【Case Study】: The Black Technology of Image Synthesis: The Powerful Applications of GAN in Reality
发布时间: 2024-09-15 16:29:46 阅读量: 25 订阅数: 43 

Controllable Image Synthesis of Industrial Data Using Stable Diffusion
# [Case Study] The Black Technology of Image Synthesis: The Powerful Applications of GAN in Reality
## 1.1 The Birth and Definition of GAN
Generative Adversarial Networks (GAN) were proposed by Ian Goodfellow in 2014 as a type of deep learning model. It achieves the generation of realistic data distributions through the adversarial learning of two networks — the generator and the discriminator. GAN has shown great potential in various fields such as image synthesis, video generation, and text generation, becoming one of the most cutting-edge AI technologies today.
## 1.2 The Basic Principles and Architecture of GAN
The core idea of GAN originates from the zero-sum game in game theory. The generator tries to produce samples that are as close to real data as possible, while the discriminator attempts to differentiate between real data and generated data. This iterative process allows the generator to continuously learn and improve the quality of the images it produces.
```python
# Example: A simple GAN code framework
class Generator:
# ...Generator definition...
class Discriminator:
# ...Discriminator definition...
# Training GAN
for epoch in range(num_epochs):
# Generator training steps
# Discriminator training steps
```
## 1.3 The Application Scope and Challenges of GAN
GAN has achieved great success in image synthesis and is widely applied in fields such as style transfer, image restoration, and data augmentation. Despite this, challenges such as unstable training, mode collapse, and imperfect evaluation standards are still issues that researchers urgently need to address.
Through an in-depth analysis of the subsequent chapters, we will explore how to apply GAN in practice and how to optimize and improve these models to play a greater role in various applications.
# 2. The Theoretical Foundation of Generative Adversarial Networks (GAN)
Generative adversarial networks (GAN) are a type of deep learning model that realizes unsupervised learning through an adversarial process. In GAN, two neural networks compete with and promote each other, ultimately making progress together. This chapter will explore the basic principles and architecture of GAN, interpret its key technologies and improvement methods, and introduce standards and metrics for evaluating GAN performance.
## 2.1 The Basic Principles and Architecture of GAN
### 2.1.1 The Working Mechanism of GAN
GAN has a very unique working mechanism. It consists of two main neural networks: the generator and the discriminator. The generator is responsible for producing fake data that is as close to real data as possible, while the discriminator is responsible for accurately distinguishing between real data and fake data. During the training process, the generator and discriminator compete with each other. The generator continuously learns and improves to produce more realistic data, while the discriminator enhances its identification ability. Through this adversarial mechanism, GAN can generate high-quality data for various fields such as image synthesis and data augmentation.
### 2.1.2 The Main Components of GAN: Generator and Discriminator
The goal of the generator is to create data that is indistinguishable from the real thing. It is usually a convolutional neural network (CNN), which learns to generate complex data distributions from random noise by repeatedly adjusting the network weights. The discriminator is a binary classifier responsible for distinguishing whether the input data comes from a real dataset or the generator. During training, the generator and discriminator are trained alternately until they reach a balanced state, at which point the discriminator cannot distinguish between real and generated data, and the generator can produce high-quality fake data.
## 2.2 Key Technologies and Improvement Methods of GAN
### 2.2.1 Loss Function and Training Stability
In the training process of GAN, the choice of loss function is crucial for the stability and final effect of the model. The original GAN uses cross-entropy loss function, but as research deepens, a series of improved loss functions have emerged, such as Wasserstein loss (WGAN) and perceptual loss. WGAN introduces the Wasserstein distance, reducing the mode collapse problem during training, making GAN training more stable. Perceptual loss uses a pre-trained convolutional neural network to measure the quality of image content, thereby improving the realism of the generated images.
### 2.2.2 Conditional GAN and Mode Collapse Problem
Conditional GAN (Conditional GAN, CGAN) introduces conditional variables on the basis of the original GAN, allowing the generation of specific category data based on the given conditional information. For example, in image synthesis, the conditional information can be labels, text descriptions, or other images, making the generated images not only realistic but also in line with the given conditions. Mode collapse (Mode Collapse) is a problem that may be encountered during GAN training, that is, the generator produces a limited number of outputs that cannot cover all possible data patterns. By introducing conditional information, the mode collapse problem can be effectively alleviated.
