Apache Spark 2.4新功能详解:深度学习集成、高阶SQL操作等
120 浏览量
更新于2024-09-01
收藏 482KB PDF 举报
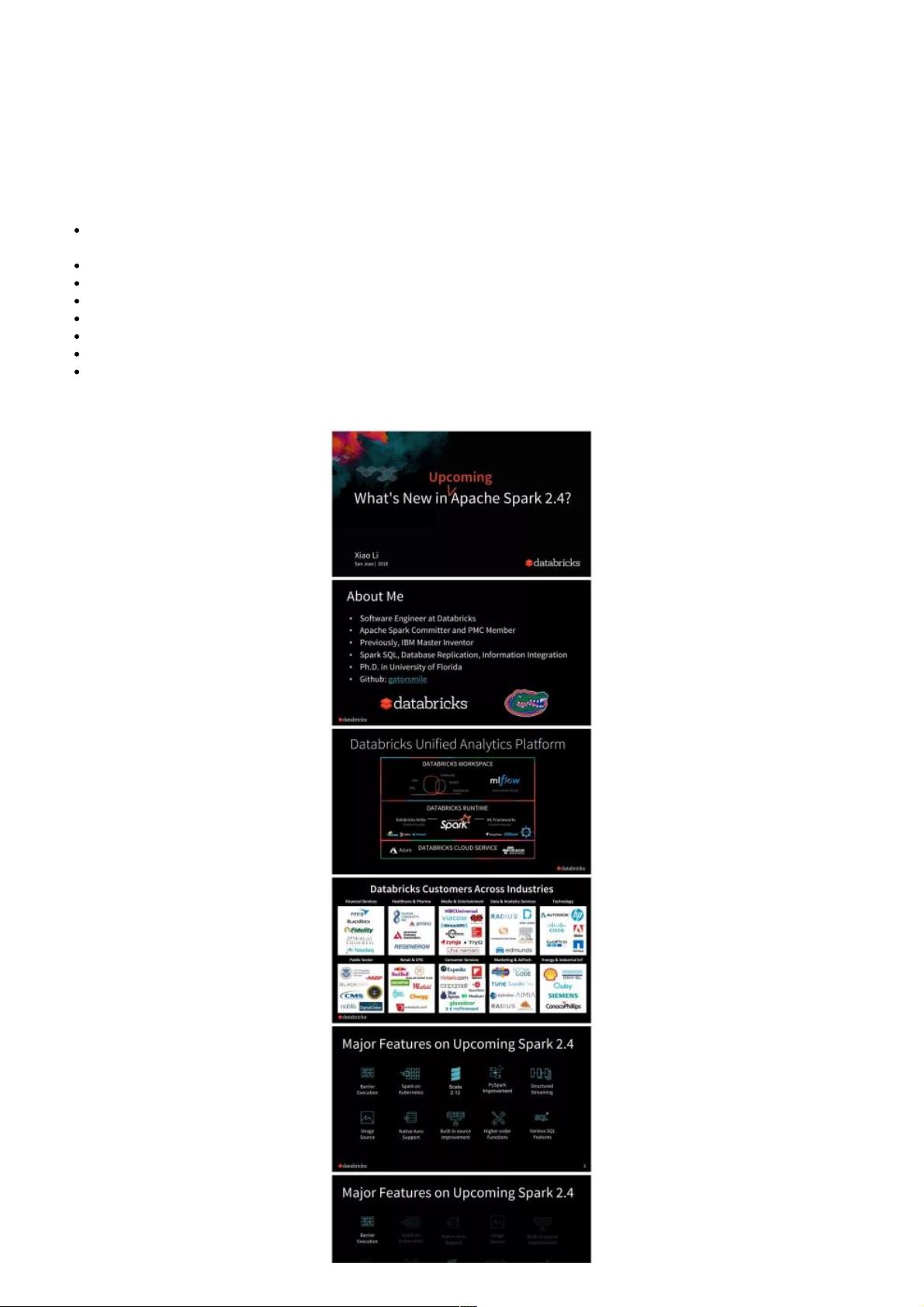
Apache Spark 2.4 是2018年即将发布的重要更新,它是Spark 2.x系列的第五个版本,旨在提供更多的功能和性能提升,以满足不断增长的数据处理需求。以下是Apache Spark 2.4的主要新特性:
1. **新的调度模型**: Barrier Scheduling是Spark 2.4的一大亮点,它引入了一种新的调度策略,允许用户更有效地整合分布式深度学习训练任务到Spark的阶段结构中。这种模型简化了分布式训练的工作流程,使得深度学习任务可以无缝地与Spark的其他计算任务协同。
2. **高级函数扩展**:Spark SQL在2.4版本中新增了35个高阶函数,增强了对数组和map数据类型的操作能力,提高了数据处理的灵活性和性能。
3. **原生AVRO数据源**:Spark 2.4引入了一个新的基于Databricks的spark-avro模块,提供了对AVRO数据格式的支持,使得处理结构化数据变得更加便捷。
4. **PySpark改进**:PySpark引入了热切评估模式(eager evaluation mode),这使得教学和调试变得更加直观和高效。此外,PySpark现在也支持在Kubernetes (K8S) 上运行,包括客户端模式,进一步扩展了其应用场景。
5. **Structured Streaming增强**:Spark 2.4为Structured Streaming提供了更多的增强特性,如连续处理过程中的有状态操作符,使得实时流处理更加稳定且功能强大。
6. **性能优化**:内置数据源(如Parquet)在2.4版本中得到了性能提升,特别是通过修剪嵌套模式(schemapruning),提高了读取速度和内存效率。
7. **Scala版本兼容**:Spark 2.4支持Scala 2.12,确保了与最新语言版本的兼容性,有助于开发者利用最新的编程特性。
