Hive错误解决:连接、执行脚本与内存溢出问题
需积分: 50 144 浏览量
更新于2024-09-07
1
收藏 295KB DOCX 举报
"这篇文档主要介绍了在使用Hive过程中遇到的一些常见报错及相应的解决方法,包括连接报错、执行脚本卡住、内存溢出和表死锁问题。"
一、Hive连接报错
当Hive连接报错时,可能是由于多种原因导致的。一种情况是Hive元数据存在多版本问题,这通常由于网络波动或服务未正确关闭(如换网卡时未关闭MySQL服务)造成。解决方法包括:
1. 在启动Hive时,使用debug模式以获取更详细的错误信息,通过设置`hive.root.logger=DEBUG,console`来开启日志级别。
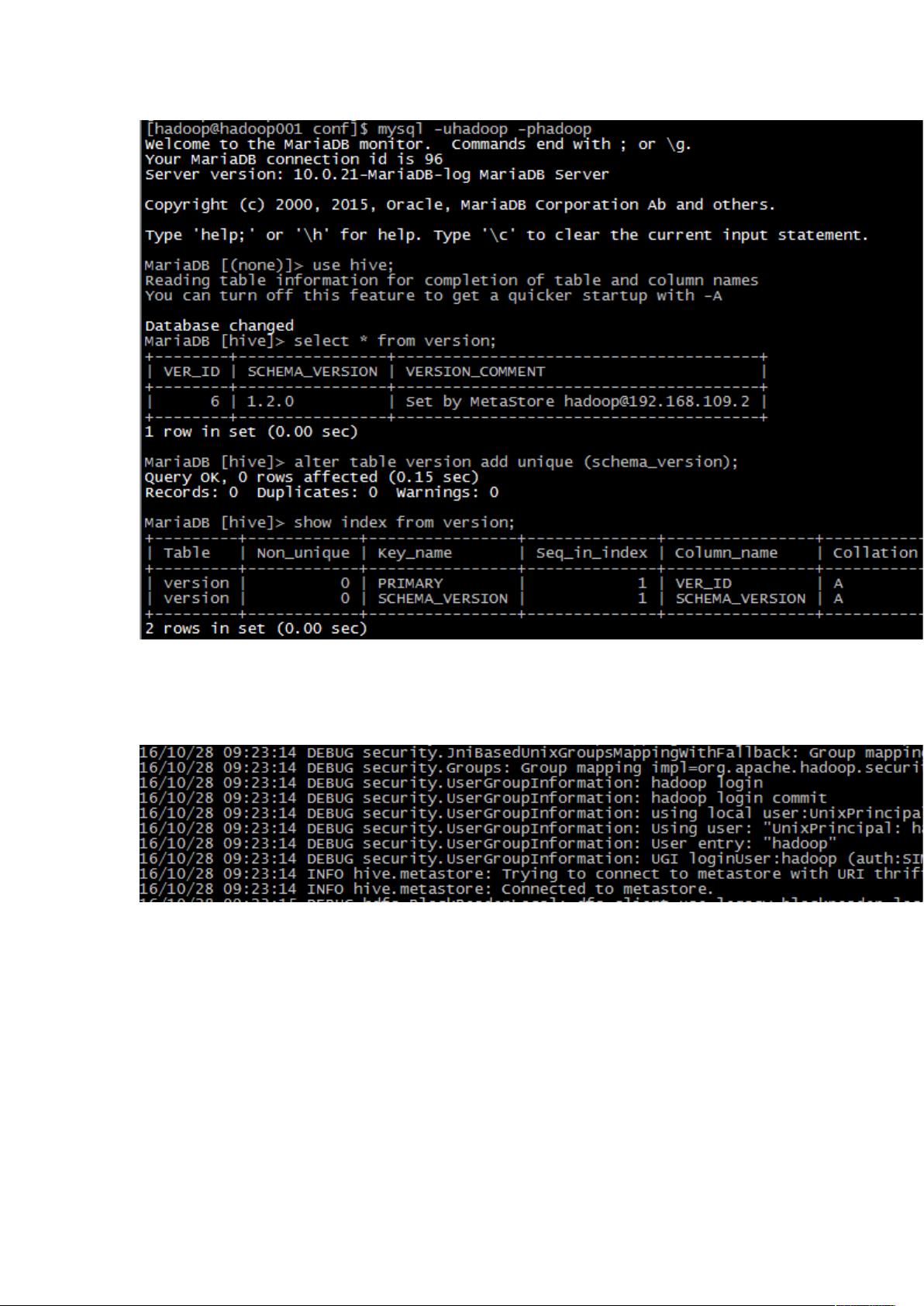
2. 分析错误日志,发现`MetaException(message:Metastorecontains multiple versions)`,表明元数据存在多个版本。此时,可以连接到MySQL,对`version`表添加唯一索引,确保元数据的唯一性。命令如下:
```sql
alter table version add unique (schema_version);
```
3. 如果上述步骤无效,检查9083端口是否被占用。通过`lsof -i:9083`列出占用该端口的进程,并使用`ps -ef | grep pid`查找并终止占用端口的进程。
二、Hadoop安全模式问题
当Hadoop处于安全模式,即只读状态,可能导致Hive操作失败。可以使用`hdfs dfsadmin -safemode get`命令查看当前是否处于安全模式。如果在,可以尝试以下两种方式退出:
1. 修改`dfs.safemode.threshold.pct`配置,将其设为较小的值,如0.1,使系统更容易离开安全模式。
2. 使用`hadoop dfsadmin -safemode leave`命令强制退出安全模式,但请注意,这种方式可能在数据不完整的情况下执行,需谨慎操作。
三、执行Hive脚本卡住报错
