Apache Flink:统一流批处理的大数据引擎
147 浏览量
更新于2024-08-29
收藏 558KB PDF 举报
Apache Flink是当前数据处理领域的重要开源项目,它专注于分布式数据流处理和批量数据处理,旨在为用户提供一个统一的平台来应对不同类型的应用需求,如流处理和批处理。Flink的核心理念是将流处理视为无限数据流,而批处理则作为有界数据流的特殊形式,这与传统的解决方案如MapReduce、Samza、Storm和Spark等有着显著区别。
Flink的设计目标是简化开发者在处理实时和批量数据时的选择,通过其FlinkRuntime,Flink提供了一致的编程模型,支持流处理API和批处理API,使得开发者无需为每种类型的任务编写单独的代码。这种统一性使得Flink在处理低延迟、Exactly-once保证的流处理任务以及高吞吐、高效处理的批处理任务时都表现出色。
在内存管理和语言实现方面,Flink与Spark有所不同。Spark倾向于使用RDD作为核心抽象,而在Flink中,尽管早期版本也依赖于类似的概念,但后续版本更加强调了内存管理和流处理的优化。Flink通过引入DataStream API和Table API,提供了更直观和高效的编程接口,支持SQL查询,进一步提升了用户体验。
在性能和扩展性方面,Flink以其低延迟、高吞吐量和容错能力闻名,特别适合实时分析和复杂事件处理。然而,与Spark相比,Flink在易用性和社区生态上可能稍显不足,特别是对于初学者来说,Spark的用户基础和丰富的生态系统可能更具吸引力。
总结来说,Apache Flink是大数据处理领域的一股重要力量,通过其独特的设计理念和统一的编程模型,为实时和批量数据处理提供了强大的工具。理解和掌握Flink,可以帮助开发人员更有效地处理大规模数据,并且能够在日益竞争激烈的数据处理市场中脱颖而出。
Flink剖析剖析
1.概述
在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷。今天给大家分享一款产品—— Apache Flink,目前,
已是 Apache 顶级项目之一。那么,接下来,笔者为大家介绍Flink 的相关内容。
2.内容
2.1 What's Flink
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink
Runtime),提供支持流处理和批处理两种类型应用的功能。现有的开源计算方案,会把流处理和批处理作为两种不同的应用
类型,因为他们它们所提供的SLA是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞
吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。
例如,实现批处理的开源方案有MapReduce、Tez、Crunch、Spark,实现流处理的开源方案有Samza、Storm。 Flink在实
现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支
持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为
