- libuv在VC2015++中的应用实例解析
- Linux CRT绿色版解压工具发布
- Wow.js动画插件:配合animate.css的页面元素动画效果
- 利用百度地图开发工具轻松获取SHA1签名
- 个性化屏保制作与应用教程
- CPU信息MD5多重加密注册机实现方法
- CsipSimple-master:轻松实现Android语音电话功能
- VC++6.0环境下实现哈夫曼编码及译码操作
- 跨平台人脸检测与识别实现:HTML与Python结合教程
- 基于JSP+Struts+Hibernate+Oracle的在线考试系统设计与实现
- QT开发环境搭建全攻略与工具下载指南
- Java操作Excel工具类库jxl-2.6.jar使用详解
- 苹果电脑与手机PPT背景图片下载
- 期末大作业参考:精选JSP项目源码分享
- SenchaCmd 4.0.5.87 Windows版本发布
- 基于Android Studio的GridLayout计算机界面实现
