Kafka深度解析:分布式消息系统的核心原理与应用
8 浏览量
更新于2024-08-30
收藏 405KB PDF 举报
"Kafka是一个分布式发布-订阅消息系统,起源于LinkedIn,现为Apache项目。它主要处理流式数据,简化系统组网和编程复杂度。Kafka的核心组件包括Producer、Broker和Consumer,通过TCP协议进行通信。基本概念包括Topic(消息类别)、Partition(主题的物理分组)、Message(通信的基本单位)、Producer(消息生产者)、Consumer(消息消费者)和Broker(缓存代理)。Kafka的高可用性通过复制和分区策略实现,确保数据的可靠性和服务的不间断。"
Kafka是一个高度可扩展和高吞吐量的消息中间件,特别适合大规模实时数据处理。它的设计目标是提供低延迟、高并发以及可持久化的消息传递服务。Kafka通过将数据分片存储在多个Partition中,实现了水平扩展,每个Partition都是一个有序的消息队列,消息以Offset作为唯一标识。
Producer是数据的来源,它可以向Kafka的特定Topic发布消息。Producer负责将消息发送到Broker,可以选择异步或同步的方式,以优化性能。Producer可以将消息均匀地分布在多个Partition上,确保负载均衡。
Broker是Kafka的核心组件,扮演着数据存储和分发的角色。每个Broker可以承载多个Topic的Partition,并且Partition在Broker之间可以进行复制,以实现容错性和高可用性。如果一个Broker失效,其上的Partition可以被其他可用的Broker接管,保证服务不中断。
Consumer是数据的消费者,它们订阅特定的Topic并处理发布到该Topic的消息。Consumer可以属于一个消费组,同一组内的Consumer会以某种方式(如轮询或最大偏移量)共享Partition,实现负载均衡。Consumer通过 OFFSET_COMMIT 机制跟踪已处理的消息,避免重复消费。
Kafka的Topic是逻辑上的分类,可以被划分为多个Partition。Partition是物理上的存储单元,每个Partition内的消息按照插入顺序排序,并分配唯一的Offset。这种设计使得Kafka能够支持高效地读取和追加操作,而不需要随机访问。
在高可用配置方面,Kafka支持Replication,即每个Partition可以在多个Broker间复制,形成副本。当主Partition的Broker失败时,副本Partition中的一个会自动晋升为主Partition,保持服务连续性。此外,Kafka还支持动态调整Partition数量,以应对数据量的变化。
Kafka的组件关系如下:Producer将消息发送到Broker,Broker负责存储和转发消息,Consumer从Broker订阅并消费消息。Producer和Consumer通过简单的TCP协议与Broker交互,这个协议是语言无关的,允许任何语言编写的应用程序与Kafka集成。