以上这些新功能展示了Apache Spark 2.4在提高开发效率、处理复杂数据任务和适应现代云环境方面所做的努力。对于Spark用户来说,这是一个值得期待的升级,能帮助他们更好地应对大数据分析和机器学习挑战。如果你对某个特性有兴趣或遇到相关问题,可以通过网站留言获取更多详细信息。感谢大家对网站的支持!
2018即将推出的即将推出的Apache Spark 2.4都有哪些新功能都有哪些新功能
即将发布的 Apache Spark 2.4 版本是 2.x 系列的第五个版本。 本文对Apache Spark 2.4 的主要功能和增强功能
进行了概述,需要的朋友可以参考下
本文来自于2018年09月19日在 Adobe Systems Inc 举行的Apache Spark Meetup。
即将发布的 Apache Spark 2.4 版本是 2.x 系列的第五个版本。 本文对Apache Spark 2.4 的主要功能和增强功能进行了概述。
新的调度模型(Barrier Scheduling),使用户能够将分布式深度学习训练恰当地嵌入到 Spark 的 stage 中,以简化分布
式训练工作流程。
添加了35个高阶函数,用于在 Spark SQL 中操作数组/map。
新增一个新的基于 Databricks 的 spark-avro 模块的原生 AVRO 数据源。
PySpark 还为教学和可调试性的所有操作引入了热切的评估模式(eager evaluation mode)。
Spark on K8S 支持 PySpark 和 R ,支持客户端模式(client-mode)。
Structured Streaming 的各种增强功能。 例如,连续处理(continuous processing)中的有状态操作符。
内置数据源的各种性能改进。 例如,Parquet 嵌套模式修剪(schema pruning)。
支持 Scala 2.12。
点击 示说网 ,即可下载此PPT。
下载后可阅读完整内容,剩余6页未读,立即下载
2023-09-09 上传
2018-12-26 上传
2019-05-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-06-28 上传

weixin_38551070
- 粉丝: 3
- 资源: 900
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
