Python与SPSS实现多元线性回归分析详解
5 浏览量
更新于2024-09-07
收藏 144KB PDF 举报
"这篇教程介绍了如何使用Python和SPSS进行多元线性回归分析,通过一个循环发电厂的数据集来说明。数据集包含5列:AT(温度)、V(压力)、AP(湿度)、RH(压强)和PE(输出电力)。目标是建立一个线性回归模型,预测PE值,其中AT、V、AP和RH为特征变量,模型形式为PE = θ0 + θ1 * AT + θ2 * V + θ3 * AP + θ4 * RH。在预处理阶段,数据被归一化处理。在Python中,通过定义成本函数(Cost Function)并使用梯度下降或正规方程来优化θ参数,以最小化损失。"
在多元线性回归分析中,目标是找到一组权重参数(θ)来建立一个线性模型,该模型能够最好地拟合给定特征与目标变量之间的关系。在这个例子中,目标变量是PE(输出电力),特征变量包括AT、V、AP和RH。模型的形式是一条直线,表示为线性组合的形式:
\[ PE = \theta_0 + \theta_1 \cdot AT + \theta_2 \cdot V + \theta_3 \cdot AP + \theta_4 \cdot RH \]
其中,\(\theta_0\) 是截距,\(\theta_1, \theta_2, \theta_3, \theta_4\) 分别是特征对应的权重。为了确保模型的可比性,通常会对数据进行预处理,如归一化,使其均值为0,标准差为1。这一步有助于消除不同特征之间尺度的影响。
线性回归的核心是找到最优的权重参数,这通常通过最小化损失函数(Cost Function)来实现。对于线性回归,损失函数通常是均方误差(Mean Squared Error,MSE),表达式为:
\[ J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)})^2 \]
其中,\(m\) 是样本数量,\(h_\theta(x)\) 是模型预测值,\(y\) 是实际值。在Python中,可以通过定义一个函数计算这个损失,并使用梯度下降或正规方程等优化算法来找到使损失最小化的\(\theta\)值。
在本教程中,作者使用了Python的Pandas库来读取和处理数据,Numpy库进行数值计算,以及Matplotlib库进行可视化。数据集首先被加载并使用Pandas的head()函数进行初步查看。接着,使用数据的平均值和标准差进行归一化处理。之后,通过定义损失函数并初始化\(\theta\)为全零向量,计算了初始的损失值。
最后,为了找到最佳的\(\theta\)值,需要执行优化过程,这可能涉及梯度下降算法或者正规方程的求解。梯度下降是迭代地调整\(\theta\)以减小损失,而正规方程则直接求解损失函数的导数为零时的\(\theta\)值,通常适用于特征数量相对较小的情况。
在SPSS中,执行多元线性回归分析可能会更直观,用户可以直接输入数据,选择适当的变量,然后软件会自动计算模型参数并提供统计输出,包括系数、R²值、显著性测试等。不过,本教程的重点在于使用Python进行编程实现,这提供了更多灵活性和自动化处理能力,适合于更复杂的数据分析任务。
关于多元线性回归分析关于多元线性回归分析——Python&SPSS
今天小编就为大家分享一篇关于多元线性回归分析——Python&SPSS,具有很好的参考价值,希望对大家有所
帮助。一起跟随小编过来看看吧
原始数据在这里
1.观察数据观察数据
首先,用Pandas打开数据,并进行观察。
import numpy
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv('Folds5x2_pp.csv')
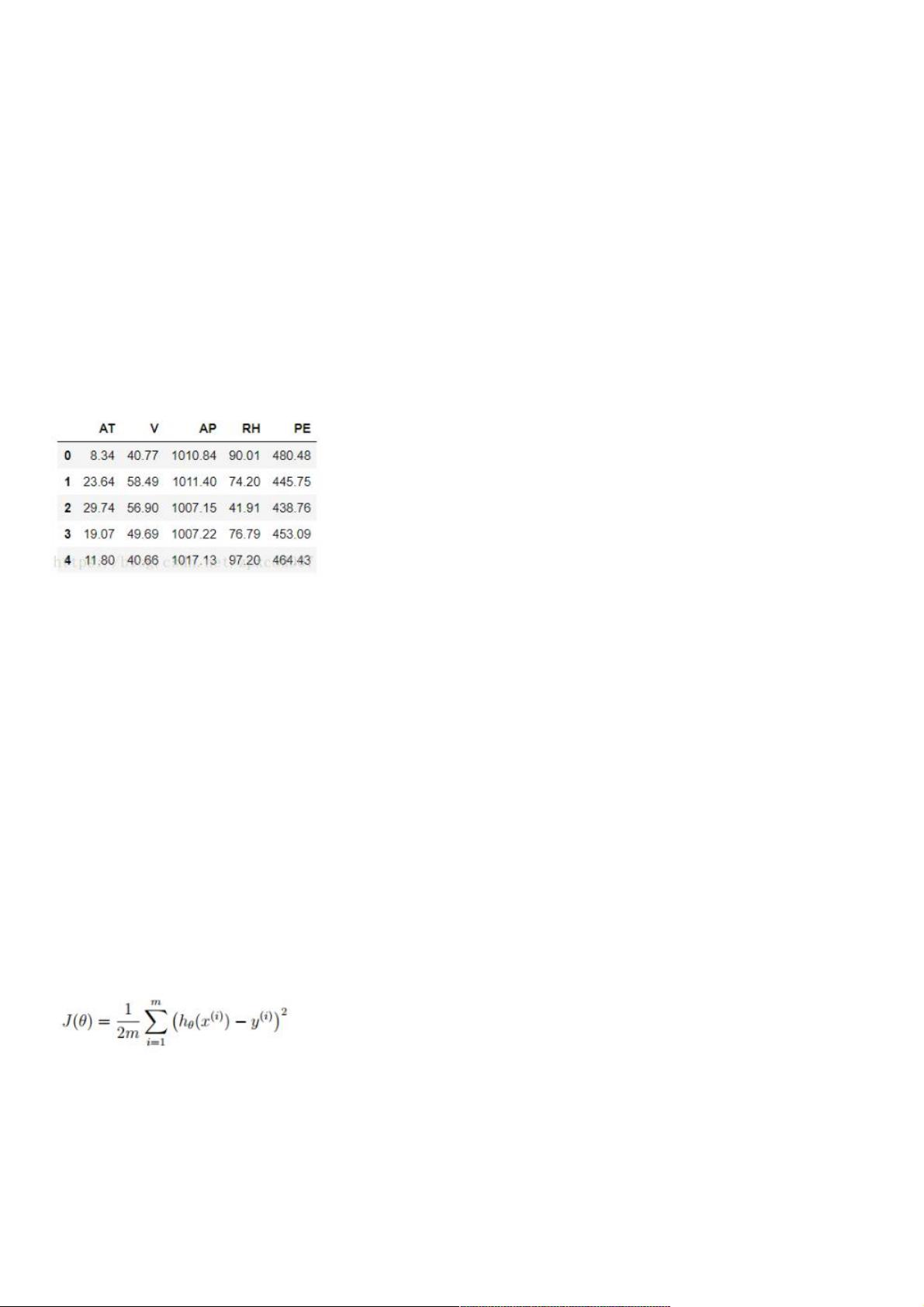
data.head()
会看到数据如下所示:
这份数据代表了一个循环发电厂,每个数据有5列,分别是:AT(温度), V(压力), AP(湿度), RH(压强), PE(输出电
力)。我们不用纠结于每项具体的意思。
我们的问题是得到一个线性的关系,对应PE是样本输出,而AT/V/AP/RH这4个是样本特征, 机器学习的目的就是得到一个线
性回归模型,即: PE=θ0+θ1∗AT+θ2∗V+θ3∗AP+θ4∗RH 而需要学习的,就是θ0,θ1,θ2,θ3,θ4这5个参数。
接下来对数据进行归一化处理:
data = (data - data.mean())/data.std()
因为回归线的截距θ0是不受样本特征影响的,因此我们在此可以设立一个X0=1,使得回归模型为:
PE=θ0*X0+θ1∗AT+θ2∗V+θ3∗AP+θ4∗RH
将方程向量化可得:
PE = hθ(x) = θx (θ应转置)
2.线性回归线性回归
在线性回归中,首先应建立 cost function,当 cost function 的值最小时所取得θ值为所求的θ。
在线性回归中,Cost function如下所示:
因此,可以在Python中建立函数求损失方程:
def CostFunction(X,y,theta):
inner = np.power((X*theta.T)-y,2)
return np.sum(inner)/(2*len(X))
然后,设初始θ为=[0,0,0,0,0],可得到最初的J(θ)值为0.49994774247491858,代码如下所示
col = data.shape[1]
X = data.iloc[:,0:col-1]
y = data.iloc[:,col-1:col]
X = np.matrix(X.values)
下载后可阅读完整内容,剩余3页未读,立即下载
2019-10-30 上传
2008-11-21 上传
2023-06-01 上传
2023-05-27 上传
2023-07-29 上传
2023-08-08 上传
2024-06-07 上传
2023-05-12 上传

weixin_38625143
- 粉丝: 6
- 资源: 916
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