### 2.2.3 In-depth Understanding of GAN Variants
Since GAN was proposed, its variants have emerged in an endless stream, and each improvement has achieved significant results in specific fields. DCGAN (Deep Convolutional Generative Adversarial Networks) is the first successful case of applying convolutional neural networks to GAN. It introduces convolutional layers and deconvolutional layers, significantly improving the quality and speed of image generation. Progressive GAN further enhances the resolution and quality of images by gradually increasing the depth of the network, training GAN to generate high-resolution images. In addition, StyleGAN introduces style control, allowing the generated images to have different styles and features.
## 2.3 Evaluation Criteria and Metrics for GAN
### 2.3.1 Qualitative and Quantitative Evaluation Indicators
The evaluation of GAN models can be carried out through qualitative and quantitative methods. Qualitative evaluation usually relies on manual observation and subjective evaluation, observing whether the generated images are realistic and meaningful. Quantitative evaluation requires objective indicators, such as Inception Score (IS) and Fréchet Inception Distance (FID). IS is used to measure the diversity and quality of generated images, while FID calculates the distance between the feature distributions of real and generated images to evaluate model performance.
### 2.3.2 GAN Evaluation Strategies in Different Applications
In different application fields, GAN evaluation strategies also vary. In image synthesis, in addition to the aforementioned IS and FID, metrics such as the accuracy of image reconstruction and the consistency of content can also be used. In the field of medical imaging, evaluation standards will pay more attention to the model's ability to recognize and reproduce pathological features. In artistic creation, the creativity and novelty of the model are also important evaluation factors.
[Preview of the Next Section]
Chapter 3: Practical Applications of GAN in Image Synthesis
3.1 Image-to-Image Translation (Pix2Pix)
3.1.1 The Basic Process of Pix2Pix
3.1.2 Analysis of Pix2Pix Application Cases
3.2 Unsupervised Learning for Image Synthesis
3.2.1 Innovations of CycleGAN and Its Application
3.2.2 Style Transfer Under Unsupervised Learning
3.3 Super-Resolution and Image Enhancement
3.3.1 Principles and Effects of SRGAN and ESRGAN
3.3.2 Practical Applications of Image Denoising and Super-Resolution
# 3. Practical Applications of GAN in Image Synthesis
In this chapter, we will delve into the various practical applications of generative adversarial networks (GAN) in the field of image synthesis and discuss the specific technical details of their practice. We will start with Pix2Pix, a technique for image-to-image translation, and further explore image synthesis under unsupervised learning, as well as super-resolution and image enhancement technologies. Each section will demonstrate the practical effects and application potential of GAN in image synthesis applications through case analysis and detailed technical discussions.
## 3.1 Image-to-Image Translation (Pix2Pix)
### 3.1.1 The Basic Process of Pix2Pix
The Pix2Pix model is a classic application of GAN in the field of image-to-image translation. The basic process begins with the preparation of a pair of paired image data as a training set. For example, in the style transfer of architectural images, the training set would include a set of paired images containing original architectural photos and corresponding line drawings.
