MapReduce编程模型解析与应用
需积分: 10 7 浏览量
更新于2024-07-23
收藏 182KB DOCX 举报
"MapReduce文档"
MapReduce是一种编程模型,由Google提出,主要用于处理和生成大规模数据集。这一模型的核心在于其两个主要函数:Map和Reduce。Map函数负责对输入的数据进行处理,通常输入是以键值对(key-value pair)的形式,Map会将这些数据转化为中间的键值对形式。Reduce函数则进一步对Map产生的中间结果进行聚合,将相同键的值进行整合,生成最终的结果。
MapReduce架构设计的目标是简化分布式计算的复杂性,让不具备分布式系统开发经验的程序员也能高效地利用大规模集群资源。它处理的主要任务包括数据的分割、在集群中的任务调度、错误处理以及节点间的通信协调。MapReduce程序可以在由普通PC机组成的大型集群上运行,适应性强,能处理PB级别的数据,并且支持数千台机器同时工作。
在Google的实际应用中,MapReduce已经被广泛应用于各种数据处理任务,如构建倒排索引、分析Web请求日志、计算网络爬虫抓取的页面数量等。程序员通过编写Map和Reduce函数,就能实现复杂的数据处理任务,而无需关注底层的并行计算细节、数据分发策略、容错机制等。
MapReduce的工作流程大致如下:
1. 输入分片:输入数据被分割成多个块,每个块会被分配到不同的计算节点。
2. Map阶段:每个节点上的Map函数并行处理其分配到的数据块,生成中间键值对。
3. 溢写与排序:中间结果先存储在本地磁盘,达到一定阈值后溢写到磁盘,并按照键进行排序。
4. Shuffle阶段:数据根据键进行分区,同一键的值被聚合到一起,准备进入Reduce阶段。
5. Reduce阶段:Reduce函数并行处理每个键的所有值,生成最终结果。
6. 输出收集:最后的结果写入到输出文件。
MapReduce的优势在于其强大的容错能力。如果某个节点故障,其上的任务可以被重新调度到其他节点执行,保证了整个计算过程的可靠性。此外,MapReduce还支持动态扩展,可以根据需要添加或减少计算节点,以适应不断变化的数据量和计算需求。
然而,MapReduce也存在一些局限性,例如不适合实时计算和低延迟响应。对于这些情况,后续出现了如Spark、Flink等更现代的计算框架,它们在保留分布式处理能力的同时,提供了更高的计算效率和更低的延迟。
MapReduce是大数据处理领域的一个里程碑,它的设计理念和实现方式对后来的分布式计算技术产生了深远影响。通过理解MapReduce的基本原理和工作流程,开发者能够更好地理解和应用分布式计算技术,解决大规模数据处理问题。
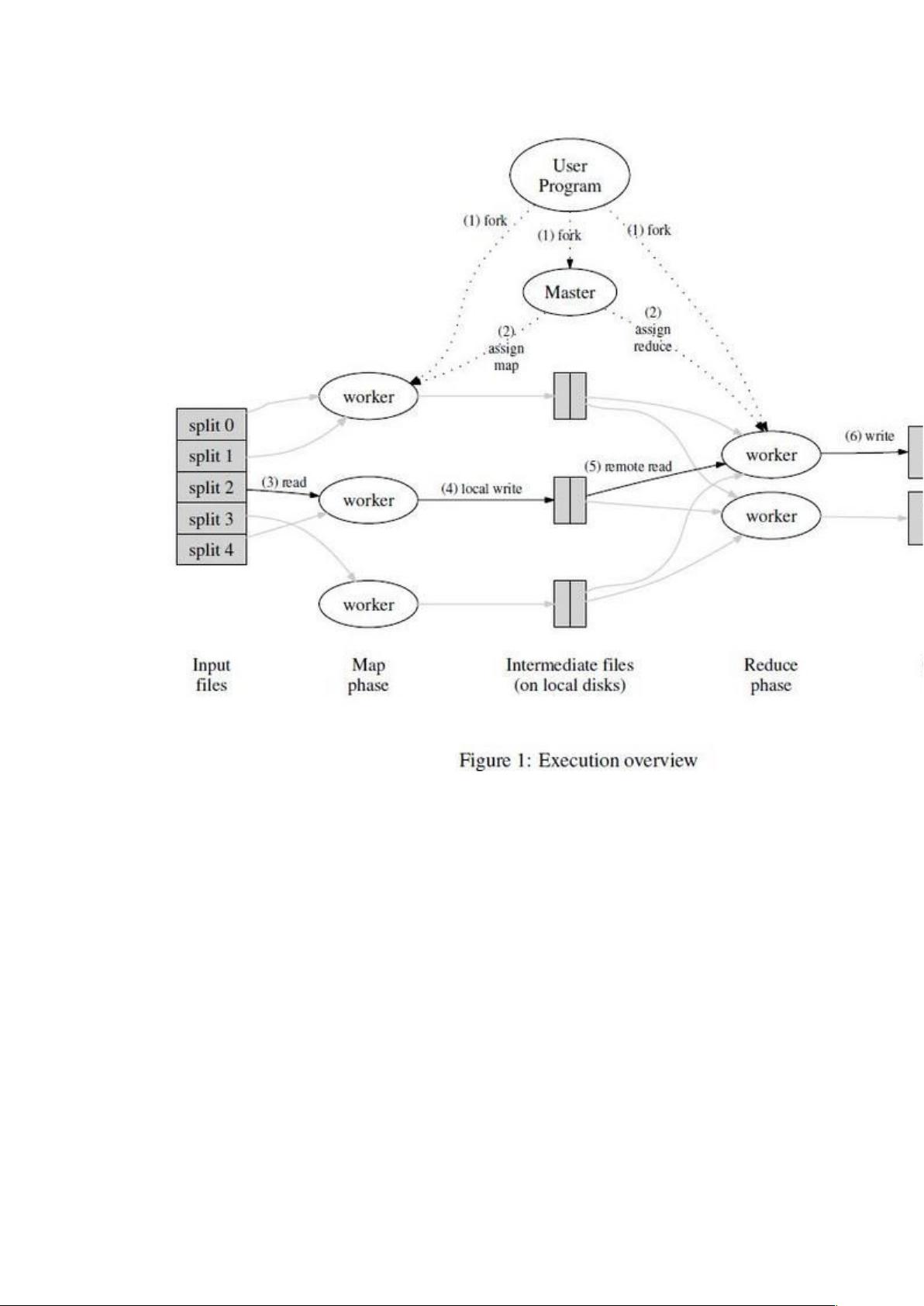
