Python爬虫六步骤教程:轻松入门数据抓取
需积分: 0 43 浏览量
更新于2024-08-03
1
收藏 1011KB DOCX 举报
Python是一种强大的脚本语言,特别适用于网络爬虫领域,因为它提供了丰富的库和模块来处理网页抓取任务。本文将指导您通过六步骤轻松入门Python爬虫,帮助您从零开始构建数据抓取能力。
**第一步:安装requests和BeautifulSoup库**
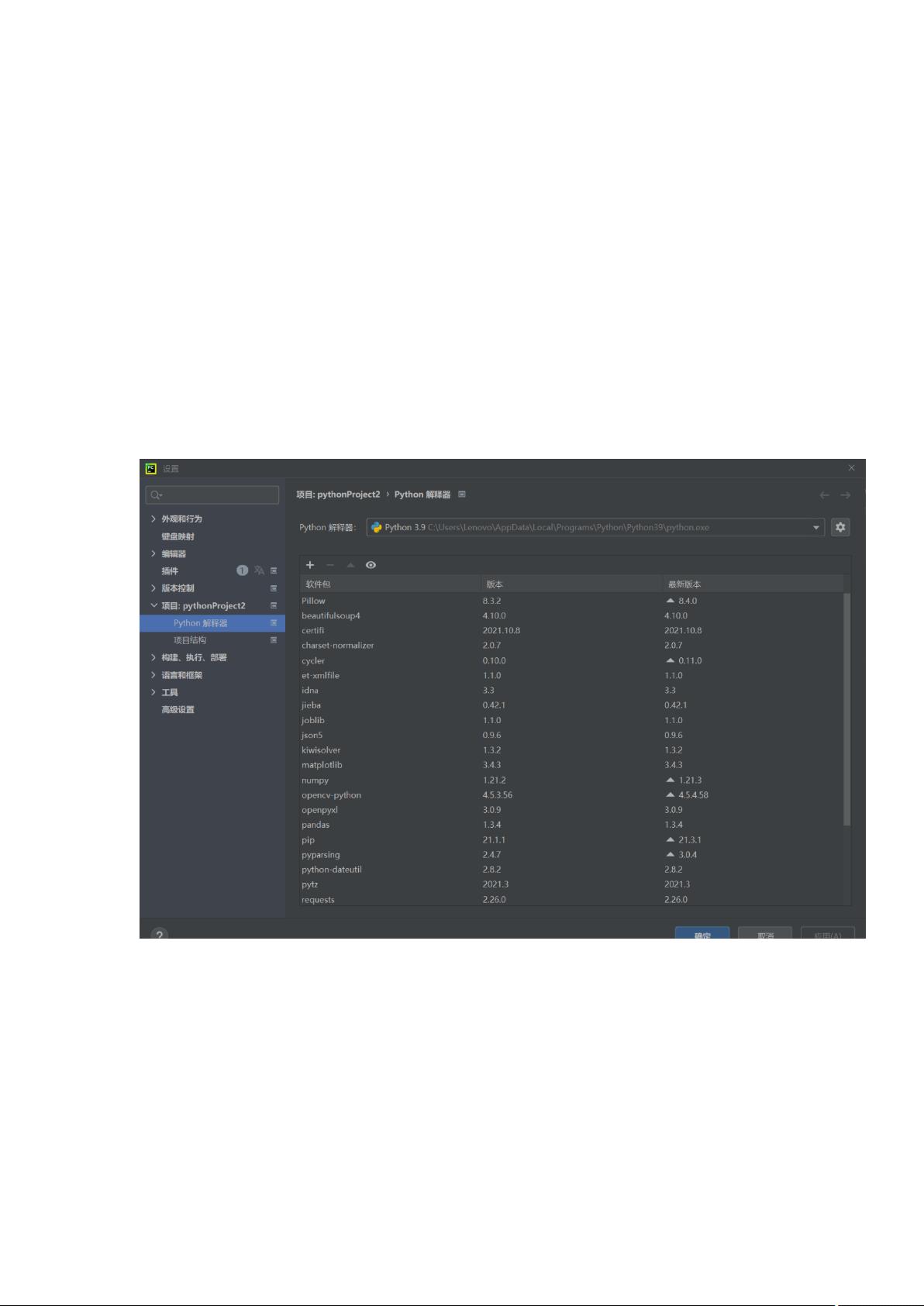
Python爬虫的核心依赖是requests库,用于发送HTTP请求获取网页内容,而BeautifulSoup则用于解析HTML或XML文档。在PyCharm这样的集成开发环境中,安装这两个库非常方便。在PyCharm的设置中,进入项目解释器设置,点击"+"号搜索并安装requests和BeautifulSoup插件,安装完成后即可在代码中导入它们:
```python
import requests
from bs4 import BeautifulSoup
```
**第二步:获取爬虫所需的header和cookie**
在进行网页爬取时,header和cookie至关重要,因为它们模拟浏览器的行为,使得服务器能够识别请求。在微博热搜页面中,您需要查看开发者工具(F12),找到"Network"部分,观察请求的headers和cookies,复制并粘贴到您的代码中,确保程序能正确地定位到目标页面。
```python
cookies = {
'SINAGLOBAL': '6797875236621.702.1603159218040',
# 其他cookie键值对...
}
headers = {
# 头部信息,如User-Agent等
}
```
**第三步至第六步:理解网页结构、解析HTML、数据提取与存储**
1. **理解网页结构**:分析目标网站的HTML结构,确定需要抓取的数据元素所在的标签和属性。
2. **使用BeautifulSoup解析**:利用BeautifulSoup解析HTML文档,定位到所需元素,如`soup.find_all('div', class_='hot-trend')`。
3. **数据提取**:调用元素的方法(如.text)获取文本内容,或者使用CSS选择器或XPath表达式来精确定位。
4. **数据存储**:将抓取到的数据保存到文件、数据库或数据结构(如字典或列表)中,以便后续处理。
在实际操作中,可能涉及处理分页、动态加载内容、反爬虫机制等问题,但核心步骤就是以上所述。随着对Python爬虫技术的深入学习,您将能够解决更复杂的抓取场景,并适应不断变化的网络环境。Python爬虫是一个实践性很强的技能,多动手尝试和学习网络请求、HTML解析以及异常处理,您将快速成为一位熟练的Python爬虫工程师。
Python:六步教会你使⽤python爬⾍爬取数据
前⾔:
⽤python的爬⾍爬取数据真的很简单,只要掌握这六步就好,也不复杂。以前
还以为爬⾍很难,结果⼀上⼿,从初学到把东西爬下来,⼀个⼩时都不到就解
决了。
python爬出六部曲
第⼀步:安装requests库和BeautifulSoup库:
在程序中两个库的书写是这样的:
import requests
from bs4 import BeautifulSoup
由于我使⽤的是pycharm进⾏的python编程。所以我就讲讲在pycharm上安装这
两个库的⽅法。在主页⾯⽂件选项下,找到设置。进⼀步找到项⽬解释器。之
后在所选框中,点击软件包上的+号就可以进⾏查询插件安装了。有过编译器插
件安装的hxd估计会⽐较好⼊⼿。具体情况就如下图所⽰。
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-01-11 上传
2022-03-18 上传
2024-02-20 上传
2023-04-19 上传
点击了解资源详情
2023-09-03 上传

sun7bear
- 粉丝: 1
- 资源: 121
 我的内容管理
展开
我的内容管理
展开







