Scrapy初学者教程:理论结合简书网爬虫实战
需积分: 8 22 浏览量
更新于2024-08-29
收藏 760KB PDF 举报
回ScrapyEngine。
Spider(爬虫):爬虫是Scrapy的核心部分,它负责解析从下载器返回的网页内容,并从中提取出需要的数据(比如文章标题、作者信息等)。同时,爬虫还会发现新的链接,形成新的请求,这些请求会被发送到调度器,等待下载。
1.2、两个中间件
DownloaderMiddlewares(下载中间件):下载中间件就像过滤网,位于Scrapy Engine和Downloader之间。它们可以处理请求(requests)和响应(responses),例如添加自定义的HTTP头,处理重定向,处理网页编码问题,或者在请求发送出去前或响应返回给引擎前进行其他定制处理。
SpiderMiddlewares(爬虫中间件):爬虫中间件则位于Spider和Engine之间,它们用于处理Spider产生的输出(通常是Items和Requests)以及从Downloader传递给Spider的Responses。中间件允许你在不修改Spider代码的情况下,实现如数据清洗、异常处理、去重等功能。
1.3、项目简说
在Scrapy项目中,我们通常会创建一个Item来定义要抓取的数据结构,比如在简书的案例中,可能包括文章ID、标题、作者、发布时间等字段。接着,编写Spider来解析网页,提取Item实例。Scrapy使用XPath或CSS选择器来定位数据。此外,我们还需要配置pipelines来处理Item,比如清洗数据、存储到数据库或文件系统。
二、Scrapy简书网项目
1、思路步骤
1.1、分析网页:首先需要通过浏览器的开发者工具分析网页结构,找到目标数据在HTML中的位置,以便用XPath或CSS选择器提取。
1.2、解析网页:在Spider中,定义解析函数,使用Scrapy提供的Selector类或直接使用XPath/CSS选择器,从下载的HTML内容中抽取所需信息。
1.3、编写item.py:定义Item类,用于描述要抓取的数据结构,如定义字段和类型。
1.4、编写Spider:创建一个Spider类,实现start_requests()方法来发起初始请求,以及parse()方法(或其他自定义解析方法)来处理响应,生成新的请求或提取Item。
1.5、编写pipelines.py:在pipelines文件中定义处理Item的类,实现process_item()方法,可以进行数据清洗、验证和持久化存储操作。
2、项目代码
项目中通常包含以下文件:
- settings.py:配置Scrapy项目的行为,如设置中间件、下载延迟、Item Pipeline等。
- items.py:定义Item类。
- spiders/:包含Spider的Python模块或文件,每个Spider是一个类,继承自Scrapy的Spider基类。
- pipelines.py:定义Item Pipeline类。
以上是对Scrapy框架的简单介绍以及如何使用Scrapy进行实战项目的步骤。Scrapy的强大在于其模块化的结构,方便扩展和定制,使得爬虫开发更加高效。对于初学者,通过实战项目可以更好地理解和掌握Scrapy的基本工作流程。在实际应用中,还需要注意遵守网站的robots.txt规则,尊重网站的爬虫政策,合理合法地进行网络爬取。
