[Practical Guide]: Building a GAN Model from Scratch: Step-by-Step Optimization for Your First AI Project
发布时间: 2024-09-15 16:27:18 阅读量: 49 订阅数: 31 

java笔试试题及答案-Android-Project-from-Scratch-Guide:Android-Project-from-Scr
# Chapter 1: Introduction to Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) represent a groundbreaking technology in the field of deep learning. They consist of two neural networks—the generator and the discriminator—engaging in a game of counterfeiting and discernment, which enables the generator to produce increasingly realistic data samples. From simple image generation to complex style transfer, GANs have become a significant force in advancing the field of artificial intelligence. This chapter provides a brief overview of the development background, basic concepts, and the broad applications of GANs across various domains.
A GAN model is an unsupervised learning method whose core idea originates from the adversarial concept in game theory, where the quality of generated data is improved through the continuous rivalry between the generator and the discriminator. The generator's role is to produce samples that are as close as possible to the real data distribution, while the discriminator attempts to distinguish between real data and the fake data generated by the generator. Through this adversarial process, GANs capture the distribution characteristics of data and generate high-quality samples.
As a cutting-edge area in AI technology, GANs have attracted widespread attention in the academic community and are gradually being applied in the industrial sector, bringing revolutionary changes to multiple fields such as image processing and speech synthesis. Understanding the basic principles and working mechanisms of GANs is essential knowledge for engineers and technicians looking to delve deeply into AI.
# Chapter 2: Theoretical Foundations of the GAN Model
### 2.1 Core Components of GAN
#### 2.1.1 Principles and Functions of the Generator
The generator is the component in the GAN model responsible for generating data. Its core function involves mapping a random noise vector z to data space through a neural network, producing fake data that looks like real data. During training, the generator's goal is to continuously improve the quality of the generated fake data, making it indistinguishable from the real data by the discriminator.
**Generator Working Mechanism**:
1. **Input Noise Vector z**: The generator's input is typically a random noise vector drawn from a certain distribution, with the vector's dimensions related to the type of data being generated. For instance, in image generation, the noise vector might be a sample from a Gaussian distribution.
2. **Neural Network Mapping**: A multi-layer neural network converts the noise vector z into fake data within data space. The number of layers, types, and structural design of the network will directly affect the quality of the generated data.
3. **Activation Function**: Non-linear activation functions like ReLU, Tanh, etc., are used during the mapping process to enhance the network's expressive power.
4. **Output Layer**: The output layer is usually designed according to the type of data being generated. For example, in image generation, the output layer might use the sigmoid function to constrain output values within the range [0,1].
**Generator's Functions**:
The primary functions of the generator include:
1. **Data Augmentation**: In situations where data is scarce, the generator can produce a large number of fake data to increase the diversity of the dataset, thereby enhancing the model's generalization capabilities.
2. **Feature Extraction**: As the generator learns the mapping from noise vectors to real data distributions, it also learns the intrinsic feature representations of the data. This is particularly valuable in unsupervised and semi-supervised learning.
**Code Example** (Assuming a simple neural network implementation of the generator):
```python
import tensorflow as tf
from tensorflow.keras import layers
def build_generator(z_dim):
model = tf.keras.Sequential()
model.add(layers.Dense(128, input_dim=z_dim))
model.add(layers.LeakyReLU(alpha=0.01))
model.add(layers.Dense(28 * 28 * 1, activation='tanh'))
model.add(layers.Reshape((28, 28, 1)))
return model
# Building the generator model
generator = build_generator(z_dim=100)
```
**Parameter Explanation and Execution Logic Description**:
- `input_dim` refers to the dimension of the input noise vector.
- The `Dense` layer represents a fully connected layer.
- `LeakyReLU` is used as the activation function to prevent the vanishing gradient problem.
- The output layer uses the `tanh` activation function and reshapes to a 28x28x1 shape, simulating the shape of MNIST handwritten digits.
- The built generator model can be further used for training within a GAN model.
#### 2.1.2 Discriminator Working Mechanism
The discriminator is another core component of the GAN, tasked with distinguishing the data generated by the generator from real data. The discriminator can be considered a binary classifier whose input is a data sample, and the output is the probability of this sample coming from the real data distribution.
**Discriminator Working Mechanism**:
1. **Input Data**: The discriminator accepts data samples from real data or generated by the generator.
2. **Neural Network Classification**: Through a convolutional neural network (CNN) structure, the input sample undergoes feature extraction and is mapped to the interval [0,1], representing the probability of the sample being real.
3. **Activation Function**: The sigmoid activation function is commonly used to convert output values to probabilities.
4. **Binary Loss**: The discriminator is trained with binary cross-entropy loss functions to enhance the ability to differentiate between real and fake data.
**Discriminator's Functions**:
- **Data Quality Evaluation**: The discriminator provides feedback to the generator, indirectly prompting the generator to produce higher-quality data through improved discernment.
- **Model Training Supervision**: During GAN training, the discriminator's loss serves as a guiding signal for the generator's training, updating the generator's parameters through backpropagation to fool the discriminator.
**Code Example** (Assuming a simple CNN implementation of the discriminator):
```python
def build_discriminator(img_shape):
model = tf.keras.Sequential()
model.add(layers.Flatten(input_shape=img_shape))
model.add(layers.Dense(128))
model.add(layers.LeakyReLU(alpha=0.01))
model.add(layers.Dense(1, activation='sigmoid'))
return model
# Building the discriminator model
discriminator = build_discriminator(img_shape=(28, 28, 1))
```
**Parameter Explanation and Execution Logic Description**:
- `img_shape` is the shape of the input image, assumed here to be (28, 28, 1) for the MNIST dataset.
- The `Flatten` layer converts the input image into a one-dimensional vector.
- Subsequent `Dense` and `LeakyReLU` layers are used for feature extraction and non-linear transformation.
- The output layer uses the `sigmoid` activation function to output a probability value representing the likelihood that the input sample is real.
- The generated discriminator model will be used in subsequent GAN training to evaluate the fake data generated by the generator.
### 2.2 Mathematical Principles of GAN
#### 2.2.1 Probability Distribution and Density Functions
GAN's core goal is to approximate the true data distribution through an adversarial approach. The probability distribution is the statistical pattern of data point occurrences within a dataset, represented by the probability density function (PDF).
**Probability Distribution**:
- In machine learning, understanding the distribution of data is crucial for model building. GAN learns the distribution characteristics of data through the competitive training of two networks.
**Probability Density Function (PDF)**:
- The PDF describes the probability density of a continuous random variable around a certain value point.
- For discrete random variables, the corresponding concept is the probability mass function (PMF).
**Adversarial Process of Generator and Discriminator**:
- The generator attempts to generate data distribution similar to real data.
- The discriminator learns to distinguish between data generated by the generator and real data.
- This adversarial relationship can be seen as a "minimax" problem, where the generator tries to minimize the probability of its generated data being recognized as fake, while the discriminator tries to maximize this probability.
### 2.2.2 Concept and Importance of Adversarial Loss Function
In GANs, the adversarial loss function is a critical factor in continuously driving the generator and discriminator to oppose and progress. The loss function defines the objective of model training, guiding the direction of model parameter updates.
**Adversarial Loss Function**:
- The adversarial loss function typically consists of two parts: one for the generator's loss, and one for the discriminator's loss.
- For the generator, its loss is to minimize the probability of the discriminator recognizing fake data, i.e., maximizing the probability of the discriminator making mistakes.
- For the discriminator, its loss is to accurately distinguish between real and fake data, i.e., maximizing the accuracy of discrimination.
**Importance**:
- The adversarial loss function is the only quantity that needs optimization during GAN training, reflecting the adversarial relationship between the generator and discriminator.
- Properly designing the adversarial loss function is crucial for ensuring model performance. The loss function needs to balance the progress of the generator and discriminator, avoiding mode collapse issues.
### 2.3 Types of GANs and Their Applications
#### 2.3.1 Introduction to Mainstream GAN Models like DCGAN, StyleGAN, etc.
Since the introduction of GAN, many variant models have been proposed, such as DCGAN (Deep Convolutional Generative Adversarial Networks), StyleGAN, etc. These models address some issues of traditional GANs through architectural innovations and have achieved significant results in tasks such as image generation.
