MapReduce基本用法示例-自定义序列化、排序、分区、分组和topN
 已收录资源合集
已收录资源合集
需积分: 0 97 浏览量
更新于2024-01-29
收藏 590KB PDF 举报
本文介绍了MapReduce的基本用法示例,主要包括自定义序列化、排序、分区、分组和topN。在使用这些功能之前,需要确保hadoop环境正常运行。
首先,在介绍具体用法之前,作者先介绍了项目的pom.xml文件和测试数据说明。在pom.xml文件中,作者使用了一些依赖项,包括org.projectlombok和org.apache.hadoop,这些依赖项可帮助我们使用MapReduce的功能。作者还说明了测试数据的字段含义,以帮助读者理解示例的输入和输出。
接下来,作者详细介绍了自定义序列化的用法。首先,作者定义了一个名为ScoreWritable的类,用于表示MapReduce作业的输入和输出数据。该类实现了WritableComparable接口,以便在MapReduce过程中进行序列化和反序列化操作。接着,作者在MapReduce作业中使用ScoreWritable类作为数据类型,通过自定义序列化方式,实现了对数据的序列化和反序列化操作。
然后,作者讲解了排序功能的实现。在MapReduce作业中,通过自定义KeyComparator类,可以对输入数据进行排序操作。KeyComparator类继承了WritableComparator类,并重写了compare方法,实现了基于ScoreWritable类的比较逻辑。这样,在MapReduce作业中,数据可以按照指定的排序规则进行排序。
接着,作者介绍了分区功能的实现。在MapReduce作业中,可以根据需求将数据分成多个分区,以便并行处理。作者通过自定义Partitioner类,实现了对数据的分区操作。Partitioner类继承了HashPartitioner类,并重写了getPartition方法,根据ScoreWritable的某个字段值进行分区,确保具有相同字段值的数据被分到同一个分区中。
然后,作者讲解了分组功能的实现。在MapReduce中,可以根据需求将数据进行分组操作,以便在Reduce阶段进行聚合计算。作者通过自定义GroupingComparator类,实现了对数据的分组操作。GroupingComparator类继承了WritableComparator类,并重写了compare方法,根据ScoreWritable的某个字段值进行分组,确保具有相同字段值的数据被分到同一组。
最后,作者介绍了topN功能的实现。在MapReduce作业中,可以根据需求获取排名前N的数据。作者通过自定义TopNReducer类,实现了对数据的topN操作。在Reduce阶段,TopNReducer类使用PriorityQueue数据结构,对输入的数据进行排序,并保留排名前N的数据。
