
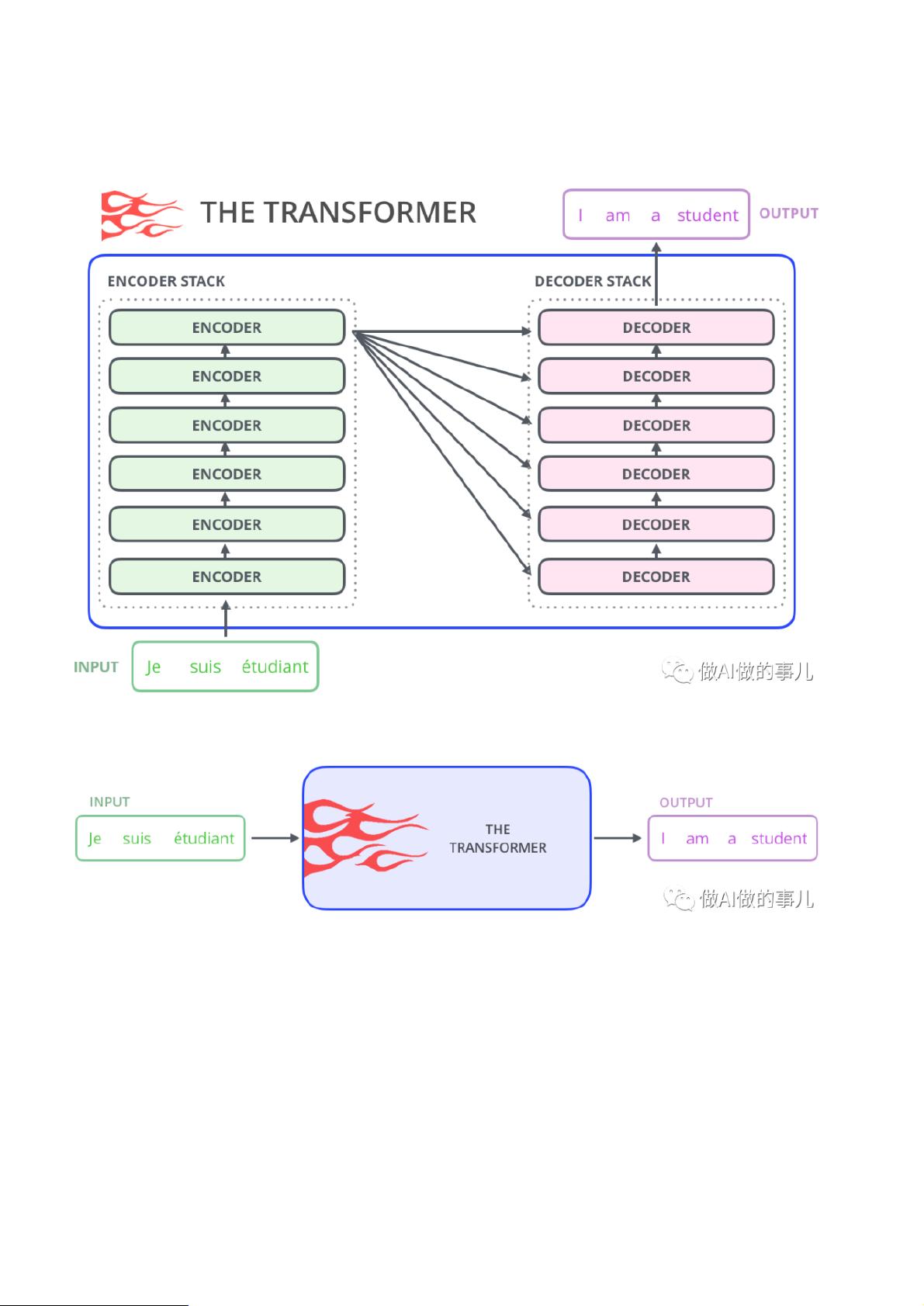
经过训练后,这个最初的Transformer模型在包括翻译准确度、英语成分句法分
析等各项评分上都达到了业内第一,成为当时最先进的大型语言模型(Large
Language Model, LLM),其最常见使用场景就是输入法和机器翻译。
Transformer模型自诞生的那一刻起,就深刻地影响了接下来几年人工智能领域
的发展轨迹。
因为谷歌大脑团队在论文中提供了模型的架构,任何人都可以用其搭建类似架构
的模型来并结合自己手上的数据进行训练。
于是,Transformer就像其另一个霸气的名字“变形金刚”一样,被更多人研究,
并不断地变化。


剩余63页未读,继续阅读

weixin_42617595
- 粉丝: 0
- 资源: 5
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- BSC绩效考核指标汇总 (2).docx
- BSC资料.pdf
- BSC绩效考核指标汇总 (3).pdf
- C5000W常见问题解决方案.docx
- BSC概念 (2).pdf
- ESP8266智能家居.docx
- ESP8266智能家居.pdf
- BSC概念 HR猫猫.docx
- C5000W常见问题解决方案.pdf
- BSC模板:关键绩效指标示例(财务、客户、内部运营、学习成长四个方面).docx
- BSC概念.docx
- BSC模板:关键绩效指标示例(财务、客户、内部运营、学习成长四个方面).pdf
- BSC概念.pdf
- 各种智能算法的总结汇总.docx
- BSC概念 HR猫猫.pdf
- bsc概念hr猫猫.pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