**DCGAN**:
- DCGAN is one of the earliest and significantly influential GAN variants.
- It incorporates convolutional neural network (CNN) structures into GANs, using transposed convolutional layers for the generator's upsampling.
- DCGAN improves model stability by employing batch normalization and fully convolutional structures.
**StyleGAN**:
- StyleGAN represents a significant advancement in GAN models, particularly in image generation breakthroughs.
- It introduces the concept of style control, achieving fine adjustments to image styles.
- StyleGAN employs a progressive generation structure, gradually building images from low to high resolution, and uses a mapping network to convert noise into potential space representations, allowing for more detailed feature control.
#### 2.3.2 Case Analysis on Applications such as Image Generation and Style Transfer
GANs have been widely applied in image processing tasks such as image generation, style transfer, image restoration, and super-resolution.
**Image Generation**:
- GANs can generate realistic images for applications in artistic creation, game character design, virtual reality, and more.
- Use cases include lifelike portraits and natural landscapes.
**Style Transfer**:
- GANs can transfer various art styles onto any content image in style transfer tasks.
- Use cases include applying Van Gogh's, Picasso's, and other masters' styles to modern photographs.
In this chapter, we have delved into the core components, mathematical principles, types, and application scenarios of GANs. In the next chapter, we will explore how to build your first GAN model and introduce practical techniques during the implementation process.
# Chapter 3: Building Your First GAN Model
## 3.1 Preparing Development Environment and Tools
### 3.1.1 Introduction to Python Programming Language and TensorFlow Framework
Python, as one of the most popular programming languages today, is widely used in machine learning and deep learning due to its concise syntax and robust library support. In the development of GAN models, Python offers a plethora of libraries and frameworks, among which TensorFlow is an open-source library developed by Google for high-performance numerical computing. Its standout advantage is flexibility, allowing researchers to build complex neural network models by defining computational graphs.
TensorFlow is designed with scalability in mind, making it highly popular in both industrial and academic circles. Starting from version 2.0, TensorFlow introduced the Eager Execution mode, making the programming experience more intuitive and the code execution more similar to traditional programming languages. Additionally, TensorFlow provides strong community support and a wealth of pre-trained models, significantly lowering the entry barriers.
### 3.1.2 GPU Acceleration and CUDA Configuration
Machine learning, especially deep learning projects, require very high computational resources, particularly for training large GAN models. Therefore, utilizing GPU (Graphics Processing Unit) for accelerating deep learning model training is common practice. ***
***erform deep learning model training with GPU, one typically needs to use the CUDA toolkit. CUDA is a parallel computing platform and programming model developed by NVIDIA, allowing developers to use NVIDIA GPUs for general-purpose computing. When configuring CUDA, it is essential to ensure compatibility with your NVIDIA drivers, operating system, and TensorFlow version.
Below is an example code block for configuring TensorFlow to use GPU on a Linux system:
```python
# Installing TensorFlow GPU edition
pip install tensorflow-gpu
# Verifying CUDA installation
import tensorflow as tf
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
```
## 3.2 Coding a GAN Model from Scratch
### 3.2.1 Designing Generator and Discriminator Network Structures
The generator and discriminator are the two core parts of a GAN model. The generator's job is to create fake data that closely resembles real data, while the discriminator's task is to differentiate between input data from the real dataset and data generated by the generator.
When designing network structures, layers from deep learning frameworks are typically used to construct them. Taking TensorFlow as an example, various layers from `tf.keras.layers` can be used to build the generator and discriminator. Below is a simple code example demonstrating how to define a simple generator and discriminator model using TensorFlow's Keras API:
```python
import tensorflow as tf
# Defining the generator model
def build_generator(z_dim):
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_dim=z_dim),
tf.keras.layers.LeakyReLU(alpha=0.01),
tf.keras.layers.Dense(28*28*1, activation='tanh'),
tf.keras.layers.Reshape((28, 28, 1))
])
return model
# Defining the discriminator model
def build_discriminator(img_shape):
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=img_shape),
tf.keras.layers.Dense(128),
tf.keras.layers.LeakyReLU(alpha=0.01),
tf.keras.layers.Dense(1, activation='sigmoid')
])
return model
```
In the above code, we define a simple fully connected neural network as the generator and discriminator. The generator starts with a dense layer to map the input noise vector `z` to a higher-dimensional space, followed by the non-linear transformation of the `LeakyReLU` activation function, and finally outputs image data through a fully connected layer. The discriminator is similar to the generator, but its task is to determine whether the input image is real or generated by the generator.
