文本处理中的共轭分布与概率模型详解
需积分: 0 67 浏览量
更新于2024-07-01
收藏 530KB PDF 举报
文本处理是信息技术领域中的一个重要分支,涉及自然语言处理、机器翻译、文本分析等多个方面。在这个过程中,理解并应用概率分布至关重要,因为它们帮助我们量化不确定性,为统计模型提供理论基础。本文将介绍三种在文本处理中常用的概率分布:伯努利分布、二项分布和贝塔分布,以及它们在实际应用中的关键概念。
首先,伯努利分布(Bernoulli),也称为0-1分布,是一个离散概率分布,常用于描述单一随机事件的结果,如抛硬币时正面朝上的概率。其概率质量函数为P(x=1|θ) = θ,其中x∈{0,1},θ表示成功发生的概率。伯努利分布的期望值(mean)和方差(variance)分别为E[x]=θ和var[x]=θ(1−θ)。在二项分布中,伯努利分布作为基础,描述了n次独立重复试验中成功的次数,其似然函数和最大似然估计(MLE)提供了理解和预测的具体方法。
接下来是二项分布,它是由n次独立的伯努利试验构成的,每个试验只有两种可能结果。二项分布的概率质量函数 Bin(x|n,θ) 表示x次成功的次数,其中n是试验次数,θ是单次成功的概率。二项分布的期望和方差公式简化了计算,并且当n=1时,它退化为伯努利分布。二项分布的对数似然函数便于推导,有助于优化参数估计。
最后,贝塔分布(Beta)是伯努利和二项分布的共轭先验分布,它是一种连续概率分布,定义在区间(0,1)上。贝塔分布具有两个形状参数α和β,它们在贝叶斯分析中扮演着重要作用。共轭性意味着如果先验分布是贝塔分布,那么根据新的观测数据更新后的后验分布仍然是贝塔分布,这种特性使得参数估计过程更为便捷。贝塔分布的期望值和方差可以用其参数直接计算,这对于构建和优化基于贝叶斯模型的文本处理算法非常有用。
总结来说,伯努利、二项和贝塔分布构成了文本处理中的基础概率框架,它们在模型参数估计、概率推理和性能评估中起着关键作用。掌握这些概率分布及其特性,能够帮助我们在文本挖掘、信息检索、文本分类等任务中设计和实现更精确的统计模型。
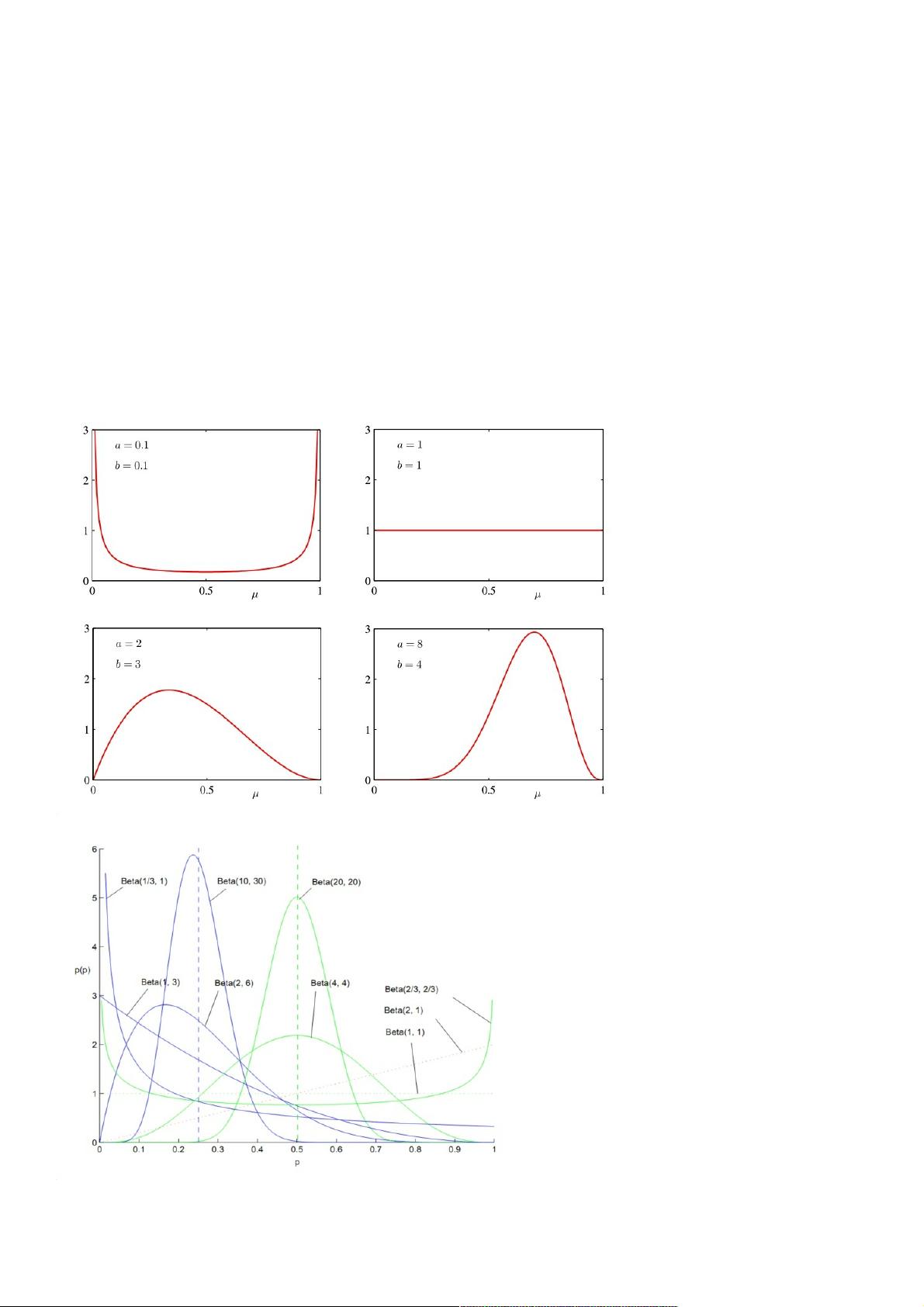
参数 a 和 b 经常被称为超参数( hyperparameter ),它们控制了参数 的概率分布
注:G a m m a 函数:也叫欧拉第二积分,是阶乘函数在实数与复数上扩展的一类函数,写作 ,
实数域上G a m m a 函数定义为:
递归性:
对于不同的超参数a 和b ,B e t a ( |a , b ) 关于 的函数图像如下:
B e t a 分布的图像可以是凹的、凸的、单调上升的、单调下降的,可以是曲线也可以是直线,而
θ
Γ (x)
Γ (x) = dt
∫
+ ∞
0
t
x− 1
e
− t
Γ (x + 1) = xΓ (x)
θ
θ
剩余16页未读,继续阅读

SLHJ-Translator
- 粉丝: 34
- 资源: 297
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
