TiDB实战:业务中的挑战与解决方案
145 浏览量
更新于2024-08-28
收藏 638KB PDF 举报
"TiDB在转转的业务实战"
在当今的互联网行业中,数据存储和管理是企业核心竞争力的重要组成部分。TiDB(Ti: Transactional, DB: Database)作为一个世界级的开源分布式数据库,自2016年推出以来,已经在众多公司中得到了广泛应用,解决了传统单机数据库在面对大规模数据时遇到的挑战。TiDB的设计理念是结合NoSQL的数据处理能力和传统关系型数据库的事务支持,为业务开发提供了更为高效和灵活的解决方案。
在NewSQL数据库出现之前,许多公司通常使用如MySQL这样的单机数据库。然而,随着数据量的增长,"分库分表"成为必然选择,这给研发人员(RD)和数据库管理员(DBA)带来了巨大的维护成本。即使有MyCat、ShardingJDBC等中间件帮助处理分片,复杂性仍然较高。而TiDB作为NewSQL数据库的代表,它支持MySQL协议,降低了开发接入的难度,同时100%支持事务,确保数据一致性,且具备无限水平扩展的能力,避免了手动分库分表的困扰。
然而,TiDB与传统关系型数据库在事务处理上存在显著差异。在MySQL中,事务的成功往往可以通过受影响的行数来判断,但在TiDB中,这一原则并不适用。这是因为TiDB采用了Percolator事务模型,类似于乐观锁的实现,事务开启和执行过程中不加锁,只有在提交时才会进行锁检查。这可能导致在某些情况下,事务虽然返回成功,但实际上并未按预期修改数据。
面对这种差异,开发者需要重新思考在TiDB环境中如何处理事务。在同步RPC调用中,不能单纯依赖影响条数来确认返回值,可能需要设计更复杂的确认机制。在多表操作中,如果依赖主表的更新结果来决定其他表的操作,那么需要寻找新的同步策略,例如使用两阶段提交或者利用TiDB提供的分布式事务特性。
解决这些问题的关键在于理解和适应TiDB的事务模型。在TiDB中,事务的提交分为PreWrite和Commit两个阶段,PreWrite阶段会对涉及的行添加分布式版本号的锁,以确保并发控制。在Commit阶段,如果发现版本冲突,事务会被回滚。因此,开发人员需要在代码设计时考虑到这些特性,以避免因事务模型差异导致的错误和异常。
TiDB在转转的业务实战中展现了其在处理大数据和复杂事务场景下的优势,但同时也提出了新的挑战,即如何调整业务逻辑以适应其独特的事务处理方式。通过深入理解TiDB的事务模型和优化事务处理策略,企业可以在享受其带来的高性能和弹性扩展的同时,确保数据的一致性和业务的稳定性。
TiDB在转转的业务实战在转转的业务实战
开篇
世界级的开源分布式数据库 TiDB 自 2016 年 12 月正式发布第一个版本以来,业内诸多公司逐步引入使用,并取得广泛认
可。
对于互联网公司,数据存储的重要性不言而喻。在 NewSQL 数据库出现之前,一般采用单机数据库(比如 MySQL )作为存
储,随着数据量的增加,“分库分表”是早晚面临的问题,即使有诸如 MyCat、ShardingJDBC 等优秀的中间件,“分库分表”还
是给 RD 和 DBA 带来较高的成本; NewSQL 数据库出现后,由于它不仅有 NoSQL 对海量数据的管理存储能力、还支持传统
关系数据库的 ACID 和 SQL,所以对业务开发来说,存储问题已经变得更加简单友好,进而可以更专注于业务本身。而
TiDB,正是 NewSQL 的一个杰出代表!