### 3.2.2 Implementing Training Loops and Model Saving
After designing the generator and discriminator, the next step is to implement the GAN training loop. The training loop includes alternating training of the generator and discriminator until they reach a balanced state.
Below is a code example demonstrating the GAN training loop implementation:
```python
# GAN model training function
def train_gan(gan, dataset, batch_size, epochs):
generator, discriminator = gan
for epoch in range(epochs):
for batch in dataset:
noise = np.random.normal(0, 1, (batch_size, z_dim))
fake = generator.predict(noise)
real = batch
discriminator.train_on_batch(real, np.ones((batch_size, 1)))
discriminator.train_on_batch(fake, np.zeros((batch_size, 1)))
noise = np.random.normal(0, 1, (batch_size, z_dim))
gan.train_on_batch(noise, np.ones((batch_size, 1)))
# Setting hyperparameters
batch_size = 32
epochs = 10000
z_dim = 100
# Creating and compiling the model
discriminator = build_discriminator((28, 28, 1))
generator = build_generator(z_dim)
gan = tf.keras.Sequential([generator, discriminator])
# Compiling the discriminator
***pile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam())
# Compiling***
***pile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam())
# Preparing data
(X_train, y_train), (_, _) = tf.keras.datasets.mnist.load_data()
X_train = X_train / 255.0
X_train = np.expand_dims(X_train, axis=-1)
dataset = tf.data.Dataset.from_tensor_slices(X_train).shuffle(50000).batch(batch_size)
# Training the model
train_gan(gan, dataset, batch_size, epochs)
```
In this code snippet, we first create instances of the generator and discriminator and combine them into a `Sequential` model representing the entire GAN network. We then compile both the discriminator and the GAN model separately and prepare the dataset. Finally, we define a training function `train_gan` responsible for executing the training loop. During training, we generate a batch of fake data and use the discriminator to classify the fake and real data.
## 3.3 Model Training and Result Evaluation
### 3.3.1 Monitoring and Debugging Training Process
Monitoring the GAN training process is crucial. Visualizing generated images can help us understand the current quality of model generation and determine whether network structure or hyperparameter adjustments are needed.
TensorBoard is a visualization tool provided by TensorFlow that helps monitor various data during model training. When training GANs, we typically focus on the quality of generated images and changes in the loss function.
Below is a code example of how to use TensorBoard to monitor the GAN training process:
```python
# Training the model and saving TensorBoard logs
history = gan.fit(dataset, epochs=1000, callbacks=[tf.keras.callbacks.TensorBoard(log_dir='./logs')])
```
### 3.3.2 Evaluation Metrics for Model Performance
GAN models do not have direct evaluation metrics like accuracy or loss values, making performance evaluation challenging. Typically, we assess the model's quality by visually inspecting the generated images. Additionally, there are some indirect evaluation methods, such as the Inception Score and Fréchet Inception Distance (FID), which measure the diversity and quality of generated images to evaluate GAN performance.
The Inception Score (IS) uses a pre-trained Inception model to evaluate the category diversity of generated images. A higher IS indicates that the generated images have more category diversity and clarity.
The Fréchet Inception Distance (FID) is a method for measuring the similarity between the real and generated data distributions. A lower FID value indicates that the generated images are visually closer to real images.
To implement these evaluation methods, we can use existing libraries, such as `fid_score`, to calculate FID values.
```python
import fid_score
real_images = ...
fake_images = ...
fid_value = fid_score.calculate_fretchet_inception_distance(real_images, fake_images)
print("FID score:", fid_value)
```
This concludes the detailed introduction of this chapter. In the upcoming Chapter 4, we will delve into optimization techniques for GAN models, including hyperparameter tuning, avoiding common issues during training, and strategies for model extension and innovation.
