数据挖掘实验报告:K均值聚类分析
需积分: 0 45 浏览量
更新于2024-08-04
收藏 302KB DOCX 举报
"该资源是一份来自北京邮电大学软件学院2016-2017学年第一学期的数据挖掘实验报告,由学生肖逸敏完成,实验内容主要涉及K均值聚类算法的应用与分析。实验目的是通过Weka工具深入理解K均值算法,并研究K值和初始簇心变化对聚类效果的影响。实验环境为Weka,数据集为‘data.xls’,最终转换为‘data.arff’格式进行操作。"
实验报告详细内容:
在数据挖掘课程中,肖逸敏同学选择了K均值算法作为项目内容,这是一种广泛应用的无监督学习方法,用于将数据集划分成多个不重叠的类别,每个类别(或簇)内部数据点间的相似性较高,而不同类别间的数据点相似性较低。K均值算法的基本流程包括初始化簇心、分配数据点至最近的簇、更新簇心以及重复该过程直至簇心不再变化或达到预设迭代次数。
在实验中,肖逸敏同学首先将Excel格式的"data.xls"文件转换为CSV,然后进一步转换为Weka可读的"arff"格式。Weka是新西兰奥克兰大学开发的一个数据挖掘软件,其中包含多种机器学习算法,包括聚类算法。在Weka的"Explorer"界面,选择"Cluster",然后选择"SimpleKMeans"算法来执行K均值聚类。
实验参数设置为:设置簇的数量(K)为6,随机种子(seed)为10,以便每次运行时都能得到一致的初始簇心位置。"ClusterMode"的"Use training set"选项表示使用训练数据集进行聚类。启动算法后,观察到的"Clusterer output"包含了算法运行的相关信息,如迭代次数、簇心坐标等。
实验结果部分,虽然具体聚类结果没有在提供的信息中给出,但通常会包括每个数据点所属的簇、各簇的数据点数量、簇心位置以及可能的可视化结果。这些结果可以与真实数据分布对比,评估聚类的准确性。同时,肖逸敏还应尝试改变K值和簇心初始化策略,观察这些变化如何影响聚类结果和准确度,这有助于理解算法的敏感性和优化策略。
通过这样的实验,学生不仅能够掌握K均值算法的实现,还能深入探究其内在机制,如K值的选择对聚类效果的影响,以及初始化策略如何影响收敛速度和最终聚类质量。这些知识对于理解和应用数据挖掘技术至关重要。
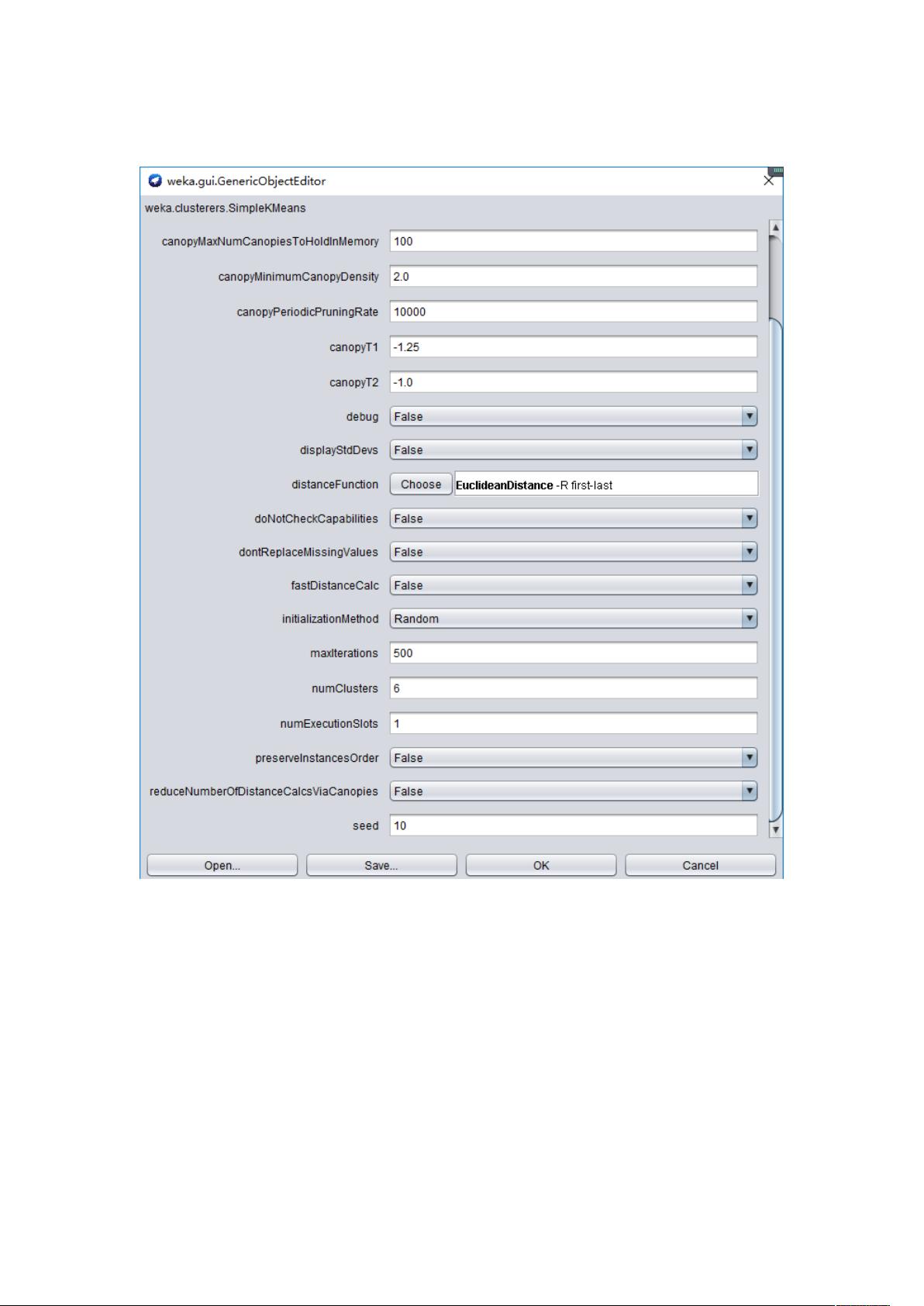
数,用来得到 K 均值算法中第一次给出的 K 个簇中心的位置。我们不妨暂时让
它就为 10。
选中“ClusterMode”的“Usetrainingset”,点击“Start”按钮,观察右边
“Clustereroutput”给出的聚类结果如下:
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-10-03 上传
2023-12-23 上传
2021-06-09 上传
2023-08-01 上传

郭逗
- 粉丝: 33
- 资源: 318
 我的内容管理
展开
我的内容管理
展开







最新资源
- 最新收集JDK1.5.0命令大全.txt
- designing embedded systems with pic microcontrollers
- programming in ada95
- pretous元件清单
- C++程序员的python使用手册 PDF格式 英汉对照版
- sun云计算的相关资料
- 浅谈Java串行端口技术协议
- learning python 3nd Edition 英文版 PDF格式
- vc6.0创建Symbian工程
- linux常用指令大全
- oracle9i10g编程艺术
- java作业house游戏 txt文档 经过编译
- C++ Primer 3rd Edition 中文完美版
- Test Director 8.0使用手册
- Software Requirements Specification
- 数字电子技术教材电子版
