决策树中的信息增益和基尼系数算法
需积分: 0 168 浏览量
更新于2023-12-30
收藏 655KB PDF 举报
决策树(Decision Tree)是一种常用的机器学习算法,通过对数据集进行分析,构建一棵树形结构的决策模型,用于预测或分类数据。在决策树算法中,常常使用信息论的基本概念来进行属性选择和节点划分。信息增益(information gain)和基尼系数是常用的属性选择准则,在决策树的构建过程中起着重要的作用。
信息增益是衡量属性对样本集合的纯度影响的指标,通过计算属性划分前后的信息熵的变化来选择最优的划分属性。而基尼系数是另一种衡量属性选择的准则,在属性值缺失的情况下,也常常使用基尼系数来进行划分属性选择。当样本在某一属性上的值缺失时,决策树需要考虑如何对这些样本进行划分。此时,可以利用已有的属性值的信息来进行划分,或者可以考虑对属性值缺失的样本进行特殊处理。
在决策树的构建过程中,信息论基础的概念对于衡量不确定性起着关键作用。信息熵是指随机系统的总体信息量,是用所有随机事件自信息的统计平均来表示的。通过信息熵的计算,可以衡量样本集合的纯度和不确定性程度,从而进行最优的属性选择和节点划分。信息熵具有一系列的性质,如对称性、非负性、可加性等,这些性质为决策树的构建提供了理论基础和数学保障。
此外,联合熵是一种衡量两个随机变量共同信息量的指标,在决策树算法中也常常用于属性选择和节点划分。通过对属性值之间的关联性进行联合熵的计算,可以更加全面地评估属性的重要性和影响程度。联合熵的计算为决策树算法提供了更加丰富的信息,使得决策树模型更加准确和可靠。
综上所述,决策树是一种基于信息论基础的机器学习算法,其属性选择和节点划分过程主要依赖于信息增益、基尼系数和信息熵等概念。这些信息论基础的概念为决策树算法提供了理论支持和数学基础,使得决策树算法在实际应用中取得了良好的效果。在今后的研究和实践中,可以进一步探讨和完善这些信息论基础概念在决策树算法中的应用,以提高决策树算法的性能和效果。
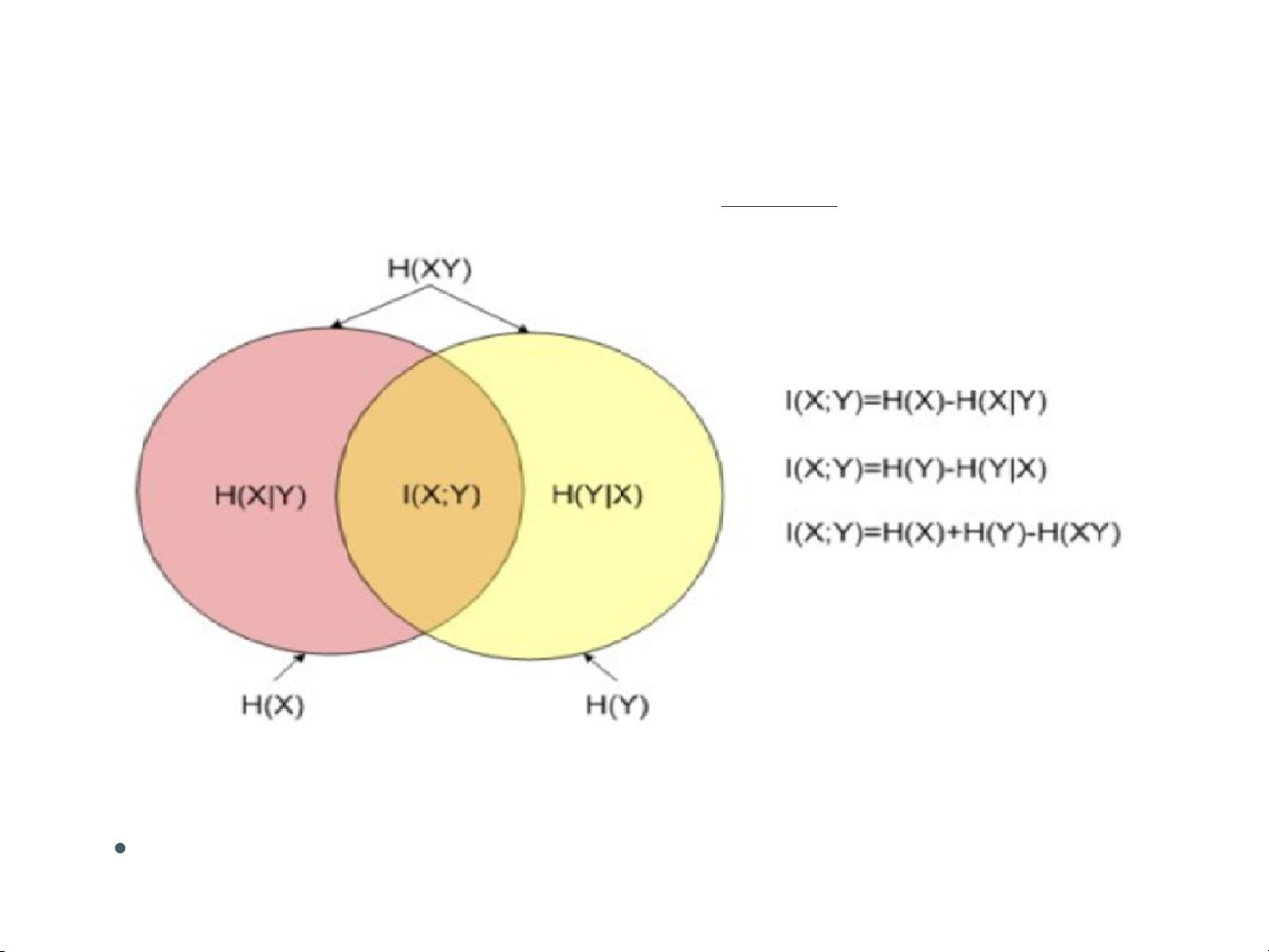
互信息: 或
互信息是对称的。
I (X ; Y ) = H (X ) − H (X ∣Y )
I (X ; Y ) = p(x, y) log ∑
x∈X
∑
y∈Y
p(x)p(y)
p(x,y)
5
剩余24页未读,继续阅读
2022-08-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

丽龙
- 粉丝: 29
- 资源: 332
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