# Chapter 4: Practical Techniques for Optimizing GAN Models
## 4.1 Hyperparameter Tuning and Model Optimization
### 4.1.1 Strategies for Adjusting Learning Rate and Batch Size
During the training process of deep learning models, the choice of hyperparameters significantly affects model performance and convergence speed. For Generative Adversarial Networks (GANs), learning rate and batch size are key hyperparameters affecting the model training process.
**Learning Rate** is the step size for updating model parameters, determining the magnitude of parameter updates during the gradient descent process. If the learning rate is set too low, the model training process will be very slow, and may even cause the model to converge to local optima. Conversely, if the learning rate is set too high, the model may not converge and could even diverge.
In GANs, since the generator and discriminator are trained alternately, they are sensitive to the learning rate differently, so it may be necessary to adjust the learning rates for the two networks separately. Sometimes, using different learning rate strategies, such as learning rate decay or cyclical learning rates, can improve model performance and stability.
**Batch Size** defines the number of samples used to train the model in one iteration. A smaller batch size means less memory usage, which may result in more frequent parameter updates and increase the randomness of model training. However, too small a batch size could lead to larger estimated gradient variance, affecting the model's convergence.
In general, a larger batch size can provide more stable gradient estimates but will consume more memory resources. In GAN training, if the batch size is too small, it may affect the stability of the model and the quality of the generated samples. In practice, finding a balance is key.
**Code Example**:
```python
# Assuming we are using the PyTorch framework
# Setting learning rate and batch size
learning_rate = 0.0002
batch_size = 64
# Using Adam optimizer, one of the commonly used optimizers for GAN training
optimizer_G = torch.optim.Adam(generator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
```
### 4.1.2 Selection and Adjustment of Loss Functions
In GANs, the choice of loss functions is also crucial. Traditionally, the discriminator's loss function is based on cross-entropy loss, while the generator's loss is the logarithmic loss of the discriminator's output. However, as GAN research has developed, many new loss functions have been proposed to address issues of stability and mode collapse during training.
**Vanilla GAN** loss function's simple form is for the discriminator to optimize the maximization of the probability of distinguishing between real and generated data, while the generator optimizes the minimization of the probability of its generated data being misjudged as real data.
**Wasserstein GAN (WGAN)** introduces the Wasserstein distance to measure the distance between the real distribution and the generated distribution. WGAN's loss function has stronger gradient signals and better training stability.
**Least Squares GAN (LSGAN)** reformulates the loss function of both the generator and discriminator to a least squares form, capable of generating higher-quality images.
In practice, tuning the loss function may involve experimenting with different loss functions and adjusting the weights within the loss functions.
## 4.2 Avoiding Common Issues During Training
### 4.2.1 Identifying and Addressing Mode Collapse
Mode collapse is a common problem in GAN training, occurring when the generator starts producing almost identical or repetitive samples. This typically happens because the generator has found a shortcut to "fool" the discriminator, leading to a decrease in both the generator's diversity and the discriminator's discriminative ability.
**Identifying Mode Collapse**: If, during training, the generated samples look very similar, or if the discriminator's error rate suddenly drops significantly, this could be a sign of mode collapse.
**Countermeasures**:
- **Introduce Regularization**: For example, adding a regularization term to the generator's loss function, such as gradient penalty, to stabilize the training process.
- **Use WGAN**: WGAN has inherent resistance to mode collapse because its loss function encourages the discriminator to provide more granular scores.
- **Add Noise**: Introduce noise into the discriminator's training data to prevent the generator from finding patterns that are easily misclassified.
- **Multiple Discriminators**: Use multiple discriminators to evaluate the generated samples, making it difficult for the generator to deceive all discriminators with a single strategy.
### 4.2.2 Techniques and Practices for Stable Training
To improve the stability of GAN model training, here are some practical tips:
- **Early Stopping**: Stop training when the model's performance no longer improves or begins to decline.