总结来说,本文通过具体示例介绍了MapReduce的常见基本用法,包括自定义序列化、排序、分区、分组和topN。这些功能可以帮助开发者更好地应用MapReduce进行数据处理和分析。完整的示例代码和详细的解释使得读者能够更好地理解和运用这些功能。对于想要学习和使用MapReduce的开发者来说,本文是一个很好的参考资料。
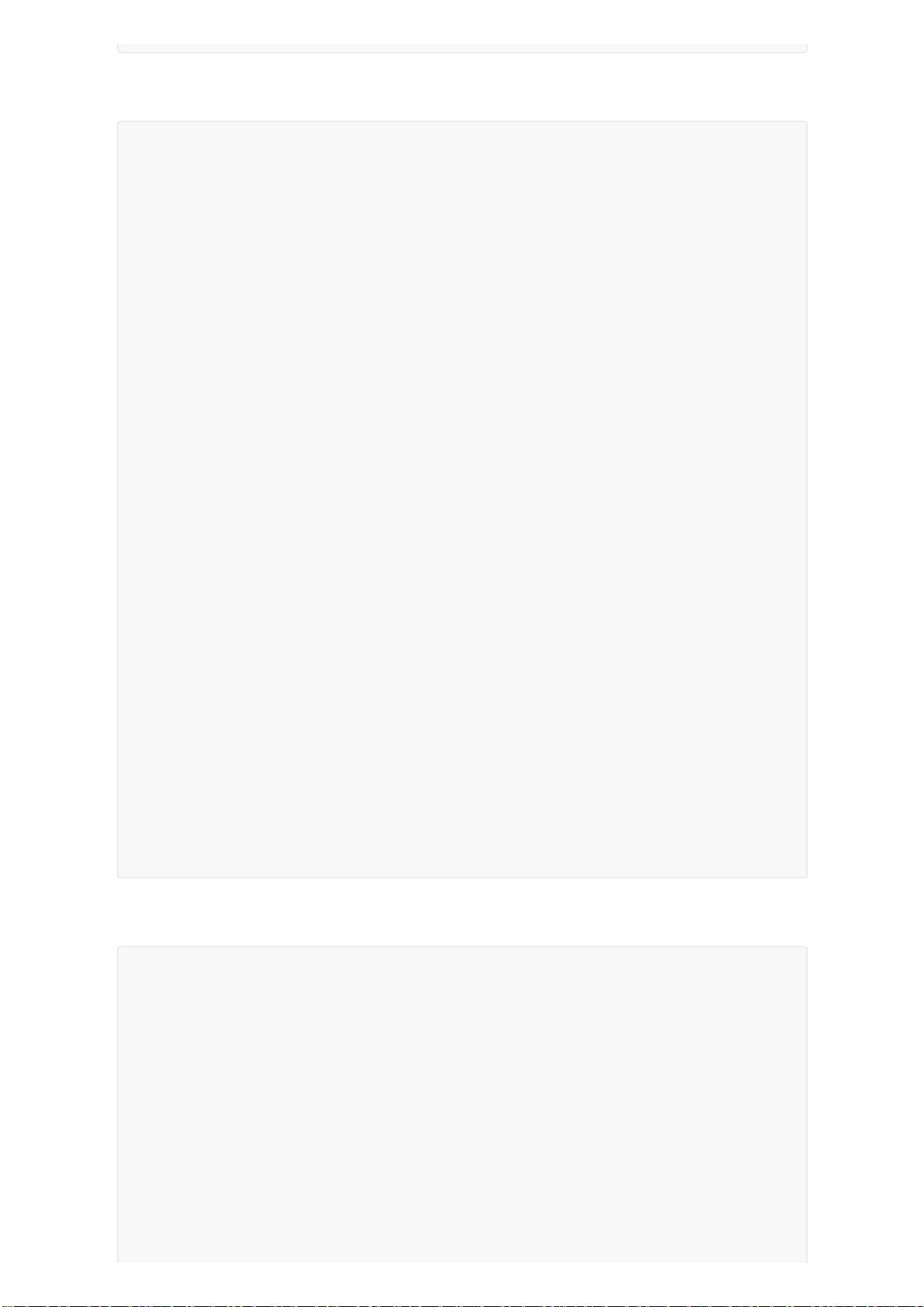
3)、Reducer
4)、Driver
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.hadoop.mr.covid.bean.CovidBean;
//KEYIN,VALUEIN,KEYOUT,VALUEOUT
public class EachStateReducer extends Reducer<Text, CovidBean, Text, CovidBean>
{
/**
* Text key map的输出key
* Iterable<CovidBean> values 根据key分组后的value,类型是map的输出value类型
* Context context 上下文
*/
@Override
protected void reduce(Text key, Iterable<CovidBean> values, Context context)
throws IOException, InterruptedException {
long cases = 0, deaths = 0;
CovidBean outValue = new CovidBean();
for (CovidBean cb : values) {
cases += cb.getCases();
deaths += cb.getDeaths();
}
outValue.setState(key.toString());
outValue.setCases(cases);
outValue.setDeaths(deaths);
context.write(key, outValue);
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.hadoop.mr.covid.bean.CovidBean;
/**
* @author alanchan
剩余25页未读,继续阅读
2021-02-01 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

一瓢一瓢的饮alanchanchn
- 粉丝: 6753
- 资源: 69
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
