SPPS Modeler建模软件入门教程:数据分析与建模技巧
需积分: 0 85 浏览量
更新于2024-07-14
收藏 1.79MB DOC 举报
"spps modeler建模软件使用简单教程"
SPPS Modeler是一款强大的统计建模工具,常用于数据分析和预测模型构建。本教程主要介绍了SPPS Modeler的一些核心功能和使用方法。
首先,模型偏差分析和回归分析是数据分析的基础。在SPPS Modeler中,可以运用最小二乘法进行回归分析,这是一种优化方法,旨在最小化预测值与实际值之间的差异。通过观察残差图,可以判断模型是否对数据有良好的拟合度。
在处理数据时,如果数据量较小,通常无需进行数据分割,可以直接进行建模。建模过程中,可以通过步进法和后退法选择关键变量。步进法是逐步引入或剔除变量,以找到最优模型;后退法则从所有变量开始,逐步删除不重要的变量,直到模型性能不再提升。
皮尔逊相关系数用于衡量两个连续变量之间的线性关系。当显著性小于0.05时(单尾检验),我们通常认为变量间存在显著相关性。在进行多重回归分析时,需要确保满足线性、独立性、正态分布和方差齐次性的假设。
逻辑回归是一种广义线性回归模型,适用于分类问题。在SPPS Modeler中,只需设置合适的类型节点即可进行逻辑回归分析。此外,Genlin节点提供了更多选择,如伽马分布和逆高斯分布,以适应不同类型的响应变量。
对于复杂问题,可以使用神经网络,如MLP(多层感知器),其具有较高的预测精度。径向基函数(RBF)也可以调整以优化模型的准确性。模型的性能可以通过观察分类误差来评估,颜色较深且分类圈较少表示分类效果较好。
当模型表现不佳时,可以考虑以下改进策略:
1. 检查数据样本变量的独立性,通过相关性分析选择合适的变量。
2. 增加数据样本容量,以提供更全面的样本信息。
3. 调整输入变量的测量级别,如将连续变量转化为离散变量,可能有助于提高分类模型的准确率。
SPPS Modeler还支持SVM(支持向量机)建模,这是一种有效的分类和回归技术。同时,它提供了两种自动聚类算法:K-means和两步聚类。K-means算法基于距离进行聚类,而两步聚类则在K-means基础上进行了改进。为了更直观地理解聚类结果,可以尝试在三维空间中展示。
关联规则分析是寻找项集之间有趣的关联或频繁模式的方法,例如市场篮子分析。在SPPS Modeler中,可以定义目标字段,以发现不同变量之间的关联关系。
SPPS Modeler提供了一系列强大的工具,涵盖了从数据预处理、建模到结果解释的整个过程,使得数据分析和建模变得更加高效和便捷。
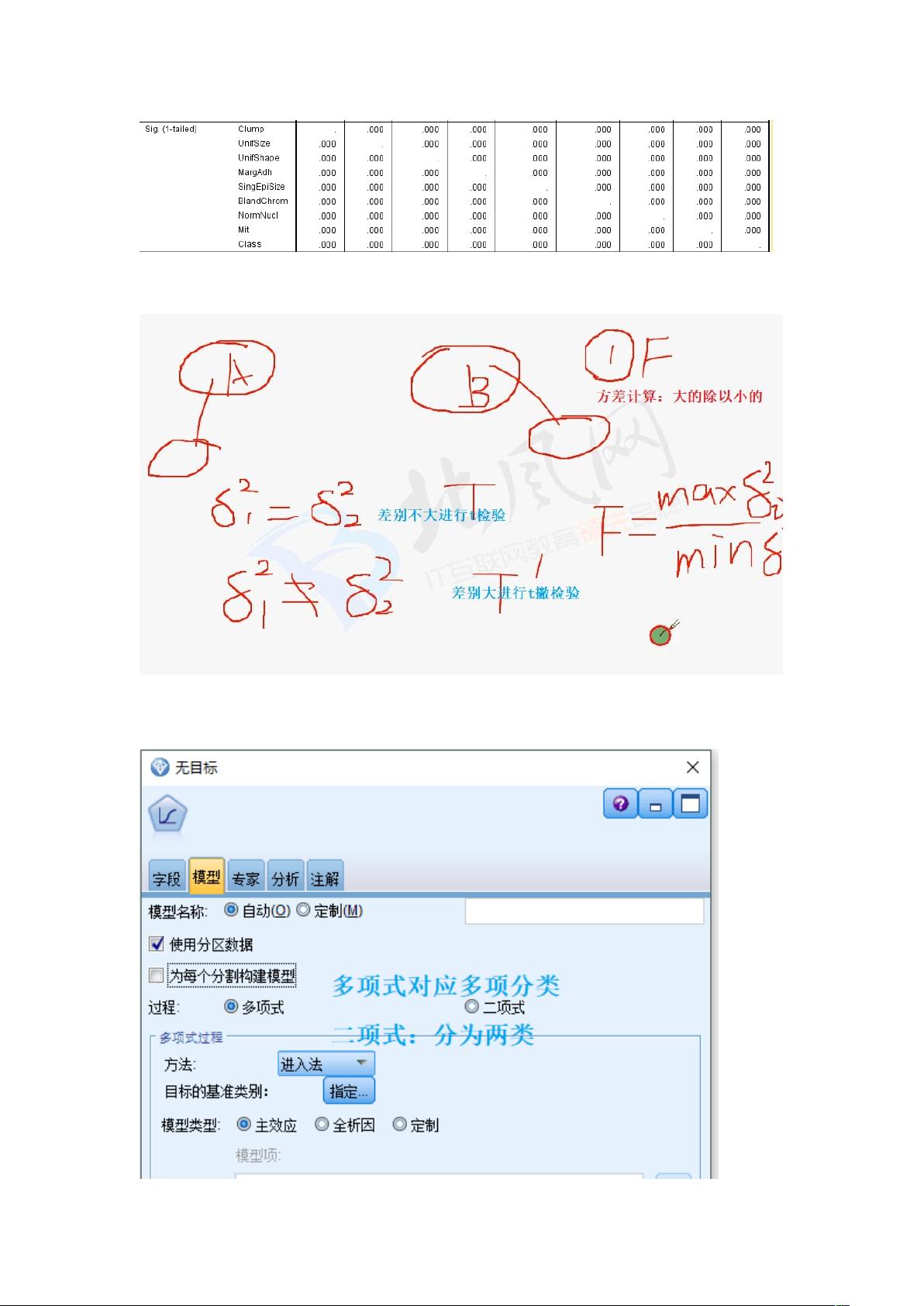
多重回归:满足线性、独立性、正态分布、方差齐次性。
逻辑回归
字段直接使用类型节点设置即可
剩余19页未读,继续阅读
2008-12-11 上传
2014-10-05 上传
2010-05-29 上传
2017-06-06 上传
2018-08-07 上传

汀、人工智能
- 粉丝: 9w+
- 资源: 410
 我的内容管理
展开
我的内容管理
展开