- **Gradient Clipping**: Limit the maximum value of gradients to prevent gradient explosion during training.
- **Incremental Training**: Start training with a smaller amount of data and gradually increase the data volume.
- **Multi-Scale Training**: Train GANs at different resolutions, starting with low resolution and gradually transitioning to high resolution.
## 4.3 Model Extension and Innovation
### 4.3.1 Conditional GAN (cGAN) and Information Control
Conditional GAN (cGAN) is an extended GAN model that allows the introduction of conditional information during the generation process, enabling the generator to produce more diverse samples based on external conditions.
For example, in image generation, conditional information can be the class label, style, text description, etc., of the image. The training goal of cGAN is for the generator to produce samples that match the given condition when provided with specific conditions.
In cGAN, the generator's input includes not only random noise but also conditional information. The discriminator is responsible for determining whether a sample under given conditions is real or generated by the generator.
cGAN has achieved success in many applications, including image-to-image translation, data augmentation, and style transfer.
### 4.3.2 Transfer Learning and Pretraining Techniques for Models
Transfer learning is a significant technique in deep learning that allows us to apply knowledge learned from one task to another related task. For GANs, transfer learning can be implemented through pretrained models to accelerate model convergence and improve performance on specific tasks.
**Pretraining Techniques**:
- **Freezing Pretrained Model Weights**: In the early stages of transfer learning, only train the top layer weights of the new model while keeping the pretrained model weights unchanged.
- **Fine-tuning Pretrained Models**: When the new task has a certain similarity to the original task, gradually unfreeze certain layers of the pretrained model and train them together with the top layer weights.
- **Feature Extraction**: Use the pretrained model as a feature extractor to extract feature vectors from new data, and then use these features to train a simple classifier or regressor.
In practice, transfer learning and pretrained models can not only save training time but also improve model performance on small datasets.
# Chapter 5: GAN Project Case Studies
## 5.1 Practical Flow of Image Generation Project
### 5.1.1 Data Preparation and Preprocessing
Before undertaking an image generation project, data preparation and preprocessing are indispensable steps. High-quality data can significantly enhance the model's generation effects. For GAN projects, the data should meet the following requirements:
- **Diversity**: The dataset should include a variety of images so that the model can learn rich features.
- **Consistency**: Ensure that the style and theme of images in the dataset are similar, focusing on specific types of image generation.
- **Preprocessing**: Images typically need to undergo steps such as cropping, resizing, and normalization.
Below is a simple code example illustrating how to preprocess image data:
```python
import tensorflow as tf
def preprocess_image(image_path, target_size=(64, 64)):
# Load image file
image = tf.io.read_file(image_path)
image = tf.image.decode_image(image, channels=3)
# Resize image
image = tf.image.resize(image, target_size)
# Normalize image pixel values
image = image / 255.0
return image
# Assuming there is a list of image paths
image_paths = ['path/to/image1.jpg', 'path/to/image2.jpg', ...]
# Preprocess image data
preprocessed_images = [preprocess_image(path) for path in image_paths]
```
The preprocessed data can be used to build dataset objects, which can then be loaded into the GAN model for training.
### 5.1.2 Model Training, Tuning, and Testing
When training a GAN model, it is typically necessary to train the generator and discriminator simultaneously within the same loop. Below is a simplified process describing how to train models using TensorFlow:
```python
def train_step(generator, discriminator, generator_optimizer, discriminator_optimizer, image_batch):
noise = tf.random.normal([batch_size, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(image_batch, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
# In the training loop, we need to iterate through the training steps multiple times
for epoch in range(num_epochs):
for image_batch in dataset:
train_step(generator, discriminator, generator_optimizer, discriminator_optimizer, image_batch)
```
During training, it may be necessary to tune and check the model's performance multiple times. This includes adjusting the learning rate, batch size, and using different loss functions. By monitoring the generator and discriminator losses, we can determine whether the model is beginning to converge.
## 5.2 Project Optimization and Outcome Presentation
### 5.2.1 Identifying and Overcoming Project Bottlenecks
In a project, we may encounter bottlenecks such as low-quality images generated by the model, mode collapse during training, or excessively long training times. Identifying and overcoming these bottlenecks is key:
- **Monitoring and Analysis**: Observe loss values and generated images during the training process, using visualization tools to aid in analyzing model behavior.