我与我与Scrapy的初次相识,理论的初次相识,理论+实战入门实战入门Scrapy
和Scrapy接触不久,做一个项目学习并记录一下,这个代码倒是写了有段时间了,一直没来写博客,这爬虫集合的更新也耽误好久了。随着疫情的好转,我这也恢复正常写博文(糊脸,疫情不是自己不
写博文的理由),大家一起加油呀,加油加油,一起都已经好起来了。
实战项目是爬取简书网(https://www.jianshu.com/) 二级页面信息的Scrapy项目,这也就个入门,大佬看见了一定请指点一下。
目录目录一、我对Scrapy的一些浅显的理解1.1、五大部件1.2、两个中间件1.3、项目简说二、Scrapy简书网项目1、思路步骤1.1、分析网页1.2、解析网页1.3、编写item.py1.4、编写Spider1.5、编写
pipelines.py2、项目代码ItemPipelinessettingsSpider
一、我对一、我对Scrapy的一些浅显的理解的一些浅显的理解
Scrapy就是个爬虫框架,它像个房子的钢筋混凝土框架一样,使得我们可以在这个框架里自由发挥,我们只需要在该安装“门”的地方装上“门”(做填空一样),接下来就可以打开爬虫的大门了,十分的便
捷。
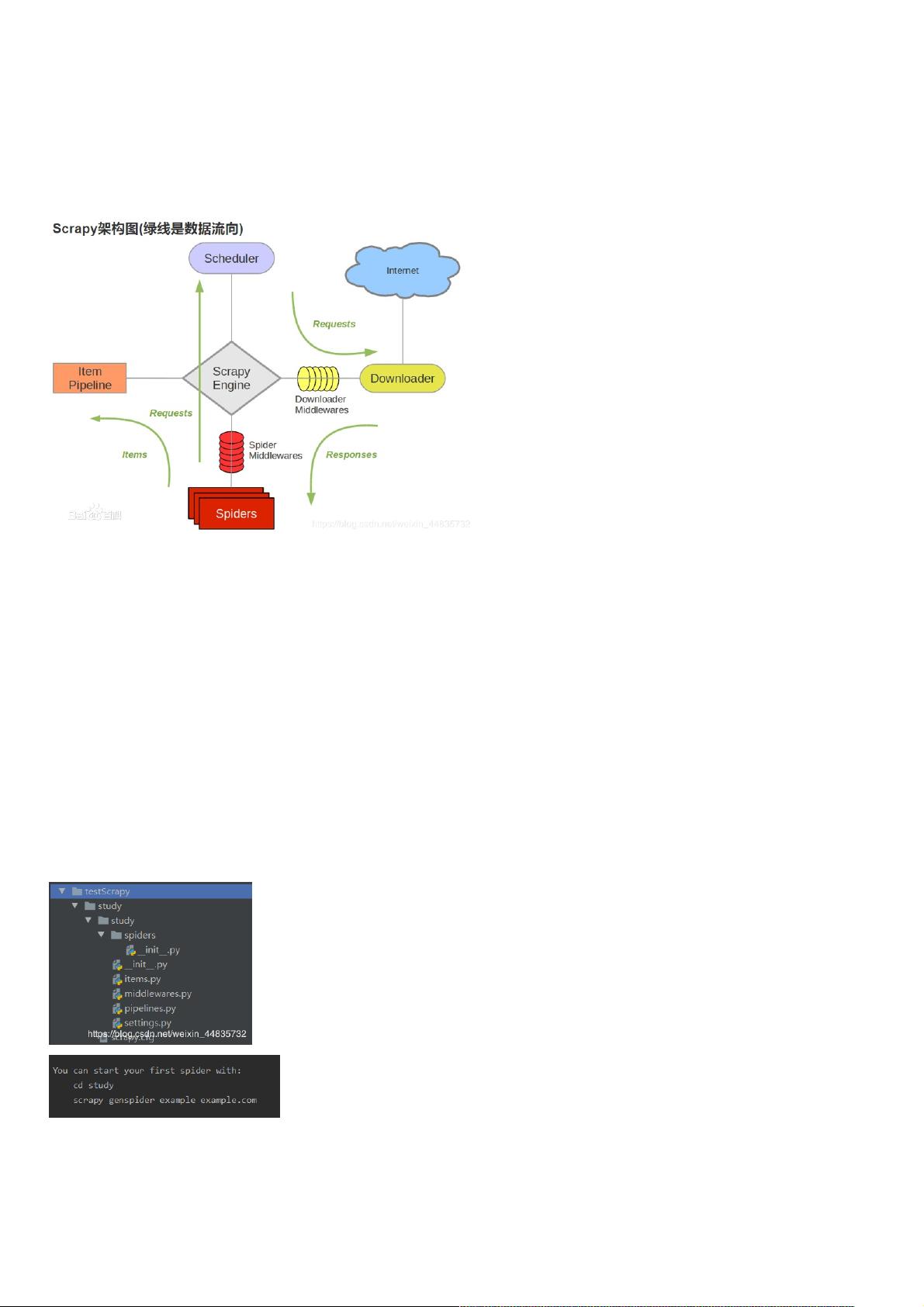
我这些浅显的话还是要搭一些科普,不然就太没营养了,我从百*百科cv大法了这个图,下面就我的理解解释一下这图中五大部件:Scrapy Engine(引擎)、Scheduler(调度器)、Downloader(下载
器)、Spider(爬虫)、Item Pipeline(管道),及两个中间件:Downloader Middlewares(下载中间件)、Spider Middlewares(爬虫中间件)。
1.1、五大部件、五大部件
Scrapy Engine(引擎)引擎):顾名思义,看到引擎,我就想到了汽车的发动机,这肯定是一个十分十分重要的东西。引擎关联着其他的所有部件,从图里也看出,引擎起到一个信号塔的作用,传递着各部件
之间的信息、数据等。
Scheduler(调度器)(调度器):调度器调度器,调度两个字尤其突出,那我们可以想到调度些什么呢?调度爬虫下载的请求,它会将从引擎传来的请求加入队列当中,当引擎需要的时候再给回引擎。
Downloader(下载器)(下载器):下载器,啊哈,简单,就是下载网页嘛,不就是爬虫了嘛,错错错,这个下载器不是爬虫,Scrapy分工十分明确的。下载器是按照引擎给的网页请求,下载网页的内容然后返
回给引擎,由引擎交给爬虫,它就专门下载网页,也是后面Spider代码里面的response的由来。
Spider(爬虫)(爬虫):这里就比较熟悉了,自己编写爬虫逻辑,进行网页的解析跳转等等操作,我们使用Scrapy绝大功夫都在这里了。
Item Pipeline(管道)(管道):这个啊,就是对Spider获取到的数据进行一些处理,包括(清洗,过滤,储存等等)。
1.2、两个中间件、两个中间件
Downloader Middlewares(下载中间件)(下载中间件):可以在这里设置下载的请求头,下载的时间间隔,代理等等操作,在一定程度上使Spider更加纯粹了。
