SQL邻接表设计:优化树形结构查询与后代获取
需积分: 0 28 浏览量
更新于2024-08-04
收藏 435KB DOCX 举报
在数据库设计中,树形结构是一种常见的数据模型,特别是在表示具有层次关系的数据时。本文主要探讨了邻接表方法在存储和查询分层结构数据,特别是数据库评论系统中的应用。邻接表(Adjacency List)是其中一种常见的设计策略,它将每个节点与其直接父节点关联,通过外键引用的方式构建父子关系。
首先,邻接表的创建如所示:
1. 设计`Comments`表,包含字段如`CommentId`(主键)、`ParentId`(表示父节点的ID)、`ArticleId`(文章ID)、`CommentBody`等。表中使用外键约束,如`FOREIGN KEY(ParentId)`引用自身表中的`CommentId`,以及`FOREIGN KEY(ArticleId)`引用`Articles`表中的`ArticleId`,形成自连接结构。
然而,邻接表在处理深度嵌套查询时存在局限性。例如,查询一个节点的所有后代(子树)在早期版本的SQL中可能需要多次联接操作,随着层级增加,查询性能会下降,并且对于聚合函数(如`COUNT()`)的计算也会变得复杂。这在SQL Server 2005之前尤为明显。
为了改进这一问题,SQL Server 2005引入了公共表表达式(Common Table Expression, CTE),或者称为递归查询。利用CTE,可以创建一个递归查询来遍历整个子树,从而避免了逐层联接的限制。例如,查询评论4的所有子节点的代码示例如下:
```sql
WITH COMMENT_CTE AS (
-- 基本查询
SELECT CommentId, ParentId, CommentBody, 0 AS tLevel
FROM Comments
WHERE ParentId = 4
UNION ALL
-- 递归查询
SELECT c.CommentId, c.ParentId, c.CommentBody, ce.tLevel + 1
FROM Comments AS c
INNER JOIN COMMENT_CTE AS ce
ON c.ParentId = ce.CommentId
)
```
通过这种方法,不仅能够一次性获取指定节点的所有子节点,还能处理更复杂的查询,如计算子节点数量或层次深度,提高了查询效率。总结来说,邻接表在数据库中树形结构的设计中是一个基础且灵活的工具,但随着SQL技术的发展,如CTE的引入,使得处理深层嵌套数据变得更加高效。
(
--基本语句
SELECT CommentId,ParentId,CommentBody,0 AS tLevel FROM Comment
WHERE ParentId = 4
UNION ALL --递归语句
