【Safety Angle】: Defensive Strategies for GAN Content Generation: How to Detect and Protect Data Security
发布时间: 2024-09-15 16:46:51 阅读量: 26 订阅数: 31 
# 1. Overview of GAN Content Generation Technology
GAN (Generative Adversarial Network) is a type of deep learning model consisting of two parts: a generator and a discriminator. The generator is responsible for creating data, while the discriminator's task is to distinguish between real data and the "fake" data produced by the generator. As technology advances, GANs have been widely applied in various fields such as image generation, artistic creation, data augmentation, and voice ***
***pared to traditional data generation methods, GANs can provide more complex and diverse samples, which is particularly valuable for machine learning tasks that require large amounts of training data.
However, GANs also bring a series of technical challenges. For instance, training a GAN requires a carefully designed network structure and algorithm, as well as a substantial amount of computational resources. In addition, the ethical and legal issues of generated content are gradually drawing social attention. Therefore, understanding and mastering the development and application of GAN technology is particularly important for those in the IT industry.
# 2. Potential Risks of GAN Content Generation
### 2.1 Basic Principles and Applications of GAN
#### 2.1.1 Working Mechanism of GAN
The Generative Adversarial Network (GAN) consists of two parts: a generator (Generator) and a discriminator (Discriminator). The generator's task is to create data, while the discriminator's task is to distinguish between the generated data and the real training data. These two networks compete against each other during the training process, with the generator continuously improving the quality of its generated data, and the discriminator enhancing its ability to identify true or false data. This dynamic competition ultimately leads to the generator producing realistic data.
Here is an example code block illustrating the training process of the generator and discriminator:
```python
# Define the generator model
def build_generator(z_dim):
model = Sequential([
Dense(256, input_dim=z_dim),
LeakyReLU(alpha=0.01),
BatchNormalization(momentum=0.8),
Dense(512),
LeakyReLU(alpha=0.01),
BatchNormalization(momentum=0.8),
Dense(1024),
LeakyReLU(alpha=0.01),
BatchNormalization(momentum=0.8),
Dense(784, activation='tanh'),
Reshape((28, 28, 1))
])
return model
# Define the discriminator model
def build_discriminator(img_shape):
model = Sequential([
Flatten(input_shape=img_shape),
Dense(512),
LeakyReLU(alpha=0.01),
Dense(256),
LeakyReLU(alpha=0.01),
Dense(1, activation='sigmoid')
])
return model
# Pseudo-code for the GAN model training process
def train_gan(generator, discriminator, combined, epochs, batch_size, sample_interval):
# ...省略训练过程的伪代码...
```
In this code, we first define a generator model that uses fully connected layers and LeakyReLU activation functions, ultimately reshaping the generated noise data into image form. Next, we define a discriminator model that also uses fully connected layers and LeakyReLU activation functions, finally outputting a probability value indicating the authenticity of the input image.
The training process for GAN involves the alternating training of these two networks, with the omitted code sections containing loops that are executed in each epoch until the model converges.
#### 2.1.2 Application Cases of GAN in Content Generation
GAN has been successfully applied in various fields, including image synthesis, image super-resolution, and style transfer. For example, GAN can be used to create realistic synthetic images for data augmentation or to produce art. However, the double-edged sword nature of these technologies also brings risks. Realistic content generated by GAN may be used to spread fake news or create false personal identities.
### 2.2 Potential Security Threats from GAN Content Generation
#### 2.2.1 Spreading of Fake News and Misinformation
GAN is capable of creating realistic news reports or social media content that can be highly deceptive, making it difficult for the public to discern the truth. For instance, GAN can be used by lawbreakers to generate fake news images or videos that can quickly spread on social platforms, causing panic or misleading public opinion.
#### 2.2.2 Deepfake Technology and Identity Theft
Deepfakes is a technique that uses GAN for face replacement, allowing attackers to superimpose a person's facial image onto another person's body or facial movements. This technology is used to create fake videos and audio, leading to risks of identity theft and slander.
#### 2.2.3 Data Privacy Leakage and Abuse
Without appropriate privacy protection measures, GAN can lead to data privacy leaks and abuse when processing personal data. For example, the synthetic facial data sets generated by GAN may include biometric features of real individuals, which can be used to bypass biometric security systems.
In summary, Chapter 2 delves into the potential risks of GAN technology, involving the spread of fake news, identity theft, and privacy leaks. In the next chapter, we will discuss how to detect fake content generated by GANs, including model and statistical detection techniques, as well as specific detection tools and case studies.
# 3. Methods for Detecting GAN Content
With the rapid development of Generative Adversarial Network (GAN) technology, the quality and realism of generated content have significantly improved, also bringing difficulties in detecting such content. This chapter will explore the latest methods for detecting GAN content, including model and statistical detection techniques, and analyze various detection tools in practice.