图 1 展示了我们的 MapReduce 实现中操作的全部流程。当用户调用 MapReduce 函数时,将发生下面的一系列动作(下面
的序号和图 1 中的序号一一对应):
1.用户程序首先调用的 MapReduce 库将输入文件分成 M 个数据片度,每个数据片段的大小一般从±16MB 到 64MB(可以通过
可选的参数来控制每个数据片段的大小)。然后用户程序在机群中创建大量的程序副本。±
(
alex
:
copies of the program
还
真难翻译)
2.这些程序副本中的有一个特殊的程序–master。副本中其它的程序都是 worker 程序,由 master 分配任务。有 M 个 Map
任务和 R 个 Reduce 任务将被分配,master 将一个 Map 任务或 Reduce 任务分配给一个空闲的 worker。
3.被分配了 map 任务的 worker 程序读取相关的输入数据片段,从输入的数据片段中解析出 key/value pair,然后
把 key/value pair 传递给用户自定义的 Map 函数,由 Map 函数生成并输出的中间 key/value pair,并缓存在内存中。
4.缓存中的 key/value pair 通过分区函数分成 R 个区域,之后周期性的写入到本地磁盘上。缓存的 key/value pair 在本地磁
盘上的存储位置将被回传给 master,由 master 负责把这些存储位置再传送给 Reduce worker。
5.当 Reduce worker 程序接收到 master 程序发来的数据存储位置信息后,使用 RPC 从 Map worker 所在主机的磁盘上读
取这些缓存数据。当 Reduce worker 读取了所有的中间数据后,通过对 key 进行排序后使得具有相同 key 值的数据聚合在一
起。由于许多不同的 key 值会映射到相同的 Reduce 任务上,因此必须进行排序。如果中间数据太大无法在内存中完成排序,
那么就要在外部进行排序。
6.Reduce worker 程序遍历排序后的中间数据,对于每一个唯一的中间 key 值,Reduce worker 程序将这个 key 值和它相
关的中间 value 值的集合传递给用户自定义的 Reduce 函数。Reduce 函数的输出被追加到所属分区的输出文件。
剩余17页未读,继续阅读
2011-05-13 上传
2023-04-22 上传
2023-06-13 上传
2023-10-27 上传
2023-04-20 上传
2023-09-13 上传
2023-04-05 上传
2023-09-01 上传

haoweijia1989
- 粉丝: 1
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