SELECT c.CommentId,c.ParentId,c.CommentBody,ce.tLevel + 1 FROM
Comment AS c
INNER JOIN COMMENT_CTE AS ce --递归查询
ON c.ParentId = ce.CommentId
)
SELECT * FROM COMMENT_CTE
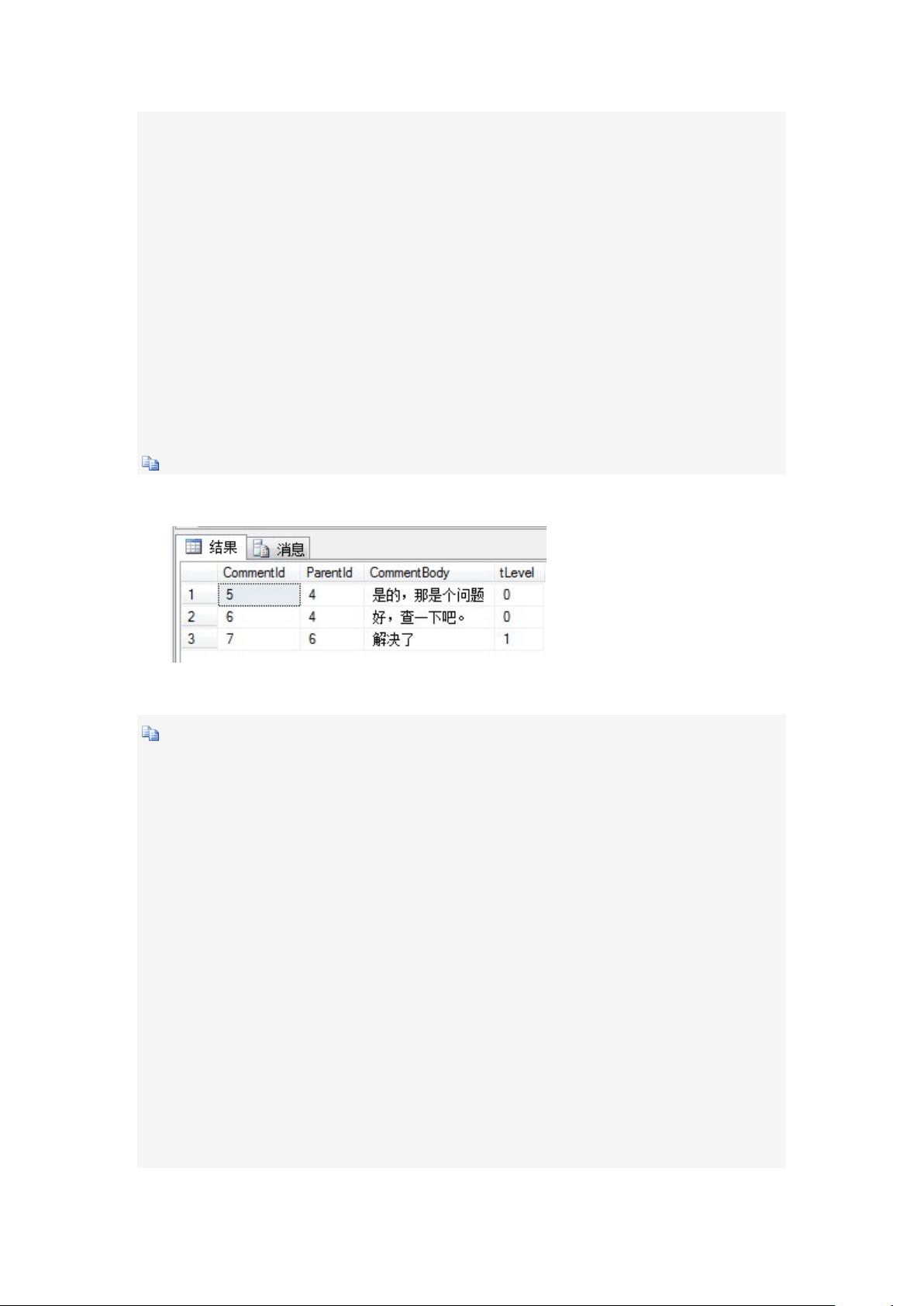
显示结果如下:
那么查询祖先节点树又如何查呢?例如查节点 6 的所有祖先节点:
WITH COMMENT_CTE(CommentId,ParentId,CommentBody,tLevel)
AS
(
--基本语句
SELECT CommentId,ParentId,CommentBody,0 AS tLevel FROM Comment
WHERE CommentId = 6
UNION ALL
SELECT c.CommentId,c.ParentId,c.CommentBody,ce.tLevel - 1 FROM
Comment AS c
INNER JOIN COMMENT_CTE AS ce --递归查询
ON ce.ParentId = c.CommentId
where ce.CommentId <> ce.ParentId
)
SELECT * FROM COMMENT_CTE ORDER BY CommentId ASC
剩余13页未读,继续阅读
2022-08-08 上传
2018-03-04 上传
2008-01-24 上传
2012-05-23 上传
2018-02-24 上传
2013-08-16 上传
2015-08-22 上传
2024-06-17 上传
2021-08-07 上传

丛乐
- 粉丝: 37
- 资源: 312
 我的内容管理
展开
我的内容管理
展开







最新资源
- StarModAPI: StarMade 模组开发的Java API工具包
- PHP疫情上报管理系统开发与数据库实现详解
- 中秋节特献:明月祝福Flash动画素材
- Java GUI界面RPi-kee_Pilot:RPi-kee专用控制工具
- 电脑端APK信息提取工具APK Messenger功能介绍
- 探索矩阵连乘算法在C++中的应用
- Airflow教程:入门到工作流程创建
- MIP在Matlab中实现黑白图像处理的开源解决方案
- 图像切割感知分组框架:Matlab中的PG-framework实现
- 计算机科学中的经典算法与应用场景解析
- MiniZinc 编译器:高效解决离散优化问题
- MATLAB工具用于测量静态接触角的开源代码解析
- Python网络服务器项目合作指南
- 使用Matlab实现基础水族馆鱼类跟踪的代码解析
- vagga:基于Rust的用户空间容器化开发工具
- PPAP: 多语言支持的PHP邮政地址解析器项目
