K-means算法与层次聚类解析
需积分: 9 49 浏览量
更新于2024-07-20
收藏 295KB PDF 举报
"K-means算法及其与层次聚类的比较"
K-means算法是一种广泛应用的无监督学习方法,主要用于数据的聚类分析。该算法旨在将数据集分割成K个不同的簇,使得每个数据点尽可能地属于其所属簇的中心,并且同一簇内的数据点彼此相似,而不同簇之间的数据点差异较大。K-means算法的核心思想是迭代优化,通过不断地调整簇的中心和数据点的归属来最小化簇内的平方误差和。
在K-means算法的初始阶段,需要随机选择K个数据点作为初始聚类中心。然后,对于每一个数据点,将其分配到最近的聚类中心所在的簇。接着,重新计算每个簇的中心,通常是簇内所有数据点的均值。这个过程不断重复,直到聚类中心不再显著变化或者达到预设的最大迭代次数为止。K-means的一个显著优点是其简单性和效率,尤其适用于大数据集。然而,它也有一些局限性,如对初始聚类中心敏感,容易陷入局部最优,以及对异常值和非凸形状簇的处理能力较弱。
与K-means相比,层次聚类(Hierarchical Clustering)提供了另一种聚类策略。层次聚类可以分为两种类型:凝聚型(Agglomerative)和分裂型(Divisive)。在凝聚型层次聚类中,数据点最初被视为独立的簇,然后逐步合并成更大的簇,直到满足某个终止条件,如达到特定的簇数或簇间的距离阈值。相反,分裂型层次聚类从包含所有数据点的大簇开始,然后逐步分裂成较小的簇。层次聚类的优点在于它可以提供一种树状结构(Dendrogram),直观展示簇间的层级关系,但它的计算复杂度通常高于K-means。
在某些情况下,数据可能可以被有效地用高斯混合模型(Gaussian Mixture Model, GMM)进行建模,特别是在处理连续分布的数据时。GMM是一种概率模型,由多个高斯分布组成,可以用于描述数据的多峰分布。然而,K-means作为一个简单且快速的非概率方法,可能更适用于那些不希望处理复杂概率模型或者计算资源有限的场合。
在数据压缩领域,K-means等聚类方法也可以应用于损失y压缩。通过对数据进行聚类,可以将相似的数据点归纳为一个代表性的点,从而减少数据的表示维度,实现数据的压缩。这种方法虽然会丢失一些细节信息,但在保留主要特征的同时,能够大幅度减少数据存储和传输的需求。
总结来说,K-means算法和层次聚类是两种常见的数据聚类技术,各有优缺点。选择哪种方法取决于具体的应用场景、数据特性以及对效率和精度的需求。同时,这些聚类方法在数据压缩、模式识别、市场分割等领域有广泛的应用。
5
Copyright © 2001, 2004, Andrew W. Moore K-means and Hierarchical Clustering: Slide 9
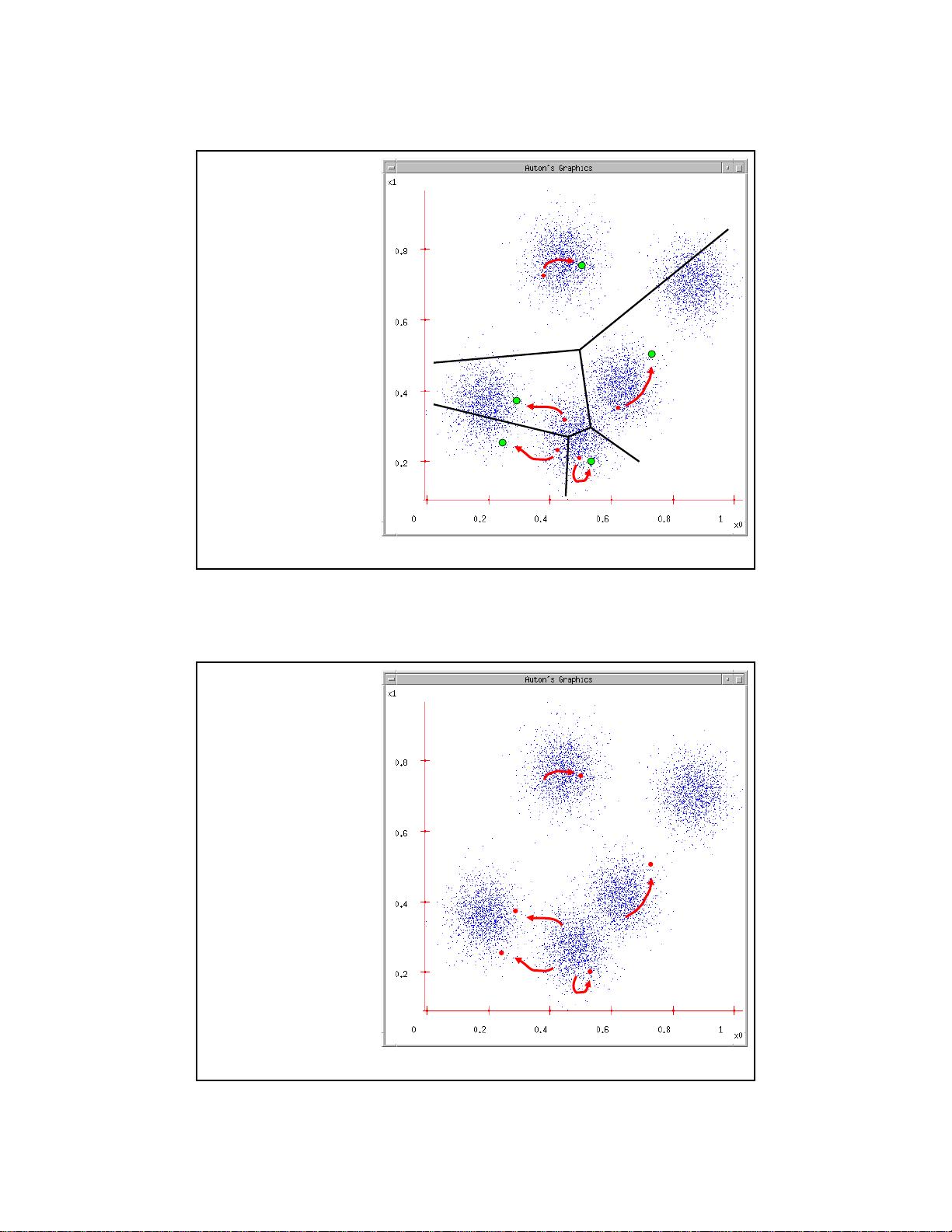
K-means
1. Ask user how many
clusters they’d like.
(e.g. k=5)
2. Randomly guess k
cluster Center
locations
3. Each datapoint finds
out which Center it’s
closest to.
4. Each Center finds
the centroid of the
points it owns
Copyright © 2001, 2004, Andrew W. Moore K-means and Hierarchical Clustering: Slide 10
K-means
1. Ask user how many
clusters they’d like.
(e.g. k=5)
2. Randomly guess k
cluster Center
locations
3. Each datapoint finds
out which Center it’s
closest to.
4. Each Center finds
the centroid of the
points it owns…
5. …and jumps there
6. …Repeat until
terminated!
剩余23页未读,继续阅读
2023-09-28 上传
2012-05-06 上传
2018-01-29 上传
2011-01-06 上传
2023-07-27 上传
2024-11-29 上传
2024-11-29 上传
2024-11-29 上传
2024-11-29 上传

s64805595
- 粉丝: 2
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