站在业务开发的视角,TiDB 最吸引人的几大特性是:
支持 MySQL 协议(开发接入成本低);
100% 支持事务(数据一致性实现简单、可靠);
无限水平拓展(不必考虑分库分表)。
基于这几大特性,TiDB 在业务开发中是值得推广和实践的,但是,它毕竟不是传统的关系型数据库,以致我们对关系型数据
库的一些使用经验和积累,在 TiDB 中是存在差异的,现主要阐述“事务”和“查询”两方面的差异。
TiDB 事务和 MySQL 事务的差异
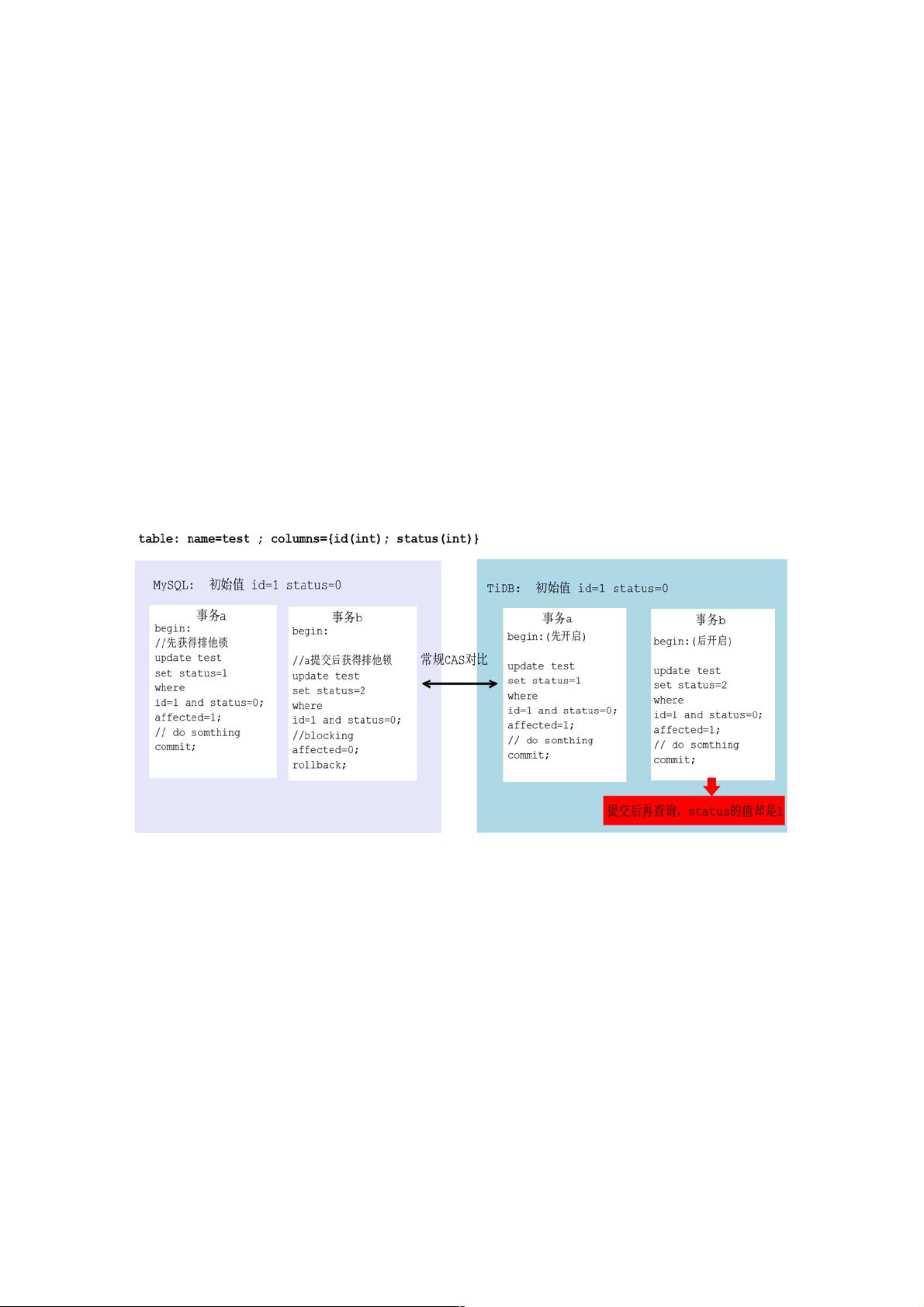
MySQL 事务和 TiDB 事务对比
在 TiDB 中执行的事务 b,返回影响条数是 1 (认为已经修改成功),但是提交后查询,status 却不是事务 b 修改的值,而是
事务 a 修改的值。
可见,MySQL 事务和 TiDB 事务存在这样的差异:
MySQL 事务中,可以通过影响条数,作为写入(或修改)是否成功的依据;而在 TiDB 中,这却是不可行的!
作为开发者我们需要考虑下面的问题:
同步 RPC 调用中,如果需要严格依赖影响条数以确认返回值,那将如何是好?
多表操作中,如果需要严格依赖某个主表数据更新结果,作为是否更新(或写入)其他表的判断依据,那又将如何是好?
原因分析及解决方案
对于 MySQL,当更新某条记录时,会先获取该记录对应的行级锁(排他锁),获取成功则进行后续的事务操作,获取失败则
阻塞等待。
对于 TiDB,使用 Percolator 事务模型:可以理解为乐观锁实现,事务开启、事务中都不会加锁,而是在提交时才加锁。参见
这篇文章( TiDB 事务算法)。
其简要流程如下:
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
2021-10-14 上传
2019-08-23 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-26 上传

weixin_38612139
- 粉丝: 3
- 资源: 885
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