Spider Middlewares(爬虫中间件)(爬虫中间件):看图它位于引擎和spider之间,而经由这条线路上的是request请求和response请求的返回还有items爬取结果(就那三根绿线),这个中间件意味可以自己定义扩
展request、response和items。
1.3、项目简说、项目简说
前面讲的五大部件,两个中间件都太理论了,感觉Scrapy离我们还是有点远,下面就简单讲一下项目的知识,后面还有实战。
1、先要安装呢,我这里不介绍普通python安装Scrapy,太复杂了,要安装好多库,我用的是Anaconda,特别方便,在终端cmd输入conda install scrapy就行,还是有不明白的可以参考Anaconda按照
Scrapy。
2、安装好后,输入这条指令,会在你输入指令的那个目录下生成自定义项目名的Scrapy项目。
scrapy startproject 项目名
比如这是我在testScrapy目录下执行了scrapy startproject study后指定生成的目录,没有任何改动下,我们就是这么多文件。
3、而且它会提示你cd到项目目录下,输入指令生成一个spider文件。
这里我解释一下genspider后接的参数,第一个就是spider的名字,第二个是该爬虫的限定网域,以保证不会爬到别的网页去。
scrapy genspider test www.baidu.com
4、到上面我们这个框架算是完备了,看一下完整的目录。
(这是我的理解,有错误望指点一下)我们要需要修改的也就是test.py(Spider)、item.py、pipelines.py、settings.py。
下载后可阅读完整内容,剩余6页未读,立即下载
2022-05-08 上传
2024-08-04 上传
2022-09-20 上传
2018-05-02 上传
2024-07-11 上传
2024-02-22 上传
2021-05-02 上传
2021-04-29 上传
2024-02-25 上传

weixin_38706747
- 粉丝: 5
- 资源: 962
 我的内容管理
展开
我的内容管理
展开







最新资源
- StarModAPI: StarMade 模组开发的Java API工具包
- PHP疫情上报管理系统开发与数据库实现详解
- 中秋节特献:明月祝福Flash动画素材
- Java GUI界面RPi-kee_Pilot:RPi-kee专用控制工具
- 电脑端APK信息提取工具APK Messenger功能介绍
- 探索矩阵连乘算法在C++中的应用
- Airflow教程:入门到工作流程创建
- MIP在Matlab中实现黑白图像处理的开源解决方案
- 图像切割感知分组框架:Matlab中的PG-framework实现
- 计算机科学中的经典算法与应用场景解析
- MiniZinc 编译器:高效解决离散优化问题
- MATLAB工具用于测量静态接触角的开源代码解析
- Python网络服务器项目合作指南
- 使用Matlab实现基础水族馆鱼类跟踪的代码解析
- vagga:基于Rust的用户空间容器化开发工具
- PPAP: 多语言支持的PHP邮政地址解析器项目
