揭秘Spark作业全生命周期:Driver与DAG/TaskScheduler交互图解
116 浏览量
更新于2024-08-27
收藏 263KB PDF 举报
在Spark源码系列的第四章中,我们深入探讨了Spark作业的完整生命周期,特别是关注于DriverProgram和SparkContext的核心作用。SparkContext是应用程序的主要接口,所有的RDD操作都需要通过它来创建和管理。然而,其背后的工作机制并不为人所熟知。
首先,当SparkContext被实例化时,它会自动创建两个关键组件:DAGScheduler和TaskScheduler。DAGScheduler负责管理和调度作业的有向无环图(DAG),而TaskScheduler则在standalone模式下具体表现为TaskSchedulerImpl。在这个过程中,SparkContext会将一个SparkDeploySchedulerBackend传递给TaskSchedulerImpl的初始化方法,用于后续与Master的通信。
在TaskSchedulerImpl的启动阶段,会通过AppClient与Master进行交互。Driver程序通过调用AppClient的start方法,传递一系列参数,如执行器后端命令、SparkHome路径、应用程序描述等。这些参数包括由用户配置的maxCores(通过spark.cores.max指定)和executorMemory(通过spark.executor.memory指定)。
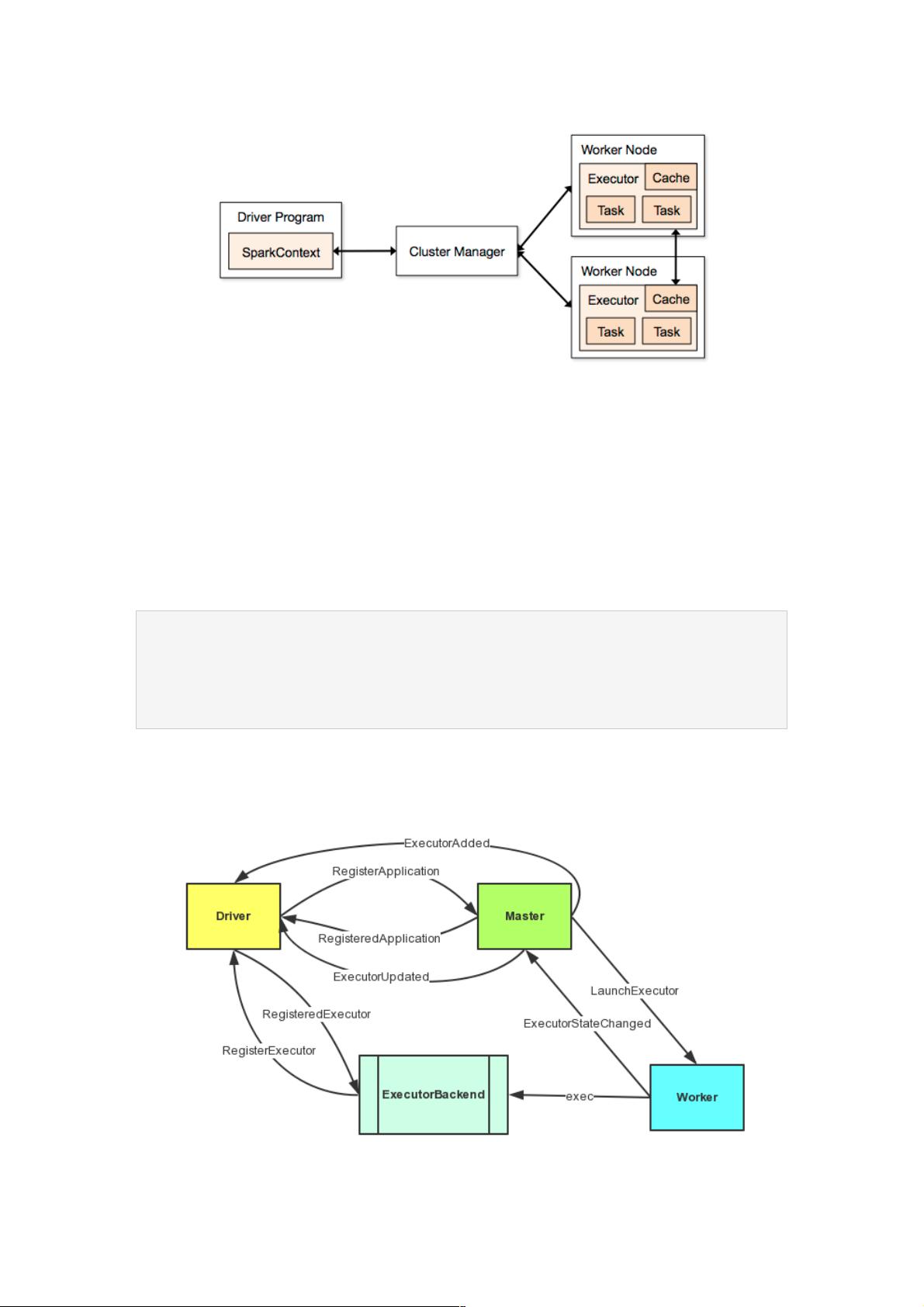
启动后的AppClient会向Master注册Application,这是作业注册的关键步骤,标志着作业的正式启动。这个过程涉及到三方通信,即Driver、AppClient和Master之间的交互。具体来说:
1. Driver通过AppClient发送应用程序描述和配置信息到Master。
2. Master收到请求后,验证信息并分配资源,如Executor实例和任务分配策略。
3. Master将任务分配给Executor,Executor执行计算任务并将结果返回给Driver或接收任务的其他节点。
图示化的作业生命周期流程清晰地展示了这个交互过程,它展示了从Driver程序启动、与Master连接、资源分配、任务调度到最终结果收集的各个环节。理解这个核心流程对于深入学习Spark的内部工作原理至关重要,有助于开发者优化性能和处理复杂的数据处理任务。
Spark源码系列(四)图解作业生命周期源码系列(四)图解作业生命周期
这一章我们探索了Spark作业的运行过程,但是没把整个过程描绘出来,好,跟着我走吧,let you know!
我们先回顾一下这个图,Driver Program是我们写的那个程序,它的核心是SparkContext,回想一下,从api的使用角
度,RDD都必须通过它来获得。
下面讲一讲它所不为认知的一面,它和其它组件是如何交互的。
Driver向Master注册Application过程
SparkContext实例化之后,在内部实例化两个很重要的类,DAGScheduler和TaskScheduler。
在standalone的模式下,TaskScheduler的实现类是TaskSchedulerImpl,在初始化它的时候SparkContext会传入一个
SparkDeploySchedulerBackend。
在SparkDeploySchedulerBackend的start方法里面启动了一个AppClient。
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend", args, sc.executorEnvs,
classPathEntries, libraryPathEntries, extraJavaOpts)
val sparkHome = sc.getSparkHome()
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
sparkHome, sc.ui.appUIAddress, sc.eventLogger.map(_.logDir))
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start()
maxCores是由参数spark.cores.max来指定的,executorMemoy是由spark.executor.memory指定的。
AppClient启动之后就会去向Master注册Applicatoin了,后面的过程我用图来表达。
上面的图中涉及到了三方通信,具体的过程如下:
1、Driver通过AppClient向Master发送了RegisterApplication消息来注册Application,Master收到消息之后会发送
RegisteredApplication通知Driver注册成功,Driver的接收类还是AppClient。
下载后可阅读完整内容,剩余3页未读,立即下载
2018-05-02 上传
2021-01-30 上传
2021-01-30 上传
2018-01-20 上传
2021-01-30 上传
2021-03-03 上传
2021-01-30 上传
2021-01-30 上传
2011-09-13 上传

weixin_38669618
- 粉丝: 7
- 资源: 913
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
