大数据入门全攻略:从Hadoop到Spark Streaming
需积分: 27 132 浏览量
更新于2024-07-15
收藏 37.55MB PDF 举报
"大数据入门指南v1.0是github博主bigdata分享的一份全面的大数据学习资料,适合新手,内容包括Hadoop、Hive、Spark和Storm等核心技术,旨在帮助初学者快速掌握大数据基础知识和实战技能。"
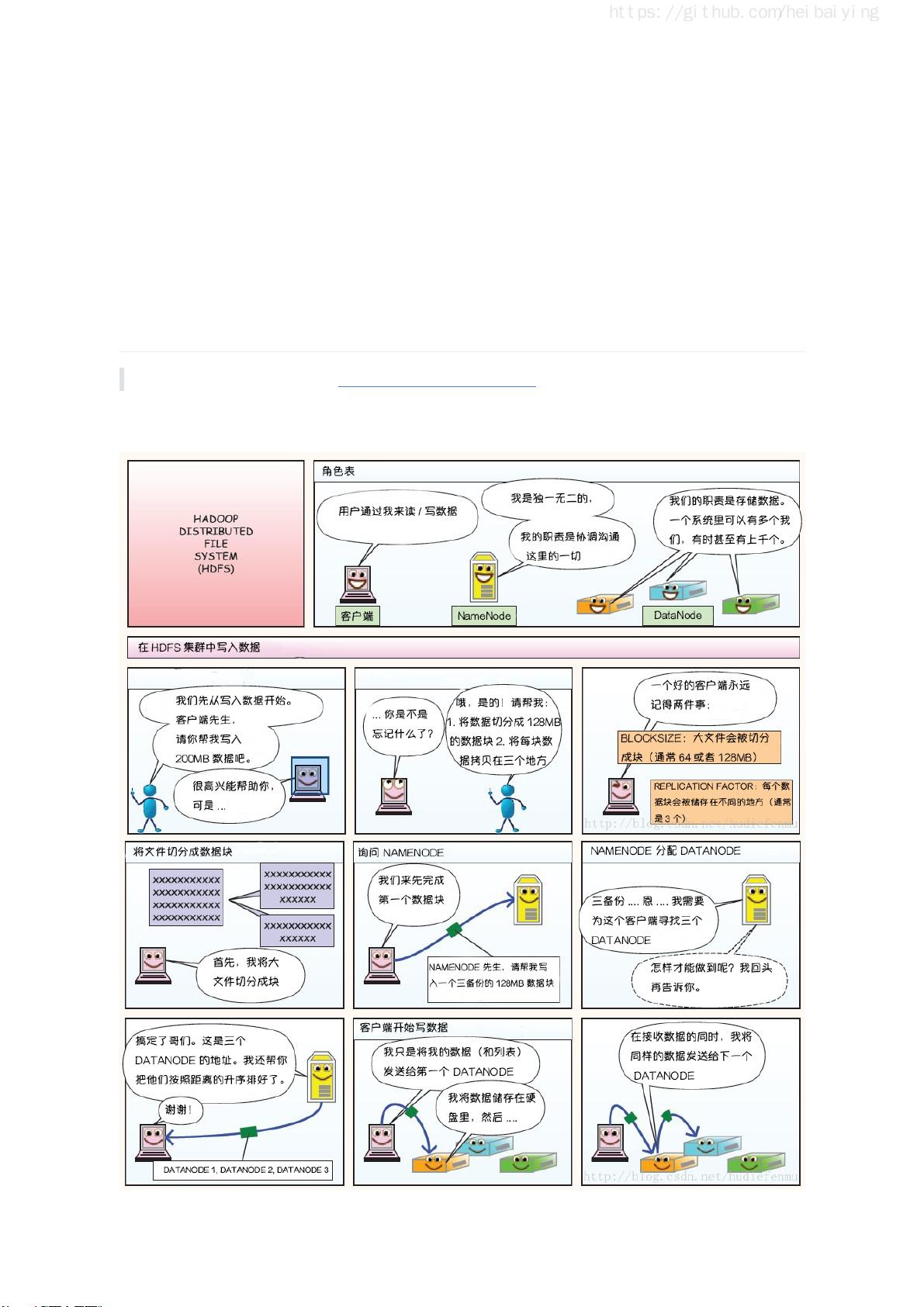
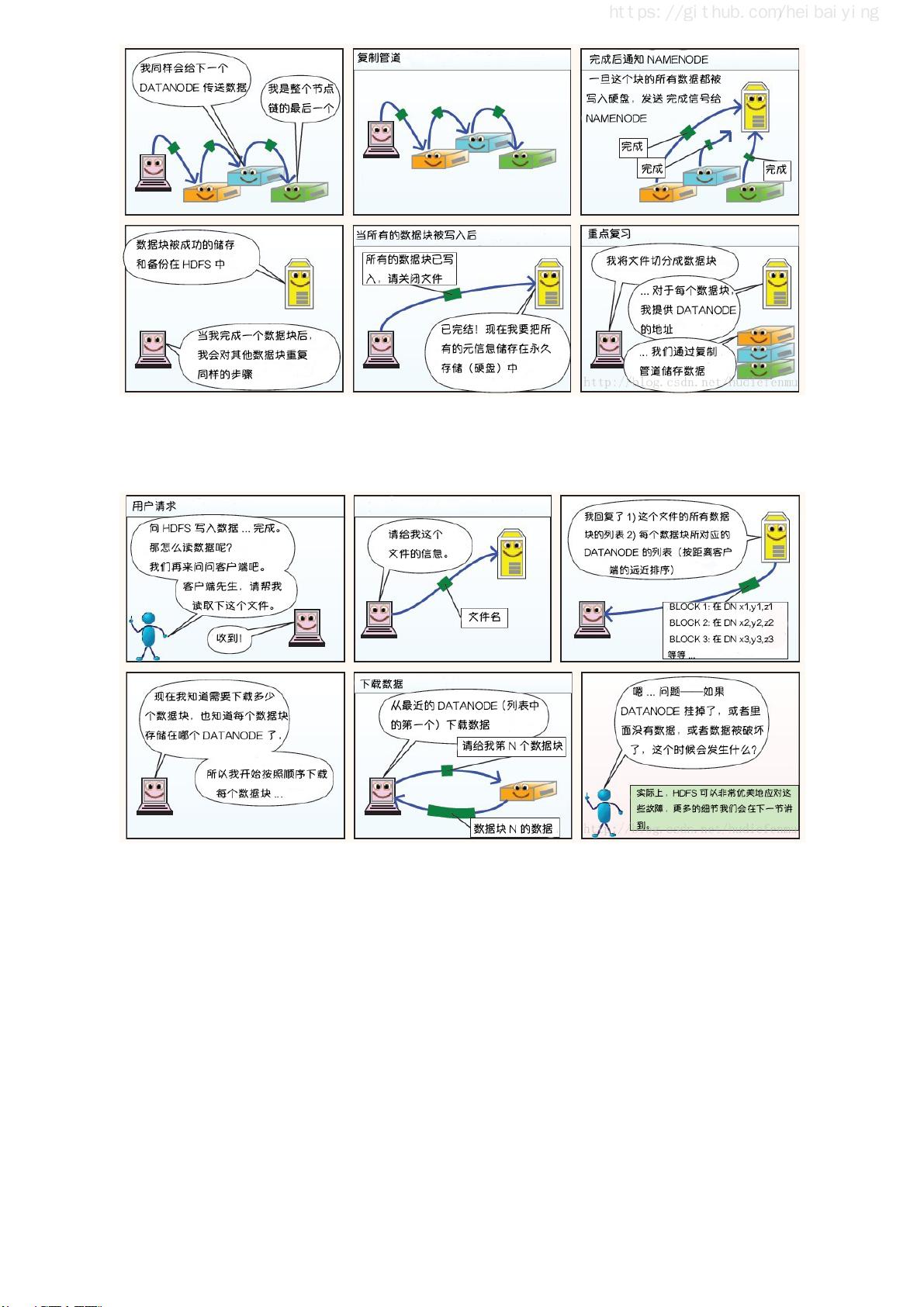
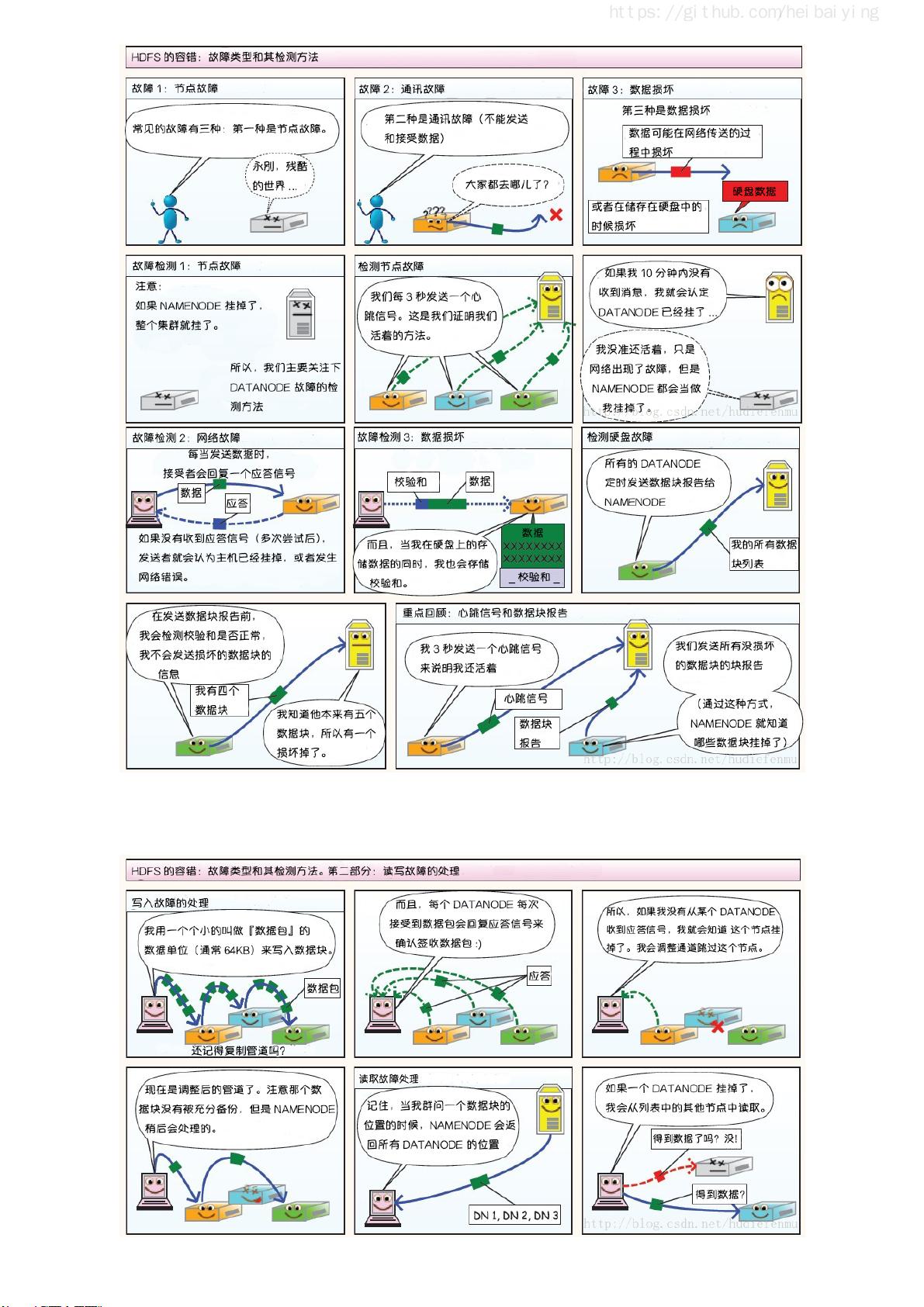
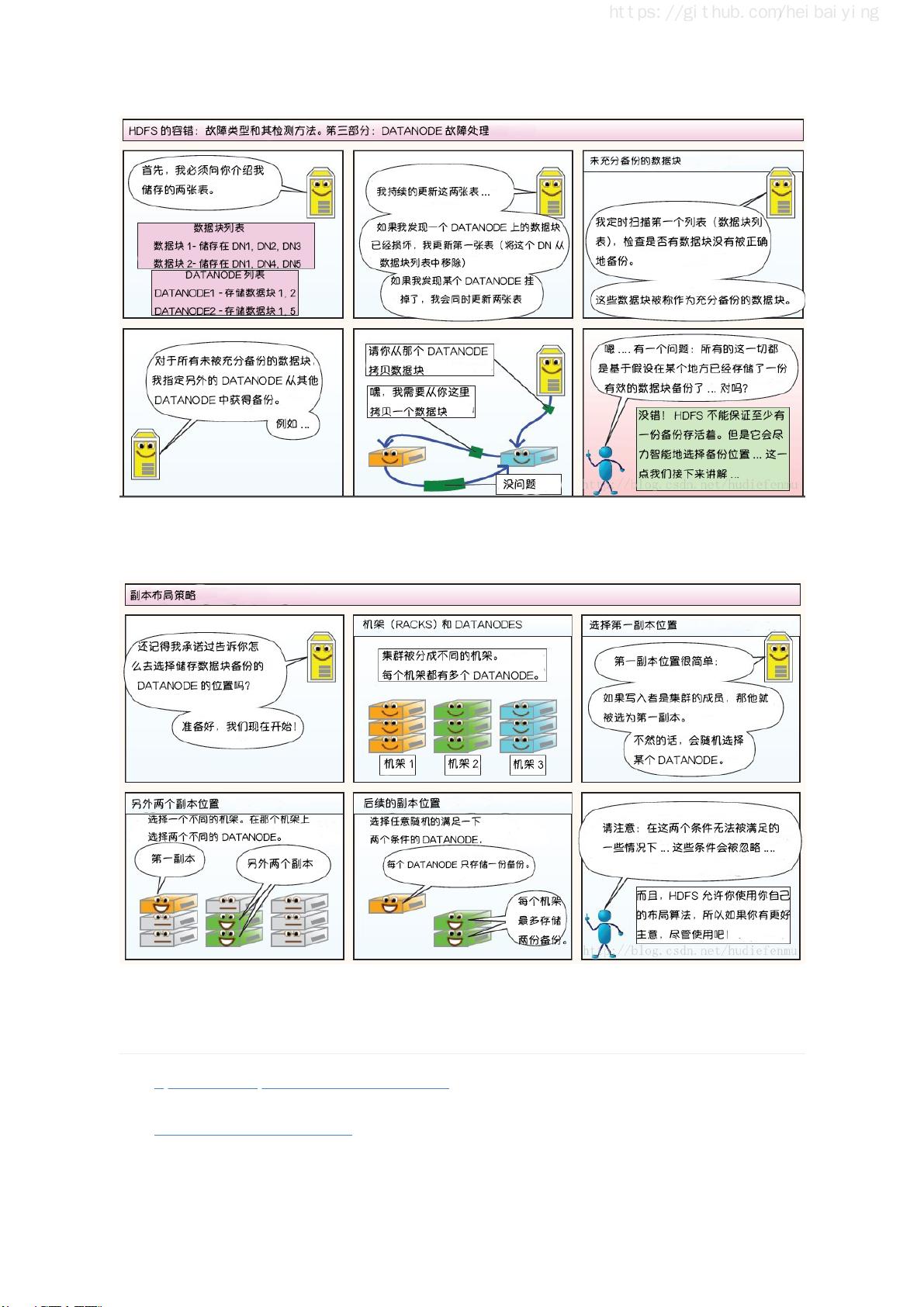
这篇指南首先介绍了大数据的学习路线和相关技术栈的思维导图,为读者提供了一个清晰的学习路径。接着,它深入到Hadoop生态系统,讲解了分布式文件存储系统HDFS,分布式计算框架MapReduce,以及集群资源管理器YARN。