有界的。基于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处
理、批处理类型应用框架的基础。
Flink 是一款新的大数据处理引擎,目标是统一不同来源的数据处理。这个目标看起来和 Spark 和类似。这两套系统都在尝试
建立一个统一的平台可以运行批量,流式,交互式,图处理,机器学习等应用。所以,Flink 和 Spark 的目标差异并不大,他
们最主要的区别在于实现的细节。
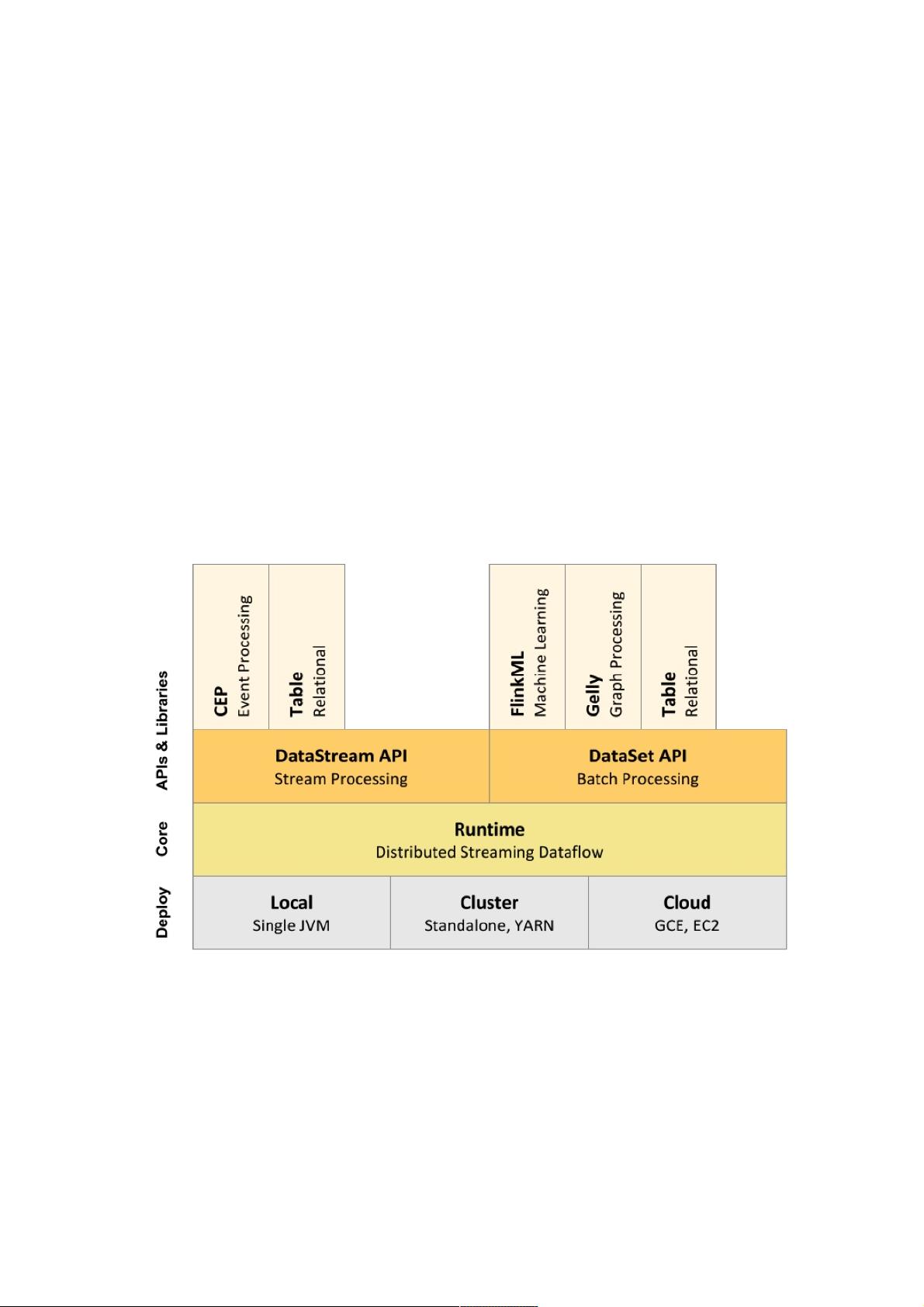
下面附上 Flink 技术栈的一个总览,如下图所示:
2.2 Compare
了解 Flink 的作用和优缺点,需要有一个参照物,这里,笔者以它与 Spark 来对比阐述。从抽象层,内存管理,语言实现,以
及 API 和 SQL 等方面来赘述。
2.2.1 Abstraction
接触过 Spark 的同学,应该比较熟悉,在处理批处理任务,可以使用 RDD,而对于流处理,可以使用 Streaming,然其世纪
还是 RDD,所以本质上还是 RDD 抽象而来。但是,在 Flink 中,批处理用 DataSet,对于流处理,有 DataStreams。思想类
似,但却有所不同:其一,DataSet 在运行时表现为 Runtime Plans,而在 Spark 中,RDD 在运行时表现为 Java Objects。
在 Flink 中有 Logical Plan ,这和 Spark 中的 DataFrames 类似。因而,在 Flink 中,若是使用这类 API ,会被优先来优化
(即:自动优化迭代)。如下图所示:
下载后可阅读完整内容,剩余6页未读,立即下载
2020-06-28 上传
2022-04-20 上传
2021-12-03 上传
点击了解资源详情
2019-04-19 上传
2019-09-18 上传
2021-03-25 上传

weixin_38551143
- 粉丝: 3
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







最新资源
- Haskell编写的C-Minus编译器针对TM架构实现
- 水电模拟工具HydroElectric开发使用Matlab
- Vue与antd结合的后台管理系统分模块打包技术解析
- 微信小游戏开发新框架:SFramework_LayaAir
- AFO算法与GA/PSO在多式联运路径优化中的应用研究
- MapleLeaflet:Ruby中构建Leaflet.js地图的简易工具
- FontForge安装包下载指南
- 个人博客系统开发:设计、安全与管理功能解析
- SmartWiki-AmazeUI风格:自定义Markdown Wiki系统
- USB虚拟串口驱动助力刻字机高效运行
- 加拿大早期种子投资通用条款清单详解
- SSM与Layui结合的汽车租赁系统
- 探索混沌与精英引导结合的鲸鱼优化算法
- Scala教程详解:代码实例与实践操作指南
- Rails 4.0+ 资产管道集成 Handlebars.js 实例解析
- Python实现Spark计算矩阵向量的余弦相似度
