菜鸟实时数仓架构升级:从混乱到高效
本文主要探讨了菜鸟实时数仓技术架构的演进过程,面对物流供应链对时效性的高要求,原有的离线数仓架构已经无法满足快速发展需求。文章详细分析了以前的实时数据技术架构存在的问题,包括:
1. 数据模型方面:业务线内部数据模型层次复杂,导致数据使用成本高且复用性差,计算成本居高不下。数据一致性难以保证,BI(商业智能)使用面临挑战。
2. 计算引擎:早期使用阿里云的JStorm和Spark Streaming进行实时计算,但难以在物流供应链场景中实现功能、性能、稳定性和快速故障恢复的平衡。
3. 数据服务:实时数据存储在MySQL和HBase等数据库中,查询和保障灵活性不足,BI权限管理和全链路保障存在缺陷。
为了提升效率和稳定性,文章提出了数据模型的升级策略:
- 模型分层:借鉴离线数仓的做法,采用TT消息中间件和HBase构建事实明细宽表,生成轻度和高度汇总层,满足不同场景的需求。
- 预置分流:将公共数据和业务数据分离,左侧为整合后的公共数据中间层,右侧为根据业务需求个性化的数据中间层,如区分进口和出口供应链,减少了计算资源的消耗。
- 菜鸟供应链实时数据模型:构建基于公共数据的大盘订单和物流详情的通用模型,然后在此基础上根据不同业务进行个性化处理,如国内、进口和出口供应链。
本文还可能探讨了新技术工具的探索和创新,以及未来发展趋势和思考,包括如何更好地利用分布式计算、流处理技术、实时数据分析平台等,以应对不断增长的订单量和实时性要求,提高数据处理的准确性和效率。此外,文中可能还会提及如何优化运维管理、提升数据安全性、降低延迟等方面的内容,以确保实时数仓系统的高效运行和持续改进。
菜鸟实时数仓技术架构演进菜鸟实时数仓技术架构演进
导读:在开源盛世的今天,实时数仓的建设已经有了较为成熟的方案,技术选型上也都各有优劣。菜鸟作为物流供应链的主力
军,时效要求已经成为了核心竞争力,离线数仓已不能满足发展的需要,在日益增长的订单和时效挑战下,菜鸟技术架构也在
不断发展和完善,如何更准更高效的完成开发和维护,变得格外重要。
本文主要包括以下内容:
以前的实时数据技术架构
数据模型、计算引擎、数据服务的升级
其他技术工具的探索和创新
未来发展与思考
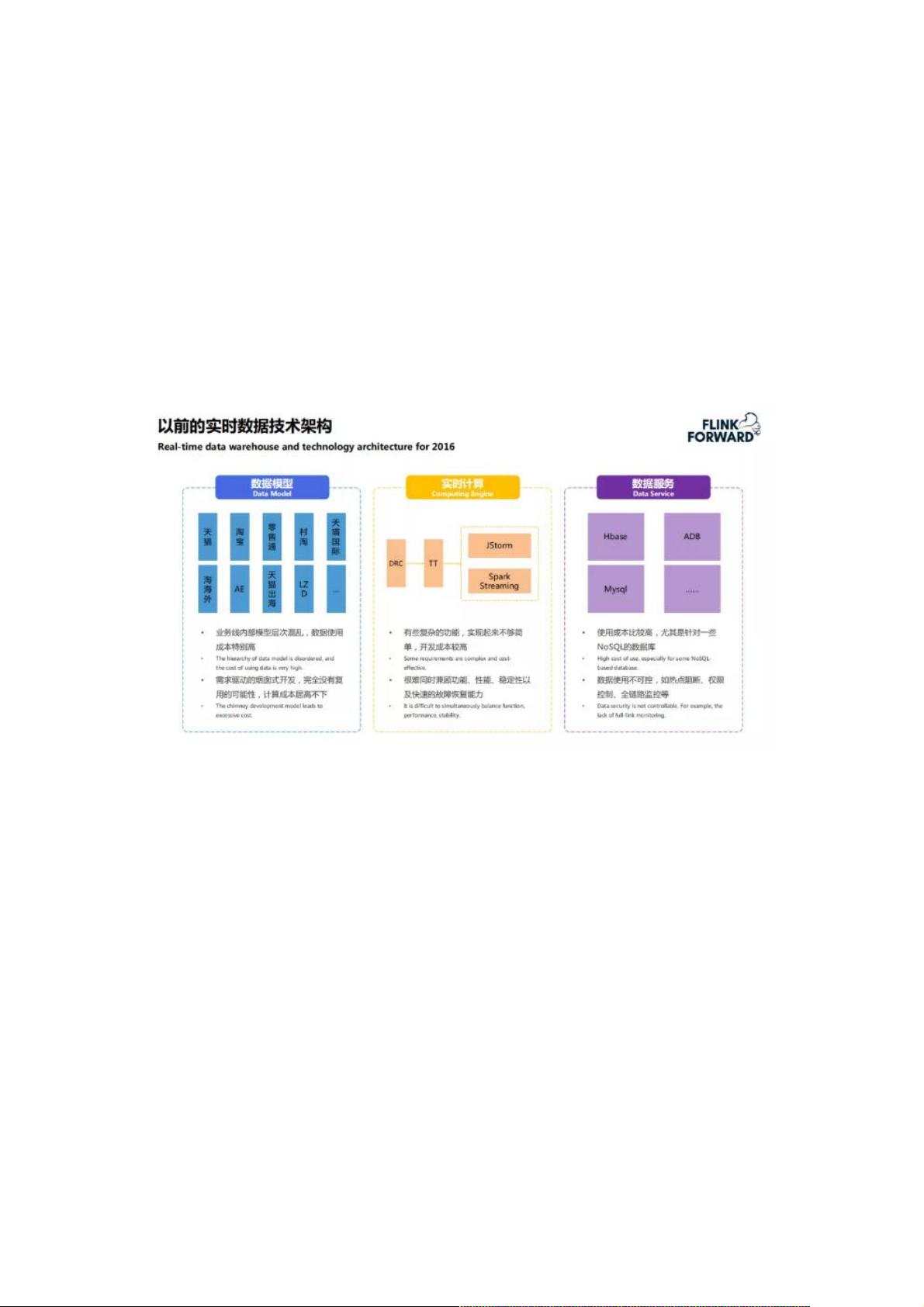
01、以前的实时数据技术架构
数据模型:
业务线内部模型层次混乱,数据使用成本特别高
需求驱动的烟囱式开发,完全没有复用的可能性,计算成本居高不下
各业务线横向或者纵向的交叉,导致开发过程中数据一致性偏差较大
纵向的数据模型,导致 BI 使用时比较困难
实时计算:
我们之前使用阿里云的 JStorm 和 Spark Streaming 进行开发,这两部分能满足大部分的实时数据开发,但是应用到物流供应
链场景当中,实现起来并不简单,甚至无法实现
很难同时兼顾功能、性能、稳定性以及快速故障恢复能力
数据服务:
开发过程中,实时数据下沉到 MySQL,HBase 等数据库中,查询和保障方面不灵活
BI 权限控制和全链路保障不可靠
02、数据模型升级
1. 模型分层
下载后可阅读完整内容,剩余8页未读,立即下载
175 浏览量
227 浏览量
227 浏览量
175 浏览量
点击了解资源详情
点击了解资源详情
138 浏览量
点击了解资源详情
321 浏览量

weixin_38733333
- 粉丝: 4
- 资源: 922
 我的内容管理
展开
我的内容管理
展开







最新资源
- 顶部导航菜单下拉,左侧分类切换
- XX公司企业文化职能战略规划PPT
- torch_cluster-1.5.6-cp37-cp37m-win_amd64whl.zip
- 使用WPF表单的AC#系统托盘应用程序
- Color-Transfer-between-Images:这是开源工具Erik Reinhard,Michael Ashikhmin,Bruce Gooch和Peter Shirley撰写的论文“图像之间的颜色转移”
- log4net工具包与配置文件.rar
- 企业文化案例(8个文件)
- PokemonGo-CalcyIV-Renamer:使用adb将假冒的点击事件发送到您的手机,以及Calcy IV一起自动重命名所有宠物小精灵
- torch_sparse-0.6.5-cp36-cp36m-win_amd64whl.zip
- cd2021
- Angel网络工作室报名网站管理系统v1.0
- CssWebResposive:罪过的评论
- 导航条宽度随二级菜单宽度变化的
- 系统温湿度检测与控制 1-源程序注释.rar
- iicTets.zip
- QAServer:基于质量检查服务器的中文CQA网站