## 3.1 Model-based Detection Techniques
### 3.1.1 Detecting Features of GAN-generated Images
Although Generative Adversarial Networks can create high-quality images, there are still some detectable features in these images. These features mainly originate from the patterned manifestations during the GAN training process. Model-based detection techniques often rely on analyzing image data sets to find these unique patterns and anomalies.
**Code Block Example:**
```python
import numpy as np
from sklearn.decomposition import PCA
# Assume img_data is a set of feature vectors extracted from images
pca = PCA(n_components=0.95) # Retain 95% of data variance
reduced_data = pca.fit_transform(img_data)
# Visualize the reduced data for analysis
import matplotlib.pyplot as plt
plt.scatter(reduced_data[:, 0], reduced_data[:, 1])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA visualization of image features')
plt.show()
```
**Parameter Explanation and Logical Analysis:**
In this code, we use PCA (Principal Component Analysis) to reduce the dimensionality of image feature data. By retaining 95% of the data variance, we can effectively reduce the dimensionality while preserving most of the information for analysis. Through the scatter plot, we can visually observe whether there are differences in the distribution of GAN-generated images and real images in the image feature space.
### 3.1.2 Detecting Features of GAN-generated Audio
Although GAN has achieved great success in image generation, it is also applied to generate audio data. Detecting audio content generated by GANs is also challenging. Audio detection relies on the unique properties of audio signals, such as spectral characteristics, temporal features, and discontinuities in audio synthesis.
**Code Block Example:**
```python
import librosa
import numpy as np
# Load audio file
audio, sample_rate = librosa.load('audio_file.wav')
# Extract the Mel-spectrogram of the audio signal
S = librosa.feature.melspectrogram(audio, sr=sample_rate)
log_S = librosa.power_to_db(S, ref=np.max)
# Use the Mel-spectrogram as a detection feature
plt.imshow(log_S,
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【KEBA机器人高级攻略】:揭秘行业专家的进阶技巧

# 摘要
本论文对KEBA机器人进行全面的概述与分析,从基础知识到操作系统深入探讨,特别关注其启动、配置、任务管理和网络连接的细节。深入讨论了KEBA机器人的编程进阶技能,包括高级语言特性、路径规划及控制算法,以及机器人视觉与传感器的集成。通过实际案例分析,本文详细阐述了KEBA机器人在自动化生产线、高精度组装以及与人类协作方面的应用和优化。最后,探讨了KEBA机器人集成
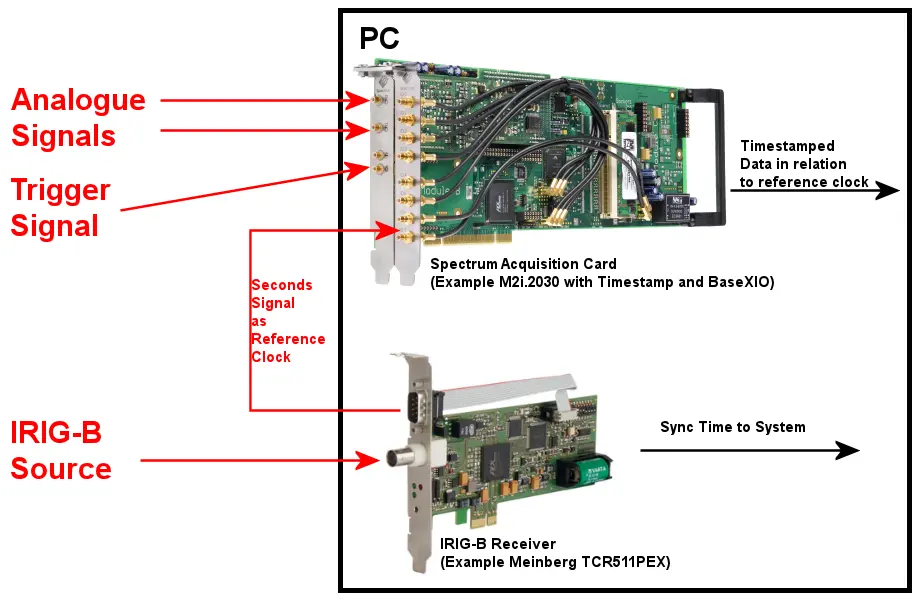
【基于IRIG 106-19的遥测数据采集】:最佳实践揭秘
# 摘要
本文系统地介绍了IRIG 106-19标准及其在遥测数据采集领域的应用。首先概述了IRIG 106-19标准的核心内容,并探讨了遥测系统的组成与功能。其次,深入分析了该标准下数据格式与编码,以及采样频率与数据精度的关系。随后,文章详细阐述了遥测数据采集系统的设计与实现,包括硬件选型、软件框架以及系统优化策略,特别是实时性与可靠
【提升设计的艺术】:如何运用状态图和活动图优化软件界面
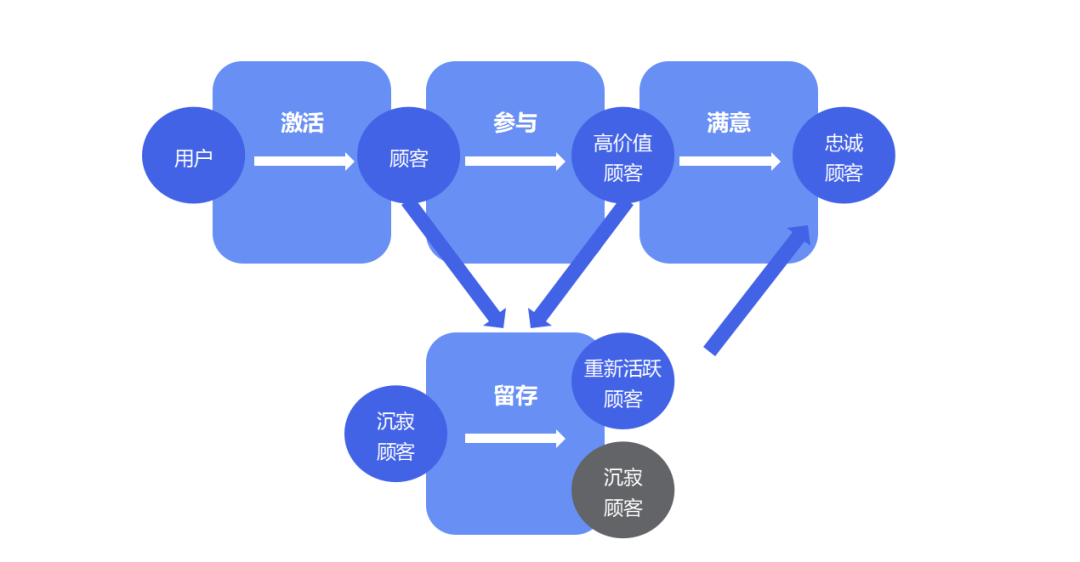
# 摘要
本文系统地探讨了状态图和活动图在软件界面设计中的应用及其理论基础。首先介绍了状态图与活动图的基本概念和组成元素,随后深入分析了在用户界面设计中绘制有效状态图和活动图的实践技巧。文中还探讨了设计原则,并通过案例分析展示了如何将这些图表有效地应用于界面设计。文章进一步讨论了状态图与活动图的互补性和结合使用,以及如何将理论知识转化为实践中的设计过程。最后,展望了面向未来的软
台达触摸屏宏编程故障不再难:5大常见问题及解决策略

# 摘要
台达触摸屏宏编程是一种为特定自动化应用定制界面和控制逻辑的有效技术。本文从基础概念开始介绍,详细阐述了台达触摸屏宏编程语言的特点、环境设置、基本命令及结构。通过分析常见故障类型和诊断方法,本文深入探讨了故障产生的根源,包括语法和逻辑错误、资源限制等。针对这