执行Hive脚本时卡住,可能是因为某些服务或端口问题。例如,检查10200端口是否被占用,如果未发现占用,可能原因是Hadoop服务重启导致的问题。需要进一步排查Hadoop集群的状态,确保所有服务正常运行。
四、内存溢出报错
内存溢出通常是由于查询太复杂或者内存设置不当导致的。处理内存溢出问题,可以考虑以下策略:
1. 调整Hive的内存参数,如增大`mapreduce.map.memory.mb`和`mapreduce.reduce.memory.mb`,以及`hive.exec.memory.per.node`等设置。
2. 优化查询语句,避免全表扫描和大join操作,尽可能地利用分区和过滤条件。
3. 分解复杂查询为多个小查询,降低每次操作的数据量。
五、表死锁问题
Hive中的表死锁通常发生在多用户同时进行DDL操作时。解决方法包括:
1. 使用事务隔离级别,确保每个用户的操作互不影响。
2. 监控Hive Metastore服务,及时发现并解除死锁。
3. 优化并发操作,避免在同一时间进行大量DDL操作。
总结来说,解决Hive的报错问题需要深入理解Hive的工作原理、Hadoop集群的运行机制以及数据库的基本概念。在遇到问题时,首先要分析错误信息,然后根据具体情况进行相应配置调整或服务操作。在实际操作中,确保对系统的全面监控和日志记录也是至关重要的。
2.查看 9083 端口是否被占用
改完索引以后仍然出现问题,端口占用
如果 hadoop001 网络连接正常,就应该注意端口问题了
正常情况下,lsof -i:9083 会有 hive 连接和 udf 函数进程,创建一个 hive 客户端连接,
也会有一个进程。
出现端口占用问题,找到相应的 pid,ps -ef | grep pid,确认下是什么进程在占用,然
后 kill 掉。
剩余10页未读,继续阅读
2024-07-20 上传
2024-07-24 上传
2024-07-23 上传
2023-06-28 上传
2023-12-03 上传
2024-11-02 上传
2023-06-13 上传
2023-12-09 上传
2024-11-12 上传

tychostone
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







