大规模强化学习中的值函数近似法
需积分: 0 44 浏览量
更新于2024-08-05
收藏 1.15MB PDF 举报
"值函数近似法在强化学习中扮演着重要的角色,特别是在处理大规模问题时。这种方法通过构建近似函数来代替传统的表格方法,解决了存储和计算效率的问题。"
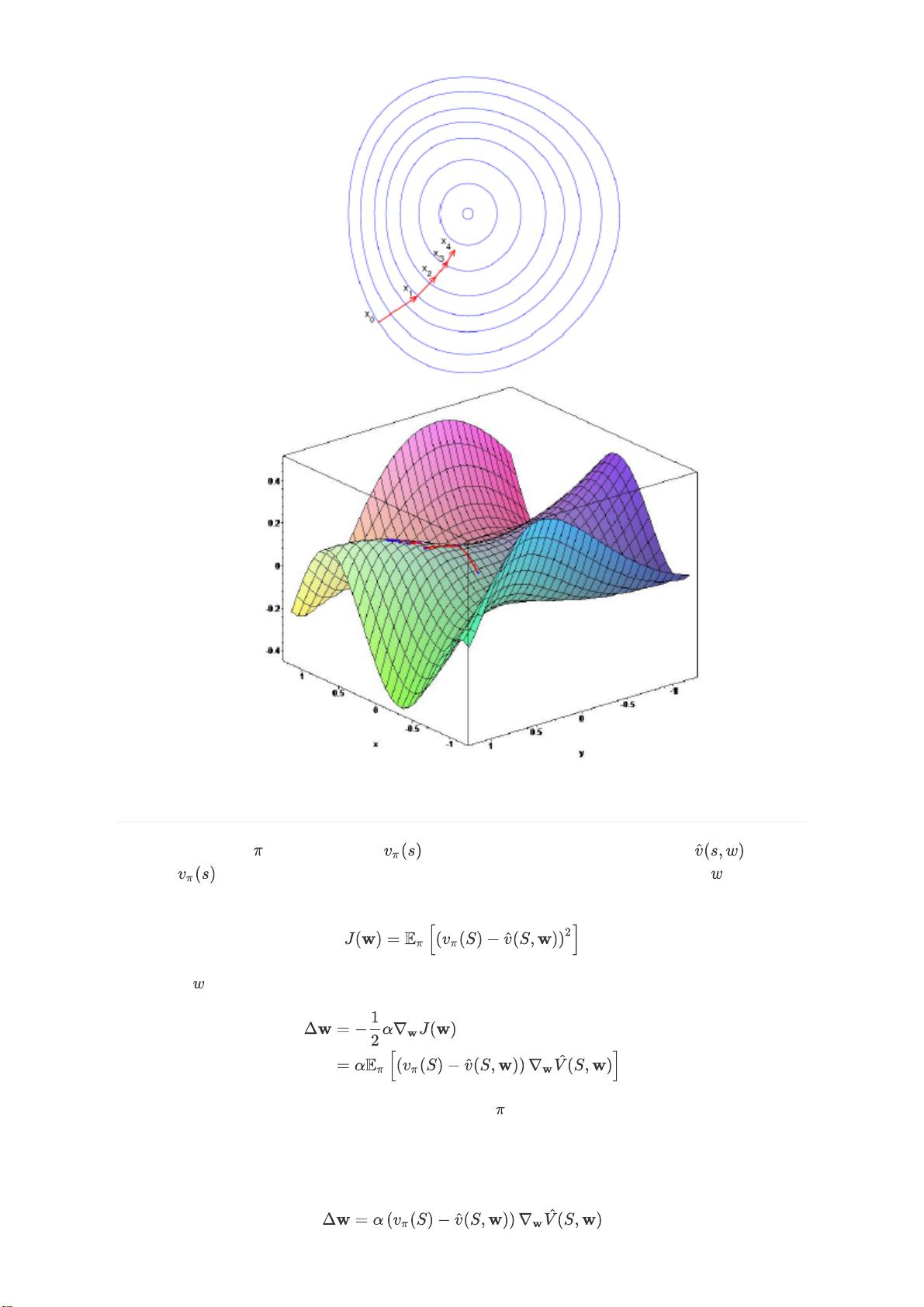
值函数近似法主要应用于那些状态空间过于庞大的强化学习任务,如棋类游戏中的Backgammon和围棋,它们的状态数量巨大,无法用表格方式存储所有状态的价值。值函数近似法通过函数(如线性函数或神经网络)来近似状态值函数V(s)或动作值函数Q(s, a),使得我们可以处理不可见甚至无穷状态的情况。
函数近似主要有三种模式:
1. 输入状态,输出状态值V(s)。
2. 输入状态和动作,输出动作值Q(s, a)。
3. 输入状态,输出所有可能动作的Q值。
选择的近似函数类型多样,包括线性函数、神经网络、决策树、最近邻算法等。在可微分的近似函数中,线性函数和神经网络是最常见的选择,因为它们能够适应强化学习环境中非静态和非独立同分布的数据特性。
优化过程中,常用的目标函数是均方误差(MSE),用于衡量Q网络预测值与实际目标值的差距。优化算法常常采用梯度下降法,其中目标函数T关于参数θ的梯度表示了参数调整的方向。学习率α决定了每次参数更新的步长。随机梯度下降是梯度下降的一个变种,它在每次迭代时只使用一个样本的梯度信息,适合处理大规模数据集,尤其是在数据非独立同分布的情况下。
在实际操作中,强化学习算法会从经验池中抽取数据,根据固定的旧参数计算Q值,并利用这些数据更新Q网络的参数,以逐渐减小目标函数MSE,从而逐步优化Q函数的近似精度。这个过程可以是基于蒙特卡洛(MC)方法,也可以是基于时间差分(TD)学习,例如TD(λ)或Q-learning。
值函数近似法是强化学习在解决大规模复杂问题时的关键技术,它通过函数近似减少了存储需求,提高了学习效率,而且通过梯度下降等优化算法不断改进近似函数,使得在动态和非静态的环境中也能有效地学习最优策略。
剩余11页未读,继续阅读
189 浏览量
2020-02-13 上传
2021-10-11 上传
2021-10-02 上传
138 浏览量
126 浏览量
175 浏览量
点击了解资源详情
点击了解资源详情

ai
- 粉丝: 873
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB函数实现箭头键控制循环开关示例
- Swift自动布局演示与高级工具应用解析
- Expo CLI取代exp:命令行界面技术新变革
- 鸢尾花卉数据集:分类实验与多重变量分析
- AR9344芯片技术手册下载,WLAN平台首选SoC
- 揭开JavaScript世界中的蝙蝠侠之谜
- ngx-dynamic-hooks:动态插入Angular组件至DOM的新技术
- CppHeaderParser:Python库解析C++头文件生成数据结构
- MATLAB百分比进度显示功能开发
- Unity2D跳跃游戏示例源码解析
- libfastcommon-1.0.40:搭建Linux基础服务与分布式存储
- HTML技术分享:virgil1996.github.io个人博客解析
- 小程序canvas画板功能详解:拖拽编辑与元素导出
- Matlab开发工具Annoyatron:数学优化的挑战
- 万泽·德·罗伯特:Python在BA_Wanze项目中的应用
- Jiq:使用jq进行交互式JSON数据查询的命令行工具