对于实践操作,指南详细阐述了如何在单机上搭建Hadoop伪集群环境和在多节点上构建Hadoop集群。此外,还涵盖了HDFS的常用Shell命令和Java API的使用,以及通过Zookeeper实现Hadoop高可用集群的构建。
在Hive部分,该指南介绍了Hive作为数据仓库工具的基础知识,包括其核心概念、安装部署、命令行工具如HiveCLI和Beeline的使用,以及Hive的各种数据定义(DDL)和数据操作(DML)命令。特别提到了Hive的分区表和分桶表,视图和索引,这些都是优化数据查询的重要手段。
接下来,指南转向了Spark,涵盖了SparkCore的基本概念,如RDD(弹性分布式数据集),并详细解释了RDD的各种操作。讨论了Spark的运行模式、作业提交,以及累加器和广播变量的应用。SparkSQL部分则详细介绍了DataFrame和DataSet,Structured API的使用,以及如何处理外部数据源,使用各种聚合函数和JOIN操作。此外,SparkStreaming章节讲解了实时流处理,包括基本操作,与Flume和Kafka的整合,使读者能理解如何处理实时数据流。
最后,指南简要介绍了Storm,这个实时计算框架,包括其在流处理中的作用,核心概念,以及如何搭建单机和集群环境。虽然这部分内容较简略,但足以让读者对Storm有一个初步的认识。
这份指南内容丰富,从理论到实践,由浅入深,是大数据初学者理想的入门资料,无论是个人学习还是教学使用,都能提供充分的支持。

2009-12-14 上传
2023-08-29 上传
2007-06-07 上传
2010-04-22 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

进击的Z同学
- 粉丝: 673
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- BeersManagment-AngularJS-Firebase:使用 AngularJS 和 Firebase 进行 CMS 管理 Beers,三种数据绑定方式
- Correlated
- Flat-Aar-Demo:测试Flat-Aar
- learn-rxjs-operators:Learn RxJS 中文版 (通过清晰的示例来学习 RxJS 5 操作符)
- Excel模板财 务 往 来 对 账 单.zip
- 【地产资料】XX地产 巡区工作表.zip
- flexcpp-old:用于C ++的词法扫描仪生成器
- dataSets
- 佑鸣最新暴雨强度公式 Ver2.08.zip
- Fetching-Data-Group-Project
- JoKenPo:操作系统课程1关于线程
- 香蕉:演示python程序
- Excel模板学生成绩统计表.zip
- 毕业设计&课设--毕业设计选题管理系统.zip
- sqlalchemy-challenge
- Express-file-upload-download:文件上传下载
