"该资源是关于使用CAMO的The Unscrambler软件进行数据分析的演示文稿,由Ranjit Viswanathan(CAMO Software India Pvt Ltd的亚洲太平洋地区销售经理)在长春应用化学研究所进行讲解。主要内容涉及如何处理JCAMP-DX格式的光谱数据(作为输入变量X)和Excel表格中的蛋白质与脂肪百分比数据(作为输出变量Y),以及如何利用这些数据预测未知样本S74的蛋白质和脂肪含量。文稿概述了分析的整个步骤,包括数据一致性检查、数据导入、设置分析、初步分析、构建回归模型、优化模型、保存模型以及进行预测等环节。"
详细知识点:
1. 数据一致性检查:在进行数据分析之前,确保所有数据源(如JCAMP-DX文件和Excel表)的一致性至关重要。这可能包括单位、数据格式、缺失值处理等方面的检查,以避免后续分析中的错误。
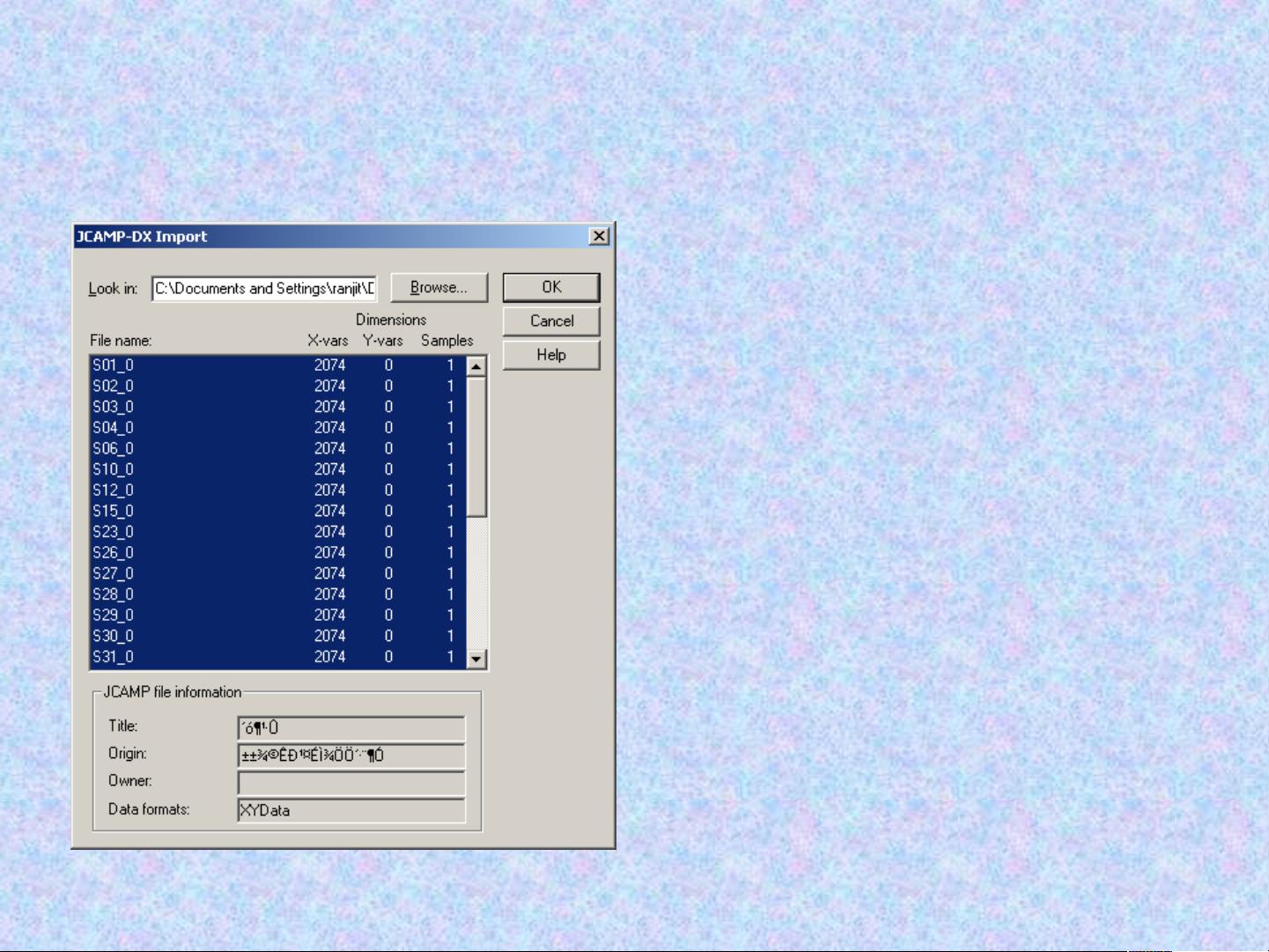
2. JCAMP-DX文件:这是一种标准格式,用于存储光谱数据,如红外、核磁共振、质谱等。在这种情况下,它们被假设为光谱读数,用作输入变量,帮助解释样品的特性。
3. Excel表:Excel表格常用于存储结构化数据,如蛋白质和脂肪的百分比,这些作为输出变量,是分析的目标。它们将用于训练模型并评估预测性能。
4. 输入(X)与输出(Y)变量:在数据分析中,输入变量通常是影响结果的因素,而输出变量是需要预测的结果。在这个案例中,JCAMP-DX文件中的光谱数据是输入,Excel表中的蛋白质和脂肪百分比是输出。
5. 未知样本预测:S74样本没有蛋白质和脂肪的数据,因此目标是建立一个模型,通过输入变量来预测这些缺失的数值。
6. The Unscrambler软件:这是一个强大的多变量数据分析工具,广泛用于化学、生物和工程等领域,能执行主成分分析(PCA)、偏最小二乘回归(PLS)、多元线性回归等多种统计分析方法。
7. 分析步骤:
- 数据导入:将不同来源的数据整合到The Unscrambler环境中。
- 设置数据:配置数据集,可能包括标准化、归一化或缺失值处理。
- 初步分析:使用PCA等方法探索数据结构,发现潜在的模式和趋势。
- 构建回归模型:选择合适的算法(如PLS),训练模型以连接输入和输出变量。
- 模型优化:通过交叉验证、调整参数等方式提高模型预测准确性。
- 保存模型:保存模型以便将来使用或应用于新的未知样本。
- 预测:使用模型对未知样本S74的蛋白质和脂肪百分比进行预测。
- 预测选项:可能包括敏感性分析、误差分析等,以评估模型的稳定性和预测范围。
8. 回归模型:在数据分析中,回归模型用来预测连续的输出变量,如蛋白质和脂肪的百分比。PLS回归是一种常用的工具,尤其适用于具有多重共线性的高维数据。
通过以上步骤,该演示文稿详细阐述了如何使用The Unscrambler进行数据分析,旨在解决特定的预测问题,即预测未知样本的蛋白质和脂肪含量。




 我的内容管理
展开
我的内容管理
展开