构建高效RM69330工作流:集成、测试与安全性的终极指南

# 摘要
本论文详细介绍了RM69330工作流的集成策略、测试方法论以及安全性强化,并展望了其高级应用和未来发展趋势。首先概述了RM69330工作流的基础理论与实践,并探讨了与现有系统的兼容性。接着,深入分析了数据集成的挑战、自动化工作流设计原则以及测试的规划与实施。文章重点阐述了工作流安全性设计原则、安全威胁的预防与应对措施,以及持续监控与审计的重要性。通过案例研究,展示了RM
Easylast3D_3.0速成课:5分钟掌握建模秘籍

# 摘要
Easylast3D_3.0是业界领先的三维建模软件,本文提供了该软件的全面概览和高级建模技巧。首先介绍了软件界面布局、基本操作和建模工具,然后深入探讨了材质应用、曲面建模以及动画制作等高级功能。通过实际案例演练,展示了Easylast3D_3.0在产品建模、角色创建和场景构建方面的应用。此外,本文还讨
【信号完整性分析速成课】:Cadence SigXplorer新手到专家必备指南
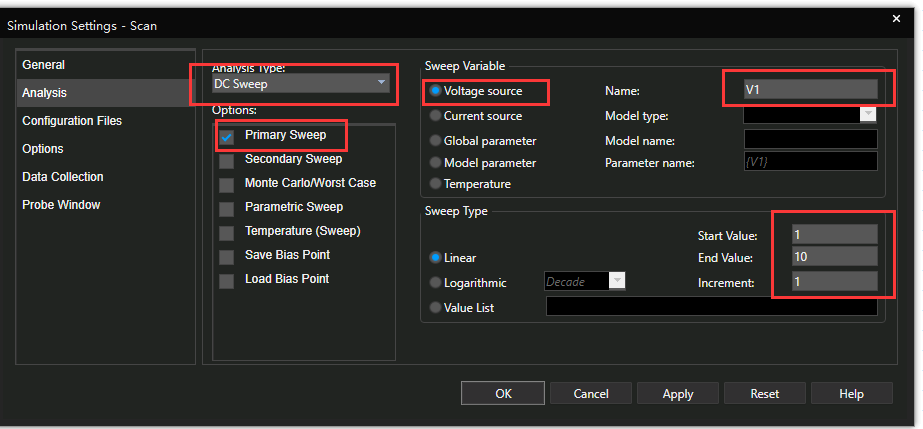
# 摘要
本论文旨在系统性地介绍信号完整性(SI)的基础知识,并提供使用Cadence SigXplorer工具进行信号完整性分析的详细指南。首先,本文对信号完整性的基本概念和理论进行了概述,为读者提供必要的背景知识。随后,重点介绍了Cadence SigXplorer界面布局、操作流程和自定义设置,以及如何优化工作环境以提高工作效率。在实践层面,论文详细解释了信号完整性分析的关键概念,包括信号衰
高速信号处理秘诀:FET1.1与QFP48 MTT接口设计深度剖析
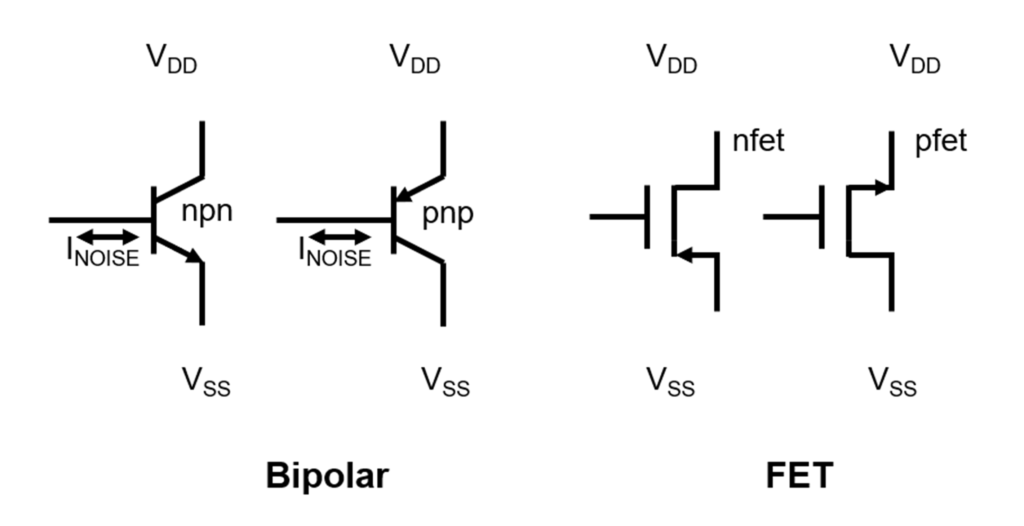
# 摘要
高速信号处理与接口设计在现代电子系统中起着至关重要的作用,特别是在数据采集、工业自动化等领域。本文首先概述了高速信号处理与接口设计的基本概念,随后深入探讨了FET1.1接口和QFP48 MTT接口的技术细节,包括它们的原理、硬件设计要点、软件驱动实现等。接着,分析了两种接口的协同设计,包括理论基础、
【MATLAB M_map符号系统】:数据点创造性表达的5种方法

# 摘要
本文详细介绍了M_map符号系统的基本概念、安装步骤、符号和映射机制、自定义与优化方法、数据点创造性表达技巧以及实践案例分析。通过系统地阐述M_map的坐标系统、个性化符号库的创建、符号视觉效果和性能的优化,本文旨在提供一种有效的方法来增强地图数据的可视化表现力。同时,文章还探讨了M_map在科学数据可视化、商业分析及教育领域的应用,并对其进阶技巧和未来的发展趋势提出了预测和建议。
物流监控智能化:Proton-WMS设备与传感器集成解决方案
# 摘要
物流监控智能化是现代化物流管理的关键组成部分,有助于提高运营效率、减少错误以及提升供应链的透明度。本文概述了Proton-WMS系统的架构与功能,包括核心模块划分和关键组件的作用与互动,以及其在数据采集、自动化流程控制和实时监控告警系统方面的实际应用。此外,文章探讨了设备与传感器集成技术的原理、兼容性考量以及解决过程中的问题。通过分析实施案例,本文揭示了Proton-WMS集成的关键成功要素,并讨论了未来技术发展趋势和系统升级规划,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )