滴滴:从KV存储升级到自研NewSQL应对业务挑战
200 浏览量
更新于2024-08-27
收藏 1.01MB PDF 举报
滴滴是一家快速发展的互联网公司,随着业务扩张,其面临了数据量剧增和请求压力的挑战。传统的分库分表策略虽能在一定程度上缓解数据量和请求压力,但难以应对业务线的频繁变动,导致数据库管理复杂,Schema变更流程繁琐,对线上服务有潜在影响,且不支持复杂的二级索引。为了解决这些问题,滴滴转向了NewSQL数据库方案,尤其是对开源的分布式NewSQL产品TiDB进行了深入研究。
TiDB虽被公认为优秀的新一代SQL数据库,但不适合滴滴的业务需求。首先,TiDB强调事务一致性,这在追求低延迟(例如毫秒级的99%响应时间)的场景下显得不适用,因为其2PC方案会增加延迟。其次,滴滴的业务大部分并不依赖分布式事务,可以通过其他补偿机制来规避。此外,TiDB的三副本存储模式会带来较高的空间成本,且内部的一些特定离线数据导入在线系统的场景无法直接与TiDB集成。
鉴于这些考虑,滴滴选择在自有的分布式键值存储系统Fusion基础上构建NewSQL解决方案。Fusion基于Codis架构,兼容Redis协议和数据结构,底层使用高效存储引擎RocksDB,已经在滴滴内部广泛应用,是重要的在线存储基础设施。Fusion采用了hash分片技术,通过proxy将用户请求路由到对应的存储节点,确保数据分布均匀,减少查询延迟。
在Fusion这个高并发、低延迟、大容量的存储层之上,滴滴构建了一个定制化的NewSQL系统,旨在提供更灵活的Schema变更能力,支持实时业务需求,同时降低成本并提高效率。这样的转变使得滴滴能够更好地适应业务发展,提升整体技术栈的性能和适应性。
滴滴从滴滴从KV存储到存储到NewSQL实战实战
一. 遇到的问题
滴滴的业务快速持续发展,数据量和请求量急剧增长,对存储系统等压力与日俱增。虽然分库分表在一定程度上可以解决数据
量和请求增加的需求,但是由于滴滴多条业务线(快车,专车,两轮车等)的业务快速变化,数据库加字段加索引的需求非常
频繁,分库分表方案对于频繁的 Schema 变更操作并不友好,会导致 DBA 任务繁重,变更周期长,并且对巨大的表操作还会
对线上有一定影响。同时,分库分表方案对二级索引支持不友好或者根本不支持。
鉴于上述情况,NewSQL 数据库方案就成为我们解决业务问题的一个方向。
二. 开源产品调研
最开始,我们调研了开源的分布式 NewSQL 方案:TiDB。虽然 TiDB 是非常优秀的 NewSQL 产品,但是对于我们的业务场景
来说,TiDB 并不是非常适合,原因如下:
我们需要一款高吞吐,低延迟的数据库解决方案,但是 TiDB 由于要满足事务,2pc 方案天然无法满足低延迟(100ms 以内的
99rt,甚至 50ms 内的 99rt)
我们的多数业务,并不真正需要分布式事务,或者说可以通过其他补偿机制,绕过分布式事务。这是由于业务场景决定的。
TiDB 三副本的存储空间成本相对比较高。
我们内部一些离线数据导入在线系统的场景,不能直接和 TiDB 打通。
基于以上原因,我们开启了自研符合自己业务需求的 NewSQL 之路。
三. 我们的基础
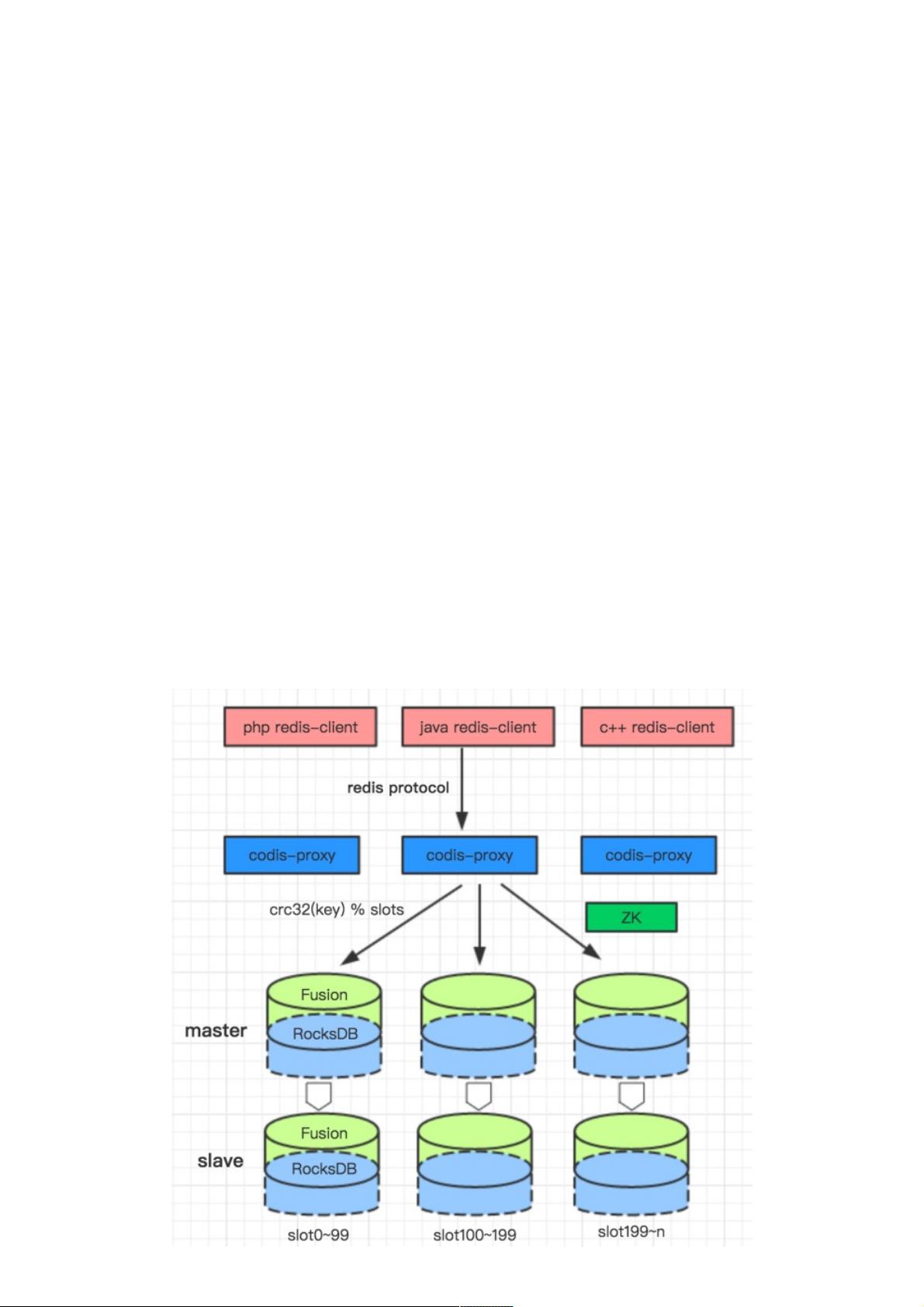
我们并没有打算从 0 开发一个完备的 NewSQL 系统,而是在自研的分布式 KV 存储 Fusion 的基础上构建一个能满足我们业务
场景的 NewSQL。Fusion 是采用了 Codis 架构,兼容 Redis 协议和数据结构,使用 RocksDB 作为存储引擎的 NoSQL 数据
库。Fusion 在滴滴内部已经有几百个业务在使用,是滴滴主要的在线存储之一。
Fusion 的架构图如下:
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
179 浏览量
点击了解资源详情
2021-12-15 上传
179 浏览量
179 浏览量
2021-05-15 上传
122 浏览量

weixin_38667581
- 粉丝: 8
- 资源: 955
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新疆乡镇级区划图 shp格式
- jquery拖拽排序插件
- 围绕着主按钮弹次按钮特效
- spark-infotheoretic-feature-selection:该软件包包含贪婪的信息理论特征选择(FS)方法的通用实现。 该实现基于Gavin Brown提出的通用理论框架。 提供了mRMR,InfoGain,JMI和其他常用FS过滤器的实现
- 猜数字:允许用户猜数字并检查是否是计算机的实际猜测的游戏
- XX建筑装饰工程公司商业计划书(全程策划案)
- js滑动验证码插件
- pnc:用于管理,执行和跟踪构建的系统
- 天津市乡镇级区划图 shp格式
- 手写简单的Tomcat(代码源于韩顺平老师的javaweb章节)
- ch123ck.github.io
- ShinePlaceholderView
- jwtgcpgen
- XX工矿设备公司人力资源管理标准流程规范
- 四川省乡镇级区划图 shp格式
- ODE2STAB:积分微分方程组直到达到稳定(或时间结束)-matlab开发
