神经网络架构:从零开始的自然语言处理
需积分: 31 140 浏览量
更新于2024-07-21
收藏 415KB PDF 举报
本文档探讨了"自然语言处理(几乎)从零开始"这一主题,由Ronan Collobert等人在2011年的《机器学习研究》期刊上发表。论文的核心内容是提出了一种统一的神经网络架构和学习算法,旨在解决多种自然语言处理任务,如词性标注、 chunking、命名实体识别以及语义角色标注。作者强调了这种方法的灵活性,旨在减少对特定任务的工程化设计依赖,转而通过大量未标注训练数据学习内在表示。
传统的自然语言处理方法通常依赖于人为构建的特征,这些特征针对每项任务进行了精细优化。然而,该研究者们试图打破这种模式,开发出一个系统,能够自动从大量文本数据中学习,而不是依赖于预先定义的特征。这种方法的主要优点在于其通用性和潜在的泛化能力,能够在没有或较少人工干预的情况下,提高系统的性能和适应性。
文章的亮点在于构建了一个开源的词性标注系统,该系统展示了在无需过多特定任务特化的前提下,仍能达到相当不错的性能。这种方法挑战了传统NLP中的专业知识局限,为开发更加高效和灵活的自然语言处理工具开辟了新的途径。此外,该研究也为后续的深度学习在NLP领域的进一步发展奠定了基础,尤其是在无监督或弱监督学习方面,为如何利用大数据驱动模型学习提供了有价值的思路。通过阅读这篇论文,读者将深入了解如何运用神经网络技术来处理自然语言,并理解在实际应用中如何平衡模型的通用性和任务特定优化。
COLLOBERT, WESTON, BOTTOU, KARLEN, KAVUKCUOGLU AND KUKSA
Input Sentence
Lookup Table
Convolution
Max Over Time
Linear
HardTanh
Linear
Text The cat sat on the mat
Feature 1
w
1
1
w
1
2
. . .
w
1
N
.
.
.
Feature K
w
K
1
w
K
2
. . .
w
K
N
LT
W
1
xx
xx
xx
xx
xx
xx
xx
xx
xx
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
.
.
.
LT
W
K
xx
xx
xx
xx
xx
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
max(·)
M
2
× ·
M
3
× ·
d
Padding
Padding
n
1
hu
M
1
× ·
xxxxxxxxxxxxxxxxxxxx
n
1
hu
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
n
2
hu
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxx
n
3
hu
= #tags
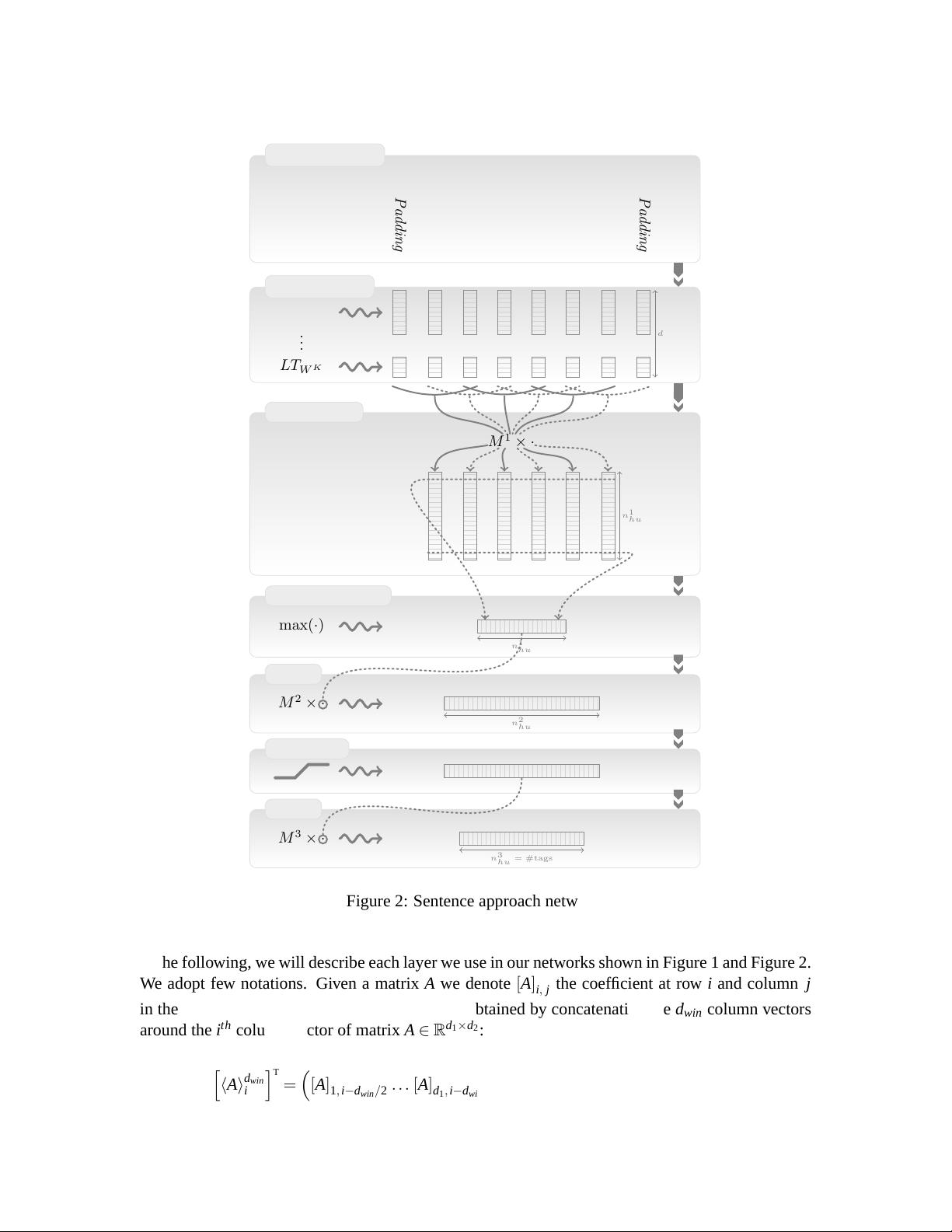
Figure 2: Sentence approach network.
In the following, we will describe each layer we use in our networks shown in Figure 1 and Figure 2.
We adopt few notations. Given a matrix A we denote [A]
i, j
the coefficient at row i and column j
in the matrix. We also denote hAi
d
win
i
the vector obtained by concatenating the d
win
column vectors
around the i
th
column vector of matrix A ∈ R
d
1
×d
2
:
h
hAi
d
win
i
i
T
=
[A]
1,i−d
win
/2
... [A]
d
1
,i−d
win
/2
, . . . , [A]
1,i+d
win
/2
... [A]
d
1
,i+d
win
/2
.
2500

剩余44页未读,继续阅读
2019-04-12 上传
2016-07-25 上传
点击了解资源详情
2024-10-17 上传
2024-10-17 上传

小白vc
- 粉丝: 7
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