- **Debugging and Adjustment**: Make targeted adjustments based on observed issues, such as adjusting the model architecture, hyperparameters, or training strategies.
### 5.2.2 Outcome Presentation and Business Application Prospects
After completing a GAN project, it is necessary to showcase the generated high-quality images to relevant stakeholders, which can help obtain feedback and promote further project development. Examples of how to showcase the outcomes include:
- **Online Gallery**: Build a website to display an online gallery of generated images, allowing user interaction.
- **Reports and Presentations**: Prepare documentation and presentation materials to detail the project's process, results, and potential application scenarios.
Potential business application prospects may include:
- **Artistic Creation**: Automatically generating artworks to assist artists in their creative processes.
- **Product Design**: Using for designing styles of new products, clothing, and accessories.
- **Games and Film**: Generating game scenes, characters, and special effects for film and television.
When presenting outcomes and discussing business applications, it is essential to clearly communicate the innovative value brought by GAN technology and its future development potential.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【深度分析】:Windows 11非旺玖PL2303驱动问题的终极解决之道
# 摘要
随着Windows 11操作系统的推出,PL2303芯片及其驱动程序的兼容性问题逐渐浮出水面,成为技术维护的新挑战。本文首先概述了Windows 11中的驱动问题,随后对PL2303芯片的功能、工作原理以及驱动程序的重要性进行了理论分析。通过实例研究,本文深入探讨了旺玖PL2303驱动问题的具体案例、更新流程和兼容性测试,并提出了多种解决和优化方案。文章最后讨论了预防措施和对Windows 11驱动问题未来发展的展望,强调了系统更新、第三方工具使用及长期维护策略的重要性。
# 关键字
Windows 11;PL2303芯片;驱动兼容性;问题分析;解决方案;预防措施
参考资源链接:
【Chem3D个性定制教程】:打造独一无二的氢原子与孤对电子视觉效果