总结来说,Kafka作为一款强大的消息中间件,不仅提供了高效的消息传输,还通过分区和复制策略确保了系统的高可用性和数据的可靠性。它在大数据处理和实时流数据场景中扮演着关键角色,简化了系统间的通信,并降低了系统的复杂度。
kafka相关相关-简介简介/原理原理/高可用配置高可用配置/组件关系组件关系
Kafka介绍介绍
简介简介
Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一个分布式的,可
划分的,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。
在大数据系统中,常常会碰到一个问题,整个大数据是由各个子系统组成,数据需要在各个子系统中高性能,低延迟的不停流
转。传统的企业消息系统并不是非常适合大规模的数据处理。为了已在同时搞定在线应用(消息)和离线应用(数据文件,日
志)Kafka就出现了。Kafka可以起到两个作用:
1.降低系统组网复杂度。
2.降低编程复杂度,各个子系统不在是相互协商接口,各个子系统类似插口插在插座上,Kafka承担高速数据总线的作用。
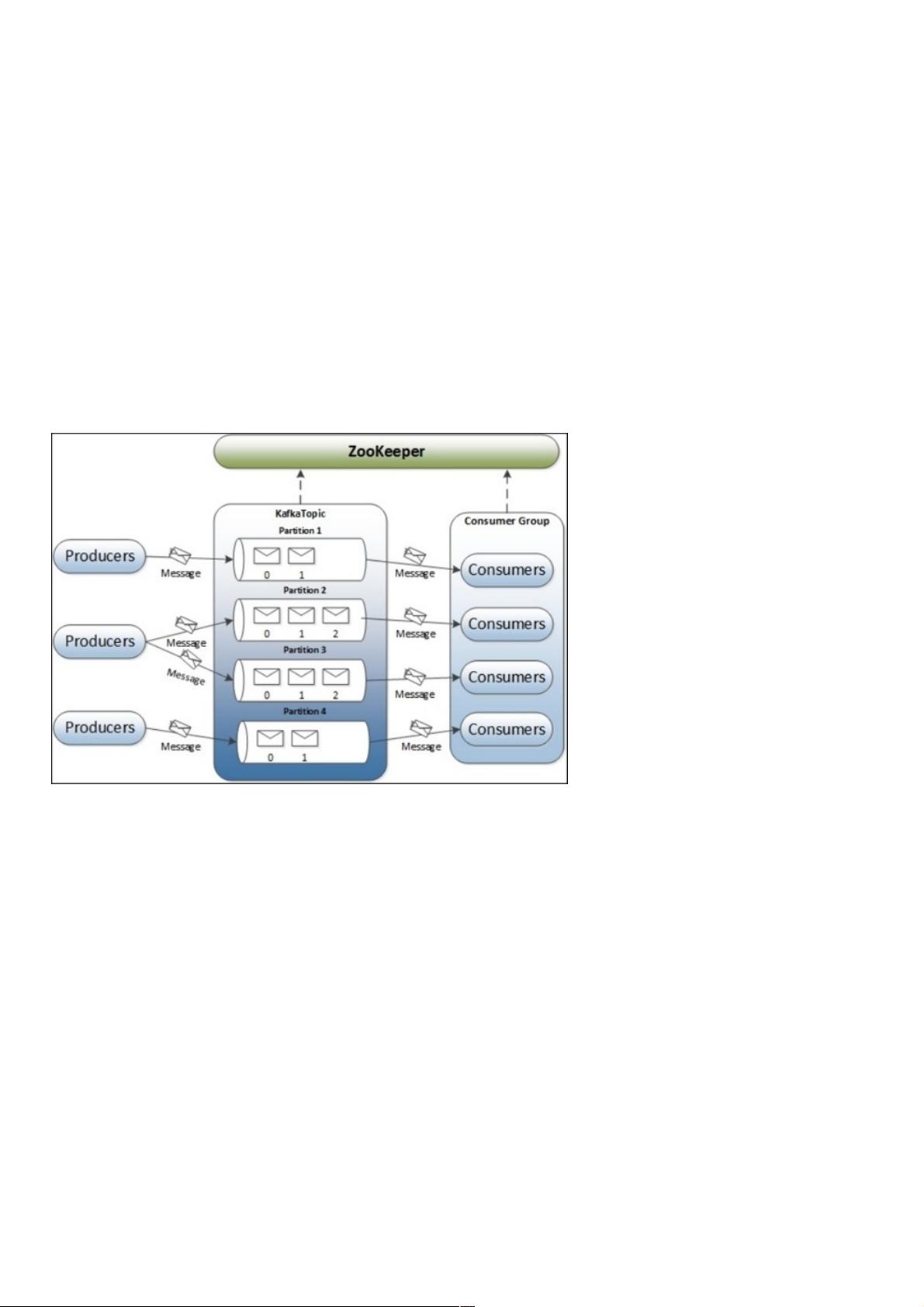
Kafka的整体架构非常简单,是显式分布式架构,producer、broker和consumer都可以有多个。Producer,consumer实现
Kafka注册的接口,数据从producer发送到broker,broker承担一个中间缓存和分发的作用。broker分发注册到系统中的
consumer。broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基于简单,
高性能,且与编程语言无关的TCP协议。整体架构图如图所示:
几个基本概念:
1.Topic:特指Kafka处理的消息源(feeds of messages)的不同分类。
2.Partition:Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都
会被分配一个有序的id(offset)。
3.Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
4.Producers:消息和数据生产者,向Kafka的一个topic发布消息的过程叫做producers。
5.Consumers:消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers。
6.Broker:缓存代理,Kafka集群中的一台或多台服务器统称为broker。
原理原理
拓扑结构
下载后可阅读完整内容,剩余7页未读,立即下载
2020-01-14 上传
2017-05-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-07-14 上传
2023-07-13 上传

weixin_38593738
- 粉丝: 0
- 资源: 924
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
