16种相似性度量实现详解:从欧氏距离到KL距离
需积分: 2 192 浏览量
更新于2024-09-07
收藏 149KB DOCX 举报
本文档汇总了16种常见的相似性度量方法,包括欧氏距离、曼哈顿距离、切比雪夫距离等,并通过举例和MATLAB代码演示了它们的计算过程,这些度量在分类任务中用于评估样本间的相似程度。
1. 欧氏距离(Euclidean Distance)是最基础的距离度量,适用于多维空间中的向量。它通过计算两个点之间直线路径的长度来确定它们之间的距离。在二维和三维空间中,欧氏距离的公式分别对应于两点间直线距离的平方和的平方根。在n维空间中,两个向量的欧氏距离可以通过向量差的平方和的平方根得到。在MATLAB中,可以使用`pdist`函数计算欧氏距离。
2. 曼哈顿距离(Manhattan Distance)也称为城市街区距离,它是在坐标轴上沿每个维度测量的绝对距离之和。例如,在二维平面上,两点的曼哈顿距离等于它们在x轴和y轴上的绝对差值之和。在MATLAB中,同样可以使用`pdist`函数,但需指定参数'cityblock'来计算曼哈顿距离。
3. 切比雪夫距离(Chebyshev Distance)是每个坐标轴上绝对差的最大值。它在棋盘游戏等场景中很常见,因为移动只能沿着网格线进行。切比雪夫距离可以看作是曼哈顿距离的上限,当所有坐标轴上的差异都相同时,两者相等。
4. 闵可夫斯基距离(Minkowski Distance)是一般化的距离度量,包含了欧氏距离(p=2)和曼哈顿距离(p=1)作为特殊情况,其公式为各维度差的p次方和的1/p次方。当p趋于无穷大时,闵可夫斯基距离接近于最大值距离(Maximum Norm)。
5. 标准化欧氏距离(Standardized Euclidean Distance)是在欧氏距离基础上,对数据进行Z-score标准化,使各特征具有相同的尺度,从而消除量纲影响。
6. 马氏距离(Mahalanobis Distance)考虑了变量间的协方差,通过协方差矩阵计算距离,能更准确地反映变量间的相对距离。
7. 夹角余弦(Cosine Similarity)衡量的是两个向量方向的相似性,值介于-1到1之间,值越接近1,表示角度越小,向量越相似。
8. 汉明距离(Hamming Distance)用于计算二进制字符串或字符序列的差异,即对应位置上不同元素的数量。
9. 杰卡德距离(Jaccard Distance)与杰卡德相似系数(Jaccard Similarity)是衡量集合相似性的指标,基于两个集合交集和并集的比例。
10. 相关系数(Correlation Coefficient)和相关距离(Correlation Distance)衡量两个变量间线性相关程度,相关系数的取值范围在-1到1之间,相关距离则取其负值。
11. 信息熵(Entropy)在信息论中衡量信息的不确定性,也可用于衡量数据的纯度或复杂性。
12. 兰氏距离(Lance-Williams Distance)是谱聚类中使用的距离度量,考虑了数据集的邻接矩阵。
13. 斜交空间距离(Angular Distance)是根据向量在高维空间的夹角来衡量它们的相似性。
14. 最大-最小相似度(Max-Min Similarity)通过比较特征的最大值和最小值来评估相似性。
15. 指数相似度(Exponential Similarity)是基于指数函数的相似性度量,常用于衰减权重。
16. KL距离(Kullback-Leibler Divergence)或相对熵,是信息论中衡量两个概率分布差异的度量。
在分类任务中,选择合适的相似性度量至关重要,因为它直接影响模型的性能和准确性。每种度量都有其适用场景,需要根据数据特性和问题需求来选择。在实际应用中,可能会结合多种距离度量进行综合分析,或者通过调整度量参数以优化结果。
