Elasticsearch入门教程:核心概念与实战应用
需积分: 35 106 浏览量
更新于2024-07-16
收藏 408KB DOCX 举报
"Elasticsearch 是一款开源的、高度可扩展的分布式全文检索引擎,它基于 Java 开发,内核采用 Lucene 实现,旨在通过 RESTful API 简化全文搜索的复杂性。Elasticsearch 能够支持大规模数据处理,提供高可用性和容错能力,适合处理PB级别的数据。
在 Elasticsearch 中,有几个核心概念:
1. **集群(Cluster)**: 集群是由多个互相协作的服务器组成的整体,用于处理大型数据集和确保高可用性。每个集群有一个唯一的名称,用于识别不同的集群。
2. **节点(Node)**: 集群中的每个服务器称为节点,它们共同存储和处理数据。节点可以通过加入同一集群参与到数据处理中。
3. **分片(Shard)**: 分片是数据的逻辑部分,用于在多个节点之间分布数据,以解决单一节点的数据处理限制。每个分片可以进一步细分为主分片和副本分片。
- **主分片(Main Shard)**: 主分片是原始数据的存储位置,用于执行索引操作。
- **副本分片(Replica Shard)**: 副本分片是主分片的精确复制,用于提高查询性能和数据冗余,以防主分片出现问题。
4. **全文检索(Full-text Search)**: Elasticsearch 提供全文检索功能,通过对文档内容进行分词处理,建立索引,使得用户可以基于关键词进行搜索。这与关系型数据库中的 LIKE 语句类似,但更为高效。
Elasticsearch 与传统关系型数据库的区别在于:
- **数据库 vs 索引**: 在关系型数据库中,数据库对应于 Elasticsearch 的索引,是数据的容器。
- **表 vs 类型(Type)**: 数据库中的表相当于 Elasticsearch 中的索引下的类型,类型是具有相似结构的文档集合。
- **行 vs 文档(Document)**: 表中的每一行对应于 Elasticsearch 中的一个文档,文档是一组键值对,表示一个完整的实体。
- **列 vs 字段(Field)**: 表中的列在 Elasticsearch 中表现为文档内的字段,每个字段都有特定的数据类型。
Elasticsearch 安装和使用通常包括配置集群设置、启动节点、创建索引、定义映射、索引数据、执行查询等步骤。同时,还可以利用各种插件扩展其功能,比如 Kibana 用于数据可视化,Logstash 用于日志收集和处理,Beats 用于轻量级数据传输等。
在实际应用中,Elasticsearch 广泛应用于日志分析、实时搜索、监控系统、物联网数据分析等领域,因其优秀的搜索性能和易于扩展的特性,成为现代大数据处理和分析的重要工具。"
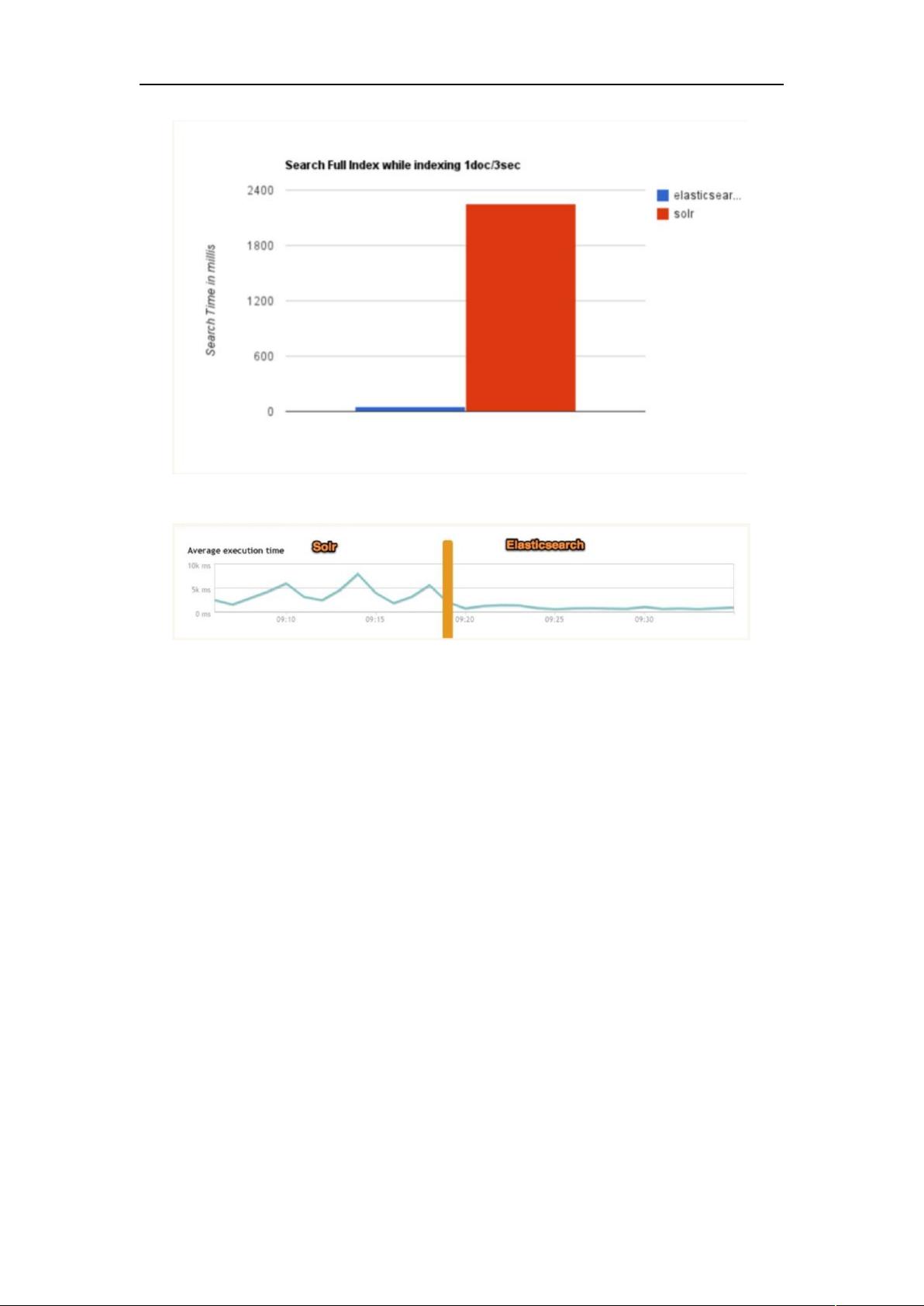
对于新兴的实时搜索引擎,更换 ES 后效率明显提升。
总结:
1. Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布
式协调管理功能;
2. Solr 支持更多格式的数据,而 Elasticsearch 仅支持 json 文件格式;
3. Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高
级功能多有第三方插件提供;
4. Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用
时效率明显低于 Elasticsearch。
5. Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的
实时搜索应用。
1.5 应用场景
1) 2013 年初,GitHub 抛弃了 Solr,采取 ElasticSearch 来做 PB 级的搜索。
“GitHub 使用 ElasticSearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。
2)维基百科:启动以 elasticsearch 为基础的核心搜索架构。
3)SoundCloud:“SoundCloud 使用 ElasticSearch 为 1.8 亿用户提供即时而
剩余17页未读,继续阅读
107 浏览量
点击了解资源详情
104 浏览量
2024-01-30 上传
107 浏览量
2024-07-16 上传
2024-07-24 上传
2024-07-12 上传
2021-09-30 上传

jiadaishi
- 粉丝: 6
- 资源: 71
 我的内容管理
展开
我的内容管理
展开