During the training process, the Pix2Pix model uses a convolutional neural network (CNN) as the generator to translate the input image (e.g., line drawings) into the target image (e.g., corresponding architectural photos). At the same time, another network serves as the discriminator to distinguish between the generated images and the real images. Through an alternating optimiz

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PSASP电力系统仿真深度剖析:模型构建至结果解读全攻略

# 摘要
PSASP电力系统仿真软件作为电力行业的重要工具,提供了从模型构建到仿真结果解读的完整流程。本论文首先概述了PSASP的基本功能及其在电力系统仿真中的应用,随后深入探讨了PSASP模型构建的基础,包括电力系统元件的建模、系统拓扑结构设计及模型参
小米mini路由器SN问题诊断与解决:专家的快速修复宝典

# 摘要
本文对小米mini路由器的序列号(SN)问题进行了全面的研究。首先概述了小米mini路由器SN问题的基本情况,然后深入分析了其硬件与固件的组成部分及其之间的关系,特别强调了固件升级过程中遇到的SN问题。随后,文章详细介绍了SN问题的诊断步骤,从初步诊断到通过网络接口进行故障排查,再到应用高级诊断技巧。针对发现的SN问题,提出了解决方案,包括软件修复和硬件更换,并强
5G网络切片技术深度剖析:基于3GPP标准的创新解决方案