# 摘要
Chem3D软件作为一种强大的分子建模工具,在化学教育和科研领域中具有广泛的应用。本文首先介绍了Chem3D软件的基础知识和定制入门,然后深入探讨了氢原子模型的定制技巧,包括视觉定制和高级效果实现。接着,本文详细阐述了孤对电子视觉效果的理论基础、定制方法和互动设计。最后,文章通过多个实例展示了Chem3D定制效果在实践应用中的重要性,并探讨了其在教学和科研中的
【网格工具选择指南】:对比分析网格划分工具与技术
# 摘要
本文全面综述了网格划分工具与技术,首先介绍了网格划分的基本概念及其在数值分析中的重要作用,随后详细探讨了不同网格类型的选择标准和网格划分算法的分类。文章进一步阐述了网格质量评估指标以及优化策略,并对当前流行的网格划分工具的功能特性、技术特点、集成兼容性进行了深入分析。通过工程案例的分析和性能测试,本文揭示了不同网格划分工具在实际应用中的表现与效率。最后,展望了网格划分技术的未来发展趋势,包括自动
大数据分析:处理和分析海量数据,掌握数据的真正力量

# 摘要
大数据是现代信息社会的重要资源,其分析对于企业和科学研究至关重要。本文首先阐述了大数据的概念及其分析的重要性,随后介绍了大数据处理技术基础,包括存储技术、计算框架和数据集成的ETL过程。进一步地,本文探讨了大数据分析方法论,涵盖了统计分析、数据挖掘以及机器学习的应用,并强调了可视化工具和技术的辅助作用。通过分析金融、医疗和电商社交媒体等行
内存阵列设计挑战
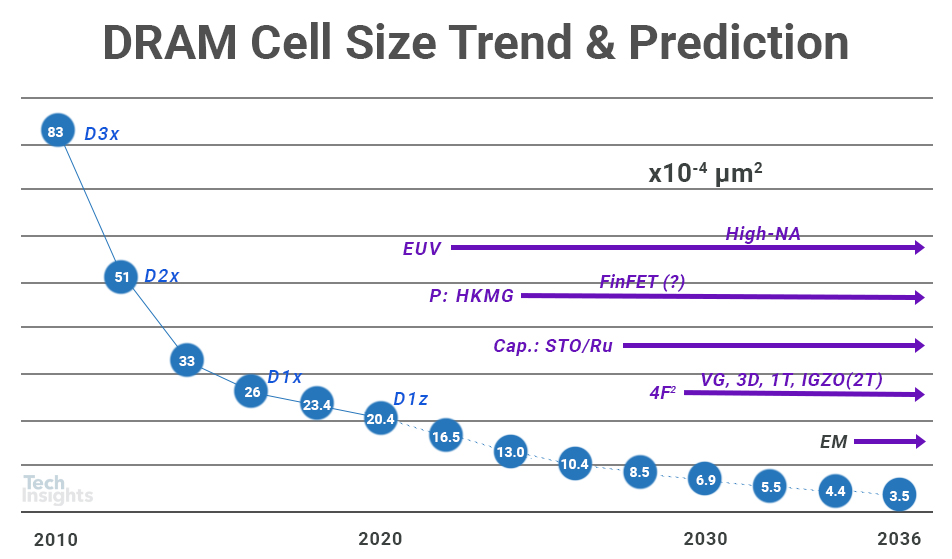
# 摘要
内存阵列技术是现代计算机系统设计的核心,它决定了系统性能、可靠性和能耗效率。本文首先概述了内存阵列技术的基础知识,随后深入探讨了其设计原理,包括工作机制、关键技术如错误检测与纠正技术(ECC)、高速缓存技术以及内存扩展和多通道技术。进一步地,本文关注性能优化的理论和实践,提出了基于系统带宽、延迟分析和多级存储层次结构影响的优化技巧。可靠性和稳定性设计的策略和测试评估方法也被详细分析,以确保内存阵列在各
【网络弹性与走线长度】:零信任架构中的关键网络设计考量

# 摘要
网络弹性和走线长度是现代网络设计的两个核心要素,它们直接影响到网络的性能、可靠性和安全性。本文首先概述了网络弹性的概念和走线长度的重要性,随后深入探讨了网络弹性的理论基础、影响因素及设
天线技术实用解读:第二版第一章习题案例实战分析

# 摘要
本论文回顾了天线技术的基础知识,通过案例分析深入探讨了天线辐射的基础问题、参数计算以及实际应用中的问题。同时,本文介绍了天
音频处理中的阶梯波发生器应用:技术深度剖析与案例研究

# 摘要
阶梯波发生器作为电子工程领域的重要组件,广泛应用于音频合成、信号处理和测试设备中。本文从阶梯波发生器的基本原理和应用出发,深入探讨了其数学定义、工作原理和不同实现方法。通过对模拟与数字电路设计的比较,以及软件实现的技巧分析,本文揭示了在音频处理领域中阶梯波独特的应用优势。此外,本文还对阶梯波发生器的
水利工程中的Flac3D应用:流体计算案例剖析

# 摘要
本文深入探讨了Flac3D在水利工程中的应用,详细介绍了Flac3D软件的理论基础、模拟技术以及流体计算的实践操作。首先,文章概述了Flac3D软件的核心原理和基本算法,强调了离散元方法(DEM)在模拟中的重要性,并对流体计算的基础理论进行了阐述。其次,通过实际案例分析,展示了如何在大坝渗流、地下水流动及渠道流体动力学等领域中建立模型、进行计算
【Quartus II 9.0功耗优化技巧】:降低FPGA功耗的5种方法

# 摘要
随着高性能计算需求的不断增长,FPGA因其可重构性和高性能成为众多应用领域的首选。然而,FPGA的功耗问题也成为设计与应用中的关键挑战。本文从FPGA功耗的来源和影响因素入手,详细探讨了静态功耗和动态功耗的类型、设计复杂性与功耗之间的关系,以及功耗与性能之间的权衡。本文着重介绍并分析了Quartus II功耗分析工具的使用方法,并针对降低FPGA功耗提出了一系列优化技巧。通过实证案
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )