淘宝海量数据技术挑战与实践
"淘宝 海量 数据技术 - 赵昆.pdf"
本文主要探讨了淘宝在海量数据技术方面所面临的挑战、技术应用以及数据产品的实践。作者赵昆是淘宝数据平台与产品部的数据产品经理,他强调了对数据产品理解的一些常见误区,并介绍了淘宝大数据处理的关键技术和应用场景。
首先,赵昆指出了一些关于淘宝数据处理的误区。许多人认为淘宝仅仅是一家电子商务公司,但实际上,它在数据处理和分析上具有极高的需求。误区包括:数据量大就一定有价值,而忽视了数据质量;认为大型商业产品或开源产品能解决所有问题,如Oracle、GreenPlum、Hadoop等,但其实每种方案都有其适用场景;并且,有些人低估了数据展现的重要性。
接着,赵昆阐述了淘宝数据的特点:数据量巨大,内容多样,包括日志、文本、关系型等多种类型的数据;同时,数据维度丰富,覆盖多个行业和品牌,但源数据质量参差不齐,存在非法交易和恶意评价等问题。这些特点给数据处理带来了巨大挑战,例如每天需要处理900TB的数据,月增1.5P,日增0.06P,高峰时处理速度达到30G/s。
面对挑战,淘宝采用了分布式存储计算、实时计算、实时流处理和数据可视化等技术。分布式存储计算是处理海量数据的基础,通过将数据分布在多台服务器上,提高处理能力。实时计算则允许快速响应业务需求,提供即时的数据分析。实时流处理技术用于处理持续产生的数据流,确保数据的时效性。数据可视化则有助于将复杂的数据转化为易于理解的图形,支持决策制定。
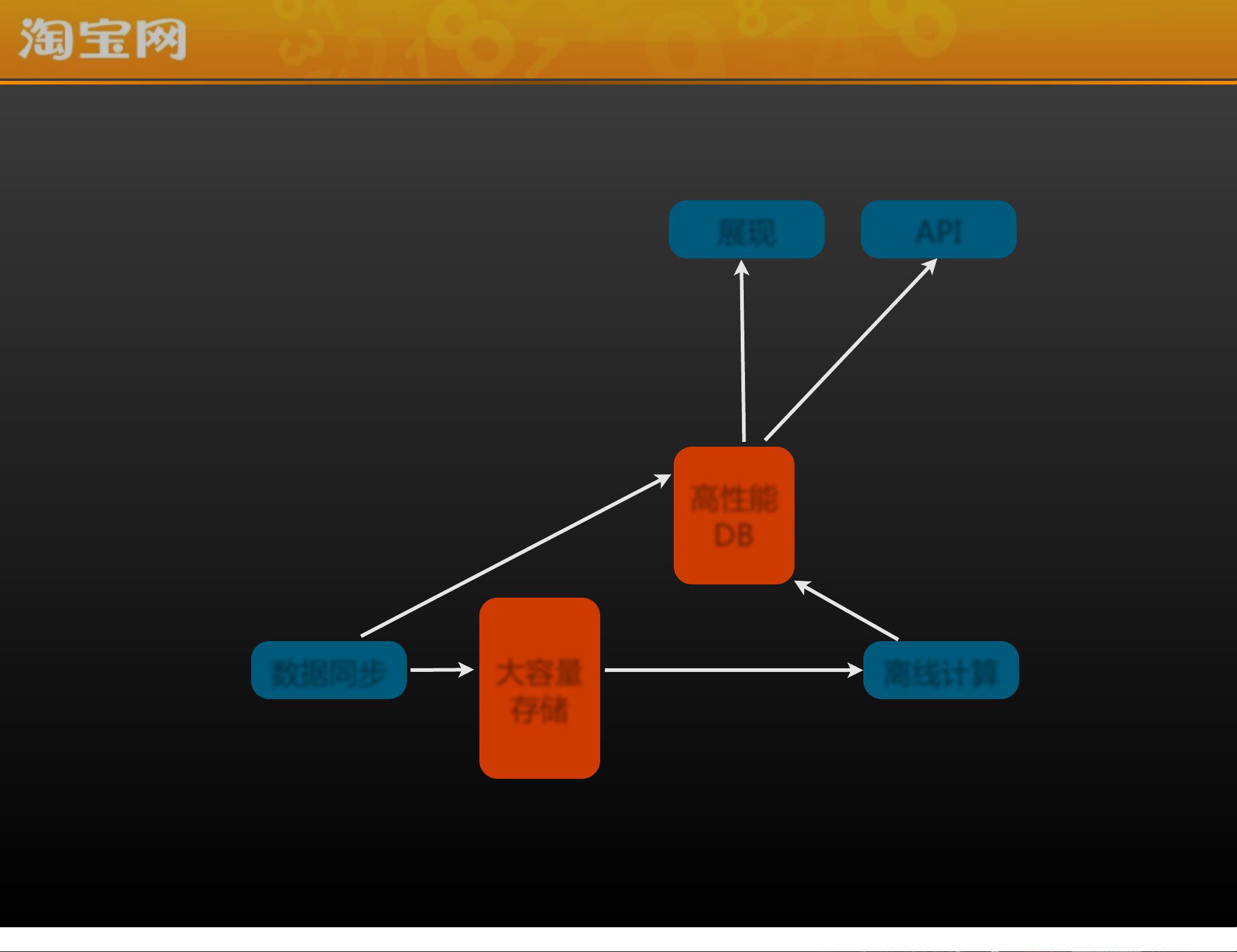
赵昆还讨论了传统的数据平台,包括大容量存储、数据同步、离线计算等,但这些平台往往不能满足实时性要求。他的理想数据平台不仅需要大容量存储和高速访问,还需要具备实时传输、实时计算的能力,以及高效的API接口。
淘宝海量数据技术涉及了从数据采集、存储、处理到应用的全过程,涵盖了分布式系统、实时计算、数据安全、业务支撑等多个层面。在应对数据量爆炸式增长的同时,淘宝致力于提升数据价值,探索更高效的数据产品实践,以适应快速变化的业务需求。

挑战
•
数据的商业模式不清楚,缺乏足够的业务支撑
•
海量数据处理的基础技术需要大量的研发投入
•
数据安全机制非常复杂,还要兼顾效率
•
开放的同时,需要防止数据被恶意爬取
•
基础设施的建设周期较长,可能赶不上业务的变化
•
数据自身变化演进,数据更新非常困难
11年11月26日星期六
剩余56页未读,继续阅读
2011-11-30 上传
2018-01-26 上传
2021-11-19 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

fordream1989
- 粉丝: 9
- 资源: 30
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