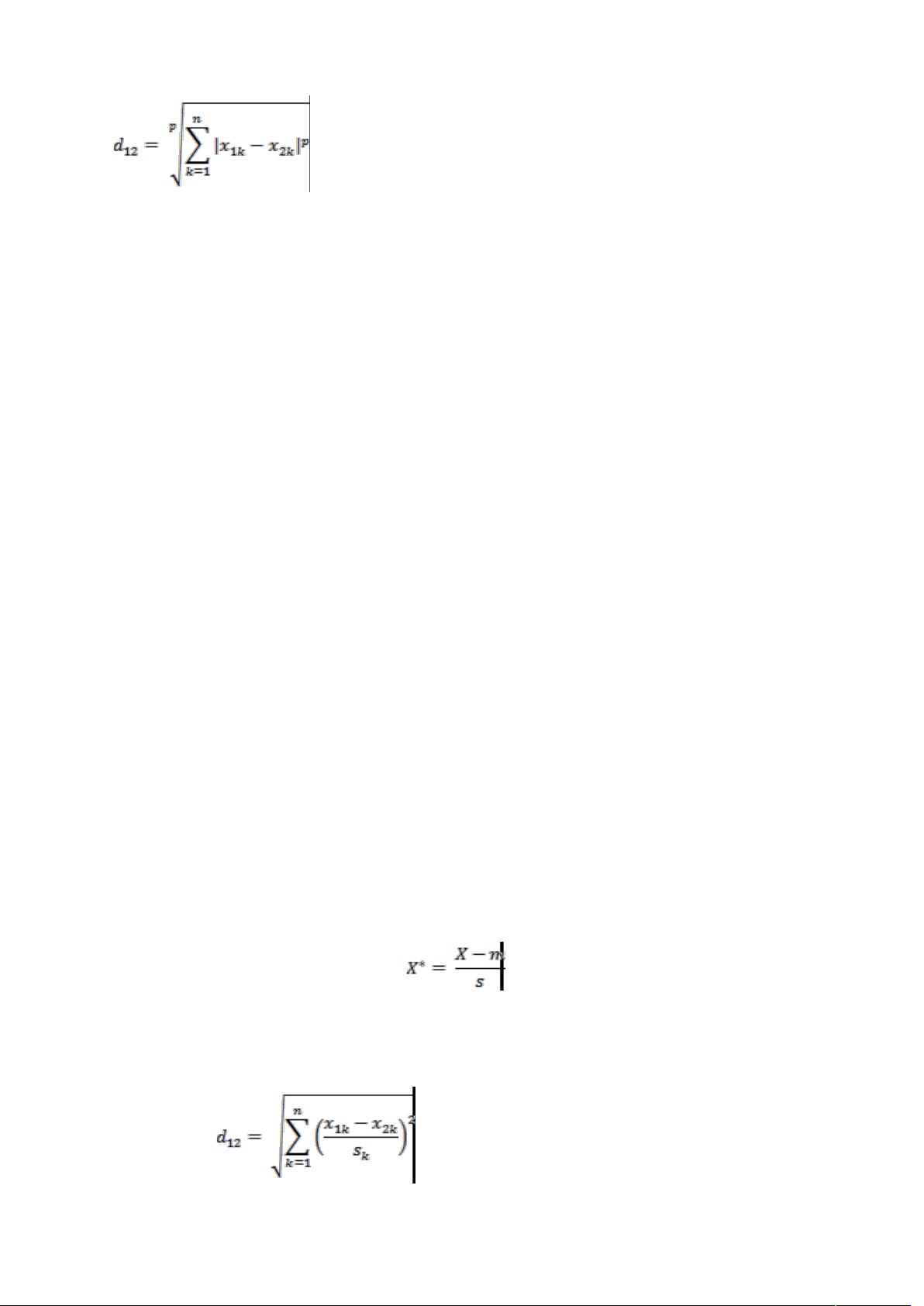
其中 ' 是一个变参数。
当 ', 时,就是曼哈顿距离
当 ', 时,就是欧氏距离
当 '89时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离。
闵氏距离的缺点
闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在明显的缺点。
举个例子:二维样本身高#体重,其中身高范围是 :,体重范围是 :,有三个样本:
#,$#,#。那么 与 $ 之间的闵氏距离(无论是曼哈顿距离、欧氏距离或切
比雪夫距离)等于 与 之间的闵氏距离,但是身高的 真的等价于体重的 4; 么?因此用
闵氏距离来衡量这些样本间的相似度很有问题。
简单说来,闵氏距离的缺点主要有两个:将各个分量的量纲,也就是“单位”当作相同
的看待了。没有考虑各个分量的分布(期望,方差等可能是不同的。
$ 计算闵氏距离
例子:计算向量#、#、#两两间的闵氏距离(以变参数为 的欧氏距离为例)
),-../
,'()#043<40#
结果:
,
5. 标准化欧氏距离(Standardized Euclidean distance )
标准欧氏距离的定义
标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既
然数据各维分量的分布不一样,好吧!那我先将各个分量都“标准化”到均值、方差相等吧。均值
和方差标准化到多少呢?这里先复习点统计学知识吧,假设样本集 ) 的均值为 ,标准差
(((7=3为 ,那么 ) 的“标准化变量”表示为:
而且标准化变量的数学期望为 ,方差为 。因此样本集的标准化过程((%=3用公式
描述就是:
标准化后的值 ,标准化前的值 - 分量的均值 >分量的标准差
经过简单的推导就可以得到两个 维向量 "#"#&#"与 $"#"#&#"间的标准化欧氏
距离的公式:
如 果 将 方 差 的 倒 数 看 成 是 一 个 权 重 , 这 个 公 式 可 以 看 成 是 一 种 加 权 欧 氏 距 离
?;6(@((。
剩余11页未读,继续阅读
2021-01-20 上传
2022-03-13 上传
2022-07-12 上传
2019-02-27 上传
551 浏览量
2022-07-11 上传
2022-07-11 上传
2023-11-07 上传

qq_26697045
- 粉丝: 137
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- StarModAPI: StarMade 模组开发的Java API工具包
- PHP疫情上报管理系统开发与数据库实现详解
- 中秋节特献:明月祝福Flash动画素材
- Java GUI界面RPi-kee_Pilot:RPi-kee专用控制工具
- 电脑端APK信息提取工具APK Messenger功能介绍
- 探索矩阵连乘算法在C++中的应用
- Airflow教程:入门到工作流程创建
- MIP在Matlab中实现黑白图像处理的开源解决方案
- 图像切割感知分组框架:Matlab中的PG-framework实现
- 计算机科学中的经典算法与应用场景解析
- MiniZinc 编译器:高效解决离散优化问题
- MATLAB工具用于测量静态接触角的开源代码解析
- Python网络服务器项目合作指南
- 使用Matlab实现基础水族馆鱼类跟踪的代码解析
- vagga:基于Rust的用户空间容器化开发工具
- PPAP: 多语言支持的PHP邮政地址解析器项目
