TensorFlow并行读取数据深度解析
133 浏览量
更新于2024-08-31
收藏 263KB PDF 举报
本文档详细介绍了如何在TensorFlow中实现并行读取数据的过程,这对于大规模数据集在深度学习模型训练中的高效处理至关重要。以下是对整个流程的深入解析:
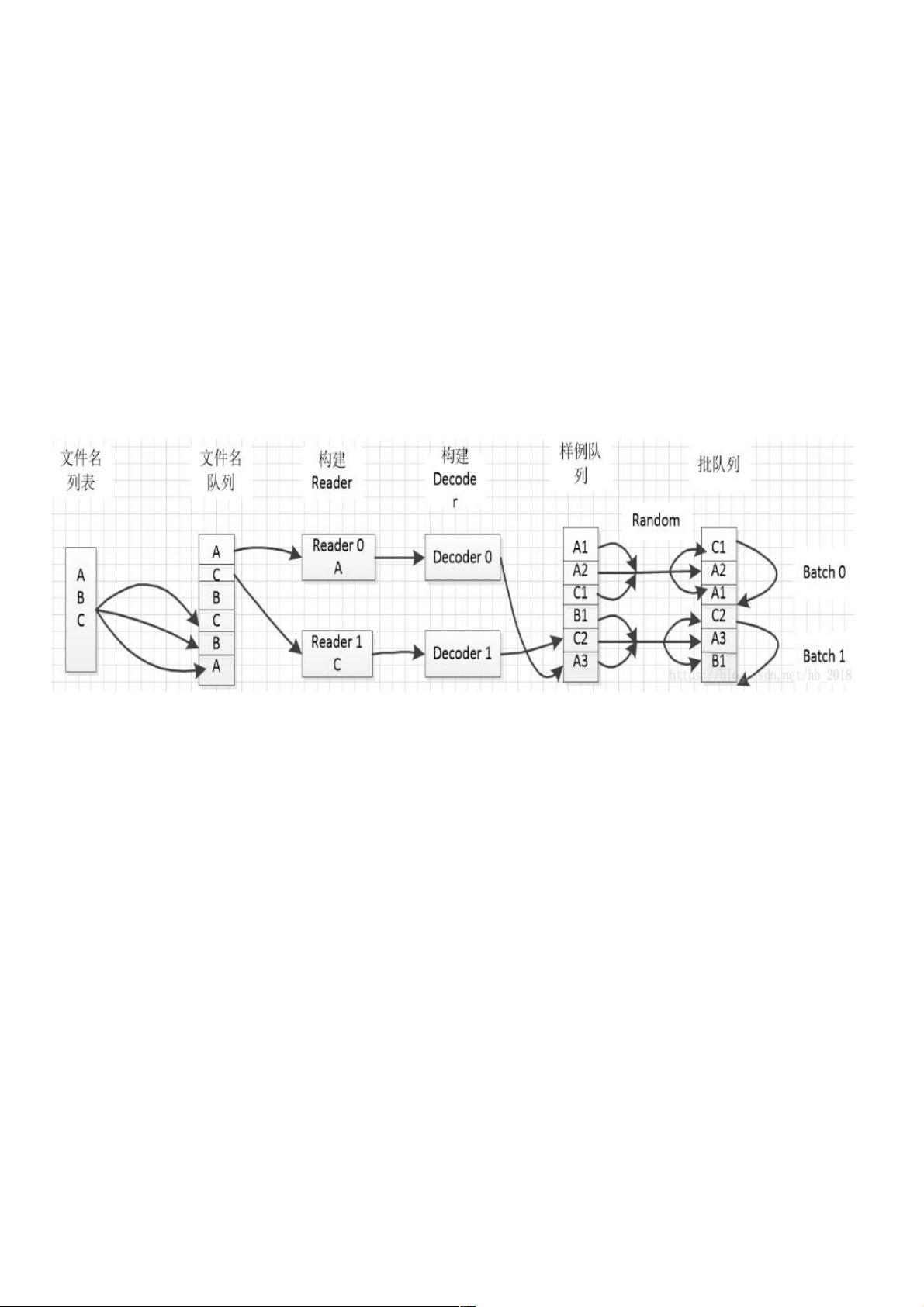
1. **文件名列表与文件名队列**:
- 文件名列表是一个包含所需数据文件名称的Python列表,可以手工创建或通过tf.train.match_filename_once动态匹配。
- 文件名队列由tf.train.string_input_producer方法创建,基于文件名列表。队列支持设置`num_epochs`(数据集遍历次数)和`shuffle`(是否随机化输入),以及容量(capacity)和共享名(shared_name)等参数。
2. **Reader和Decoder**:
- Reader负责读取数据记录,如TFRecord或CSV文件,通常与特定数据格式相关的Reader(如TFRecordReader或TextLineReader)配合使用。
- Decoder将Reader读取到的数据转换成张量形式,便于进一步处理。首先,通过调用Reader的read方法获取数据元组,然后使用Decoder将元组中的每列数据转换为张量。
3. **样例列表与批列表**:
- 样例列表是训练过程中的基本数据单元,可以直接在图中动态生成,而批列表则是将样例打包成更易于训练的批量数据。
- 批队列(batch queue)是使用tf.train.shuffle_batch或tf.train.batch函数构建,可以设定批量大小,这有助于优化内存使用和计算效率。对于训练,批列表通常是必需的,因为它允许模型一次处理多个样本,提高训练速度。
总结来说,这个流程的关键在于通过并行读取和批量处理,减少数据预处理时间,提高模型训练的效率。理解并合理配置这些组件,能够确保在大规模数据集上有效地进行TensorFlow模型的训练。同时,要注意根据实际需求调整参数,如是否进行数据随机化,以适应不同的训练策略和性能要求。
tensorflow之并行读入数据详解之并行读入数据详解
今天小编就为大家分享一篇tensorflow之并行读入数据详解,具有很好的参考价值,希望对大家有所帮助。一起
