藏经阁:简单、可扩展、容错的流处理平台
需积分: 5 81 浏览量
更新于2023-11-30
收藏 1.19MB PDF 举报
The "藏经阁-Easy, scalable, Fault-tolerant S.pdf" and "Easy, scalable, Fault-tolerant Stream Processing with Structured Streaming" documents, presented by Michael Armbrust and Tathagata Das at the Spark Summit 2017 in San Francisco, provide insights into the challenges and solutions for building robust stream processing applications. The team at Databricks, who started the Spark project at UC Berkeley in 2009, aims to simplify big data processing with their Unified Analytics Platform.
Stream processing presents various complexities, including diverse data formats such as JSON, Avro, and binary, as well as the potential for dirty, late, and out-of-order data. These complexities can make building robust stream processing applications a challenging task.
The "Easy, scalable, Fault-tolerant S.pdf" and "Easy, scalable, Fault-tolerant Stream Processing with Structured Streaming" documents offer solutions to address these complexities. One approach is to use Structured Streaming, a scalable and fault-tolerant stream processing engine that provides high-level APIs for stream processing, making it easier to build reliable and efficient stream processing applications.
Overall, the documents emphasize the importance of simplifying big data processing and stream processing in order to make it more accessible and manageable for organizations and data professionals. By leveraging tools like Structured Streaming, businesses can overcome the complexities of stream processing and build robust applications to effectively process and analyze streaming data.
DataFrames,
Datasets, SQL
input = spark.readStream
.format("kafka")
.option("subscribe", "topic")
.load()
result = input
.select("device", "signal")
.where("signal > 15")
result.writeStream
.format("parquet")
.start("dest-path")
Logical
Plan
Read from
Kafka
Project
device, signal
Filter
signal > 15
Write to
Kafka
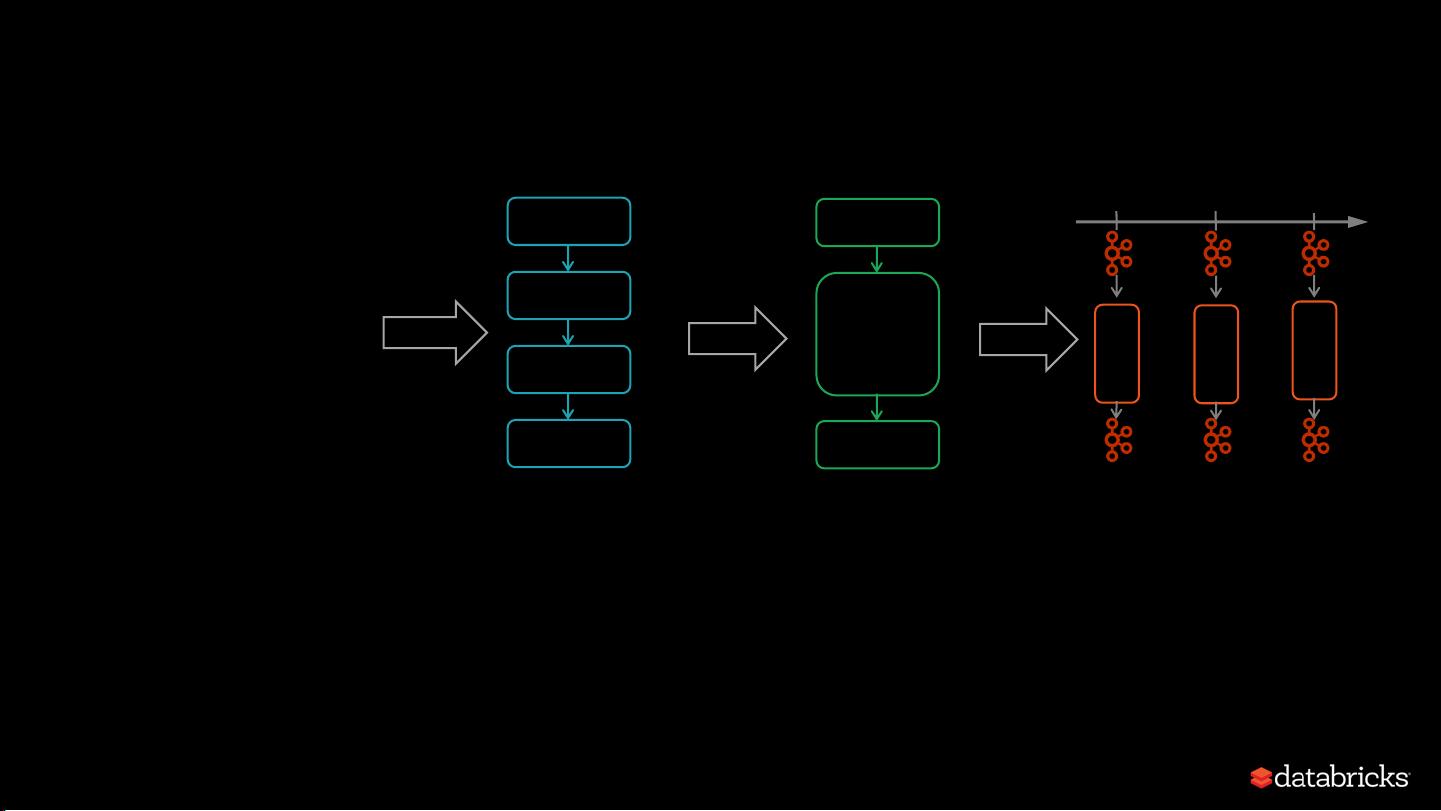
Spark automatically streamifies!
Spark SQL converts batch-like query to a series of incremental
execution plans operating on new batches of data
Series of Incremental
Execution Plans
Kafka
Source
Optimized
Operator
codegen, off-
heap, etc.
Kafka
Sink
Optimized
Physical Plan
process
new data
t = 1 t = 2
t = 3
process
new data
process
new data


剩余60页未读,继续阅读
2023-08-26 上传
2023-05-10 上传
2023-04-01 上传
2023-05-17 上传
2023-04-21 上传
2023-03-31 上传
2023-03-29 上传

weixin_40191861_zj
- 粉丝: 86
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