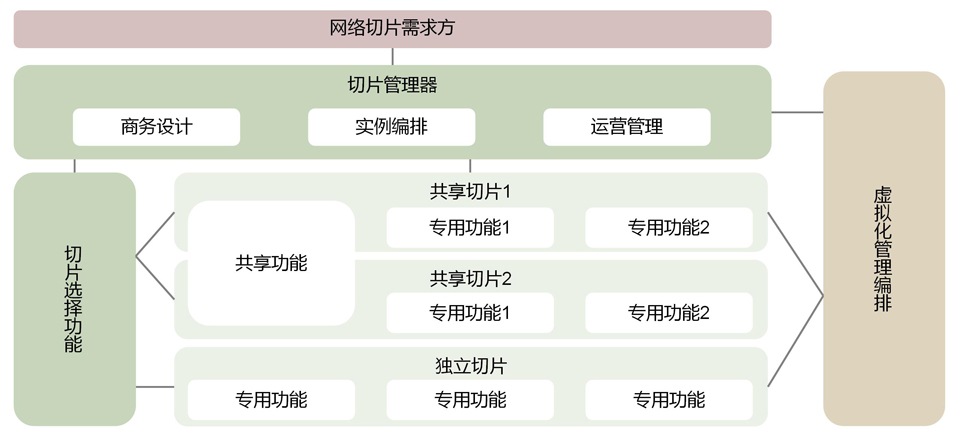
# 摘要
随着5G技术的发展,网络切片技术作为支持多样服务和应用的关键创新点,已成为行业关注的焦点。本文首先概述了5G网络切片技术,接着探讨了其在3GPP标准下的架构,包括定义、关键组成元素、设计原则、性能指标以及虚拟化实现等。文章进一步分析了网络切片在不同应用场景中的部署流程和实践案例,以及面临的挑战和解决方案。在此基础上,展望了网络切
深度揭秘RLE编码:BMP图像解码的前世今生,技术细节全解析
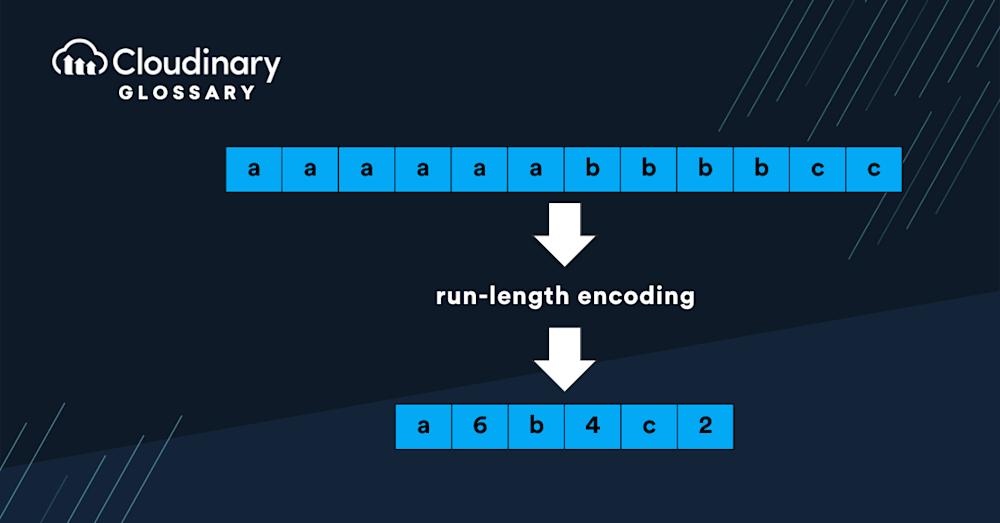
# 摘要
本文系统性地探讨了行程长度编码(RLE)编码技术及其在位图(BMP)图像格式中的应用。通过深入分析RLE的基本概念、算法细节以及在BMP中的具体实现,本文揭示了RLE编码的优缺点,并对其性能进行了综合评估。文章进一步探讨了RLE与其他现代编码技术的比较,
【SEM-BCS操作全攻略】:从新手到高手的应用与操作指南
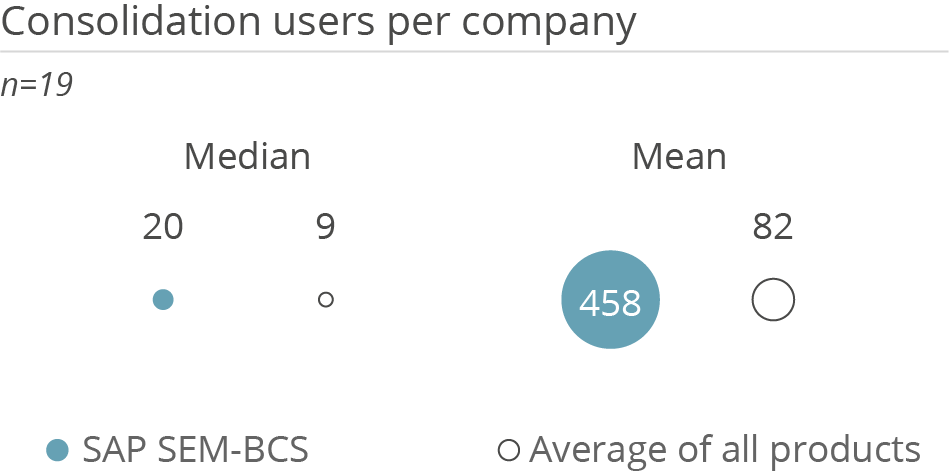
# 摘要
本文详细介绍了SEM-BCS(Scanning Electron Microscope - Beam Current Stabilizer)系统,该系统在纳米科技与材料科学领域有着广泛应用。首先概述了SEM-BCS的基础知识及其核心操作原理,包括其工作机制、操作流程及配置与优化方法。接着,通过多个实践操作案例,展示了SEM-BCS在数据分析、市场研究以及竞争对手分析中的具
【算法比较框架】:构建有效的K-means与ISODATA比较模型
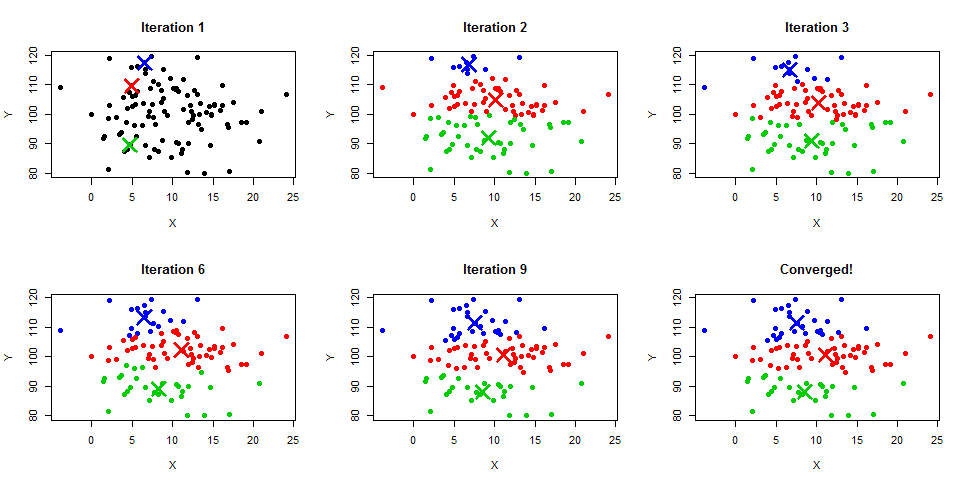