跟随小编过来看看吧
最近研究了一下并行读入数据的方式,现在将自己的理解整理如下,理解比较浅,仅供参考。
并行读入数据主要分
1. 创建文件名列表
2. 创建文件名队列
3. 创建Reader和Decoder
4. 创建样例列表
5. 创建批列表(读取时可要可不要,一般情况下样例列表可以执行读取数据操作,但是在实际训练的时候往往需要批列表来
分批进行数据的组织,提取)
其具体流程如下:
一、一、 文件名列表:文件名列表:
文件名列表是一个list类型的数据,里面的内容是需要用的数据文件名。可以使用常规的python语法入:[file1, file2]。也可以使
用tf.train.match_filename_once方法通过匹配输入。
二、文件名队列二、文件名队列
一般使用tf.train.string_input_producer的方法创建文件名队列。该方法传入的是一个文件名列表,输出的是一个先进先出队
列。在该方法中存在两个重要参数,num_epochs和shuffle。num_epochs表示列表遍历的次数,主要是由于有时候训练模型
需要反复的遍历数据集便于更新模型参数,默认情况下是None(循环遍历)。shuffle表示是否随机遍历,默认情况下是
true,表示数据会随机输入队列,当想顺序读入数据时shuffle设置为false。至于其他的capacity表示列表的容
量,shared_name表示共享时的名字。
三、三、Reader和和Decoder
Reader的功能是读取数据记录,Decoder的功能是将数据的记录转化为张量格式。在使用时需要先创建输入数据文件对应的
Reader,然后从文件名队列中取出文件名,在调用Reader.read的方法返回一个类似于(输入文件名,数据记录)的元组。最
后使用Decoder方法将每一列数据都转化为张量的形式。
下载后可阅读完整内容,剩余3页未读,立即下载
2021-05-19 上传
2020-12-20 上传
2019-05-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38730129
- 粉丝: 7
- 资源: 927
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
