[Frontier Developments]: GAN's Latest Breakthroughs in Deepfake Domain: Understanding Future AI Trends
发布时间: 2024-09-15 17:06:01 阅读量: 44 订阅数: 31 
# 1. Introduction to Deepfakes and GANs
## 1.1 Definition and History of Deepfakes
Deepfakes, a portmanteau of "deep learning" and "fake", are technologically-altered images, audio, and videos that are lifelike thanks to the power of deep learning, particularly Generative Adversarial Networks (GANs). They have the potential to mislead viewers by manufacturing false information visually and aurally. The deepfake technology emerged in 2017, initially for creating pornographic videos, but it quickly evolved to spread across various fields including politics and entertainment.
## 1.2 Origin and Applications of GANs
Generative Adversarial Networks (GANs) were introduced by Ian Goodfellow in 2014, and they consist of two main parts: a generator and a discriminator. The generator creates fake data, while the discriminator tries to distinguish between the real and the fake. GANs have broad applications in image generation, image restoration, super-resolution, and beyond.
## 1.3 The Connection between GANs and Deepfakes
GANs are at the core of deepfake technology. With GANs, we can generate realistic fake images, audio, and videos, which is the primary method for creating deepfakes. However, this also brings challenges of legality and ethics, and how to effectively detect and prevent deepfakes has become an urgent issue to address.
# 2. The Fundamental Principles and Mathematical Foundations of GANs
## 2.1 The Theoretical Framework of GANs
### 2.1.1 Origin and Development of Generative Adversarial Networks
Generative Adversarial Networks (GAN), proposed by Ian Goodfellow and colleagues in 2014, marked a leap forward in the field of generative models, drawing inspiration from the zero-sum game in game theory. GAN utilizes two models—the Generator and the Discriminator—in an adversarial process to improve performance.
As research continued, variations such as DCGAN (Deep Convolutional Generative Adversarial Networks), WGAN (Wasserstein Generative Adversarