菜鸟实时数仓架构升级:模型分层与预置分流应对时效挑战
45 浏览量
更新于2024-08-28
1
收藏 597KB PDF 举报
本文主要探讨了菜鸟实时数仓技术架构的演进历程,针对菜鸟作为物流供应链的重要角色,实时数据处理的需求显著提升,原有的离线数仓架构已经无法满足其高速发展的时效性和灵活性。文章着重分析了以前的实时数据技术架构存在的问题,包括数据模型的复杂性、烟囱式开发导致的复用性差和计算成本高,以及实时计算在物流供应链场景中的局限性。
在数据模型升级方面,作者提出采用分层策略,借鉴离线数仓的设计,首先从MySQL等数据库收集原始数据,然后通过TT消息中间件进行清洗和转换,生成事实明细宽表,并进一步划分为轻度汇总层和高度汇总层,以满足不同场景的需求。这种设计提高了数据的一致性和易用性,特别是通过预置分流,将公共数据与业务特定数据分离,降低了计算资源的消耗。
在实时计算引擎方面,文中提到过去使用了阿里云的JStorm和SparkStreaming,但它们在处理物流供应链场景时存在挑战。为了优化,作者可能引入了更加适应实时数据处理的解决方案,可能是流处理框架的改进或自定义开发,以确保在功能、性能、稳定性和故障恢复方面的平衡。
在数据服务层面,原有的模式使得查询和权限管理存在不足,实时数据存储在MySQL和HBase中缺乏灵活性,BI的使用和全链路保障成为问题。通过升级数据服务,作者可能引入了更强大的数据服务组件,如数据湖、实时数据仓库等,以提供更好的查询性能和权限管理。
未来,菜鸟可能会继续探索和创新其他技术工具,比如大数据处理技术的优化、AI和机器学习的应用,以及更先进的数据管理和分析工具,以适应不断变化的业务需求和行业趋势。此外,对于数据安全、隐私保护和合规性也将是未来关注的重点,以确保在技术演进的同时,保证数据的合规处理和企业合规运营。
菜鸟实时数仓技术架构的演进是一个持续优化的过程,旨在提高数据处理效率,降低开发和维护成本,以支持物流供应链的高效运作和业务增长。
菜鸟实时数仓技术架构演进菜鸟实时数仓技术架构演进
导读:在开源盛世的今天,实时数仓的建设已经有了较为成熟的方案,技术选型上也都各有优劣。菜鸟作为物流供应链的主力
军,时效要求已经成为了核心竞争力,离线数仓已不能满足发展的需要,在日益增长的订单和时效挑战下,菜鸟技术架构也在
不断发展和完善,如何更准更高效的完成开发和维护,变得格外重要。
本文主要包括以下内容:
以前的实时数据技术架构
数据模型、计算引擎、数据服务的升级
其他技术工具的探索和创新
未来发展与思考
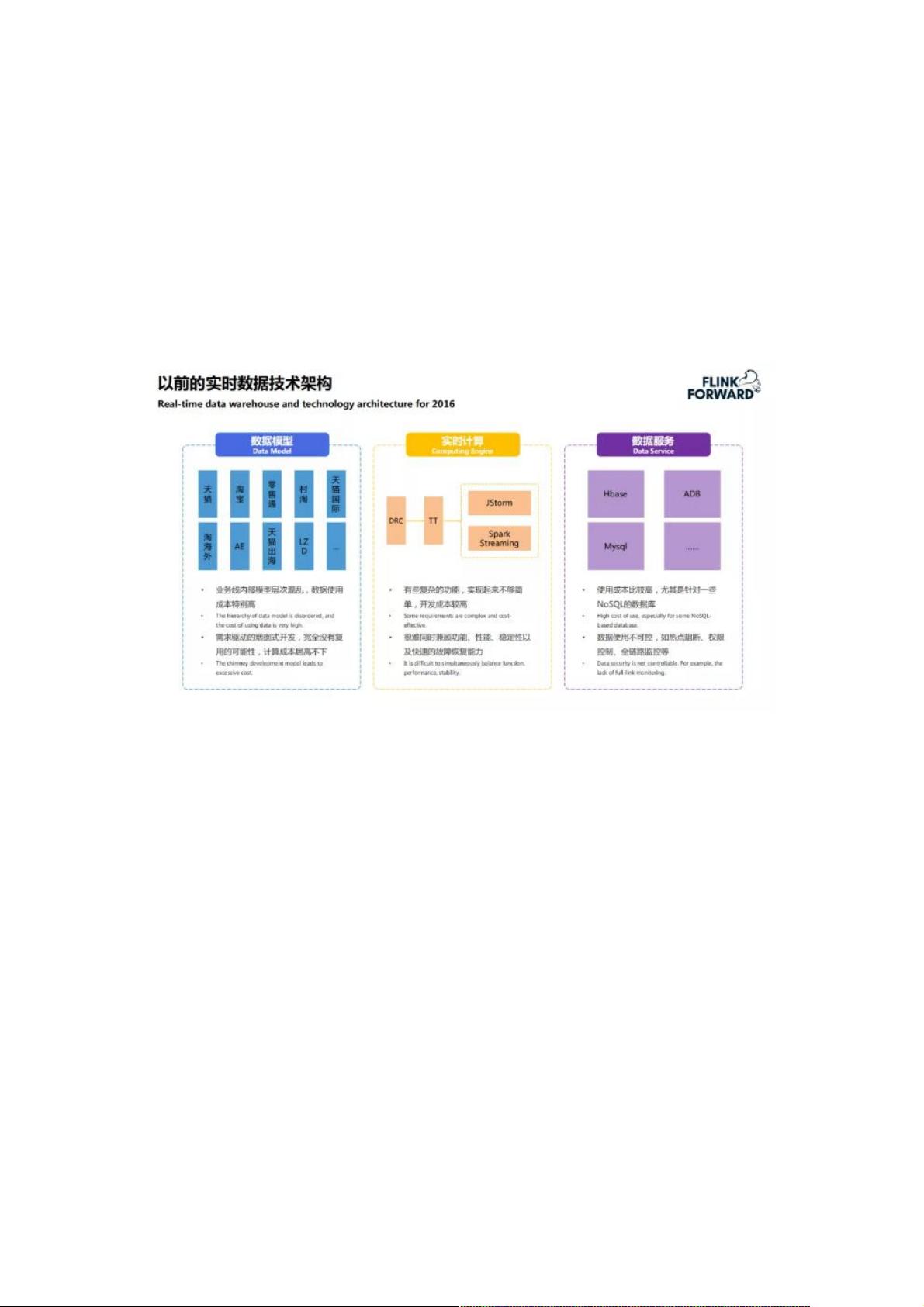
01、以前的实时数据技术架构
数据模型:
业务线内部模型层次混乱,数据使用成本特别高
需求驱动的烟囱式开发,完全没有复用的可能性,计算成本居高不下
各业务线横向或者纵向的交叉,导致开发过程中数据一致性偏差较大
纵向的数据模型,导致 BI 使用时比较困难
实时计算:
我们之前使用阿里云的 JStorm 和 Spark Streaming 进行开发,这两部分能满足大部分的实时数据开发,但是应用到物流供应
链场景当中,实现起来并不简单,甚至无法实现
很难同时兼顾功能、性能、稳定性以及快速故障恢复能力
数据服务:
开发过程中,实时数据下沉到 MySQL,HBase 等数据库中,查询和保障方面不灵活
BI 权限控制和全链路保障不可靠
02、数据模型升级
1. 模型分层
下载后可阅读完整内容,剩余8页未读,立即下载
175 浏览量
227 浏览量
227 浏览量
175 浏览量
点击了解资源详情
点击了解资源详情
138 浏览量
445 浏览量
321 浏览量

weixin_38713306
- 粉丝: 3
- 资源: 883
 我的内容管理
展开
我的内容管理
展开







最新资源
- pyuiEdit:一种重组pyui文件的工具
- pump.io:[OBSOLETE] pump.io的前叉,pump.io是具有ActivityStreams API的社交服务器
- BootLoader上位机
- 错误循环
- DaaS:Dajare即服务(ダジャレ判定评価エンジン)
- 数据缩放:将矩阵的值从用户指定的最小值缩放到用户指定的最大值的程序-matlab开发
- NewsSystem:基于Struts + Spring + Hibernate + Bootstrap
- ForecastingChallenge:G-Research预测挑战
- 纷争世界--- jRPG:《最终幻想II》启发的jRPG
- 太原泛华盛世开盘前计划
- i-am-poor-android-Ajinkya-boop:由GitHub Classroom创建的i-am-poor-android-Ajinkya-boop
- sporty-leaderboards
- table表格拖动列
- 酒店装修图纸
- CSE110_Lab2.github.io
- Front-end-exercise