# 摘要
随着数据聚类需求的增长,有效比较不同算法的性能成为数据分析的重要环节。本文首先介绍了算法比较框架的理论基础,然后详细探讨了K-means和ISODATA这两种聚类算法的理论与实践。通过对两种算法的实现细节和优化策略进行深入分析,本文揭示了它们在实际应用中的表现,并基于构建比较模型的步骤与方法,对这两种算法进行了性能评估。案例
Linux脚本自动化管理手册:为RoseMirrorHA量身打造自动化脚本

# 摘要
本文系统地介绍了Linux脚本自动化管理的概念、基础语法、实践应用以及与RoseMirrorHA的集成。文章首先概述了Linux脚本自动化管理的重要性和基础语法结构,然后深入探讨了脚本在文件操作、网络管理、用户管理等方面的自动化实践。接着,文章重点讲解了Linux脚本在RoseMirrorH
【软件测试的哲学基础】
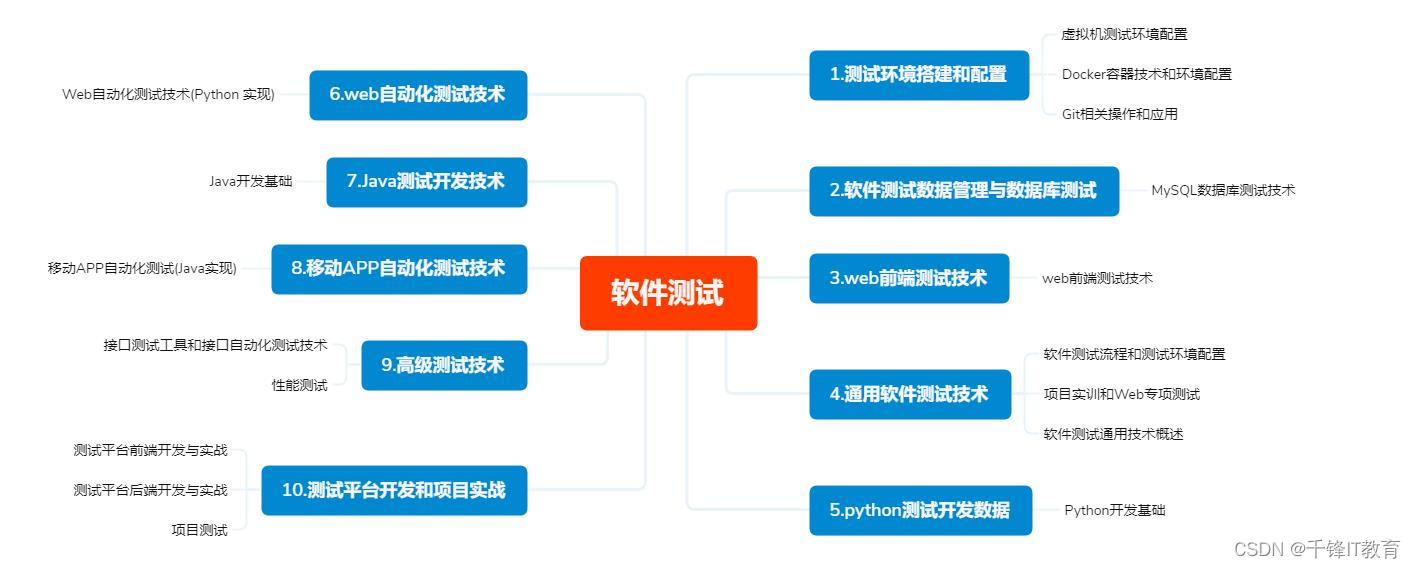
# 摘要
本文全面概述了软件测试的理论基础、类型与方法以及实践技巧,并通过案例研究来探讨传统与现代软件项目测试的实施细节。文章从软件测试的基本原则出发,分析了测试与调试的区别、软件测试模型的演变以及测试过程中的风险管理。接着,详细介绍了黑盒测试、白盒测试、静态测试、动态测试、自动化测试和性能测试的不同策略和工具。在实践技巧部分,文章探讨了测试用例设计、缺陷管理和测试工具运用的策略。最后,展望了软件测试的未来趋势,包括测试技术的发展
【数据交互优化】:S7-300 PLC与PC通信高级技巧揭秘

# 摘要
本文全面探讨了S7-300 PLC与PC通信的技术细节、实现方法、性能优化以及故障排除。首先概述了S7-300 PLC与PC通信的基础,包括不同通信协议的解析以及数据交换的基本原理。接着详细介绍了PC端通信接口的实现,包括软件开发环境的选择、编程实现数据交互以及高级通信接口的优化策略。随后,文章着重分析了通信性能瓶颈,探讨了故障诊断与排除技巧,并通过案例分析高级
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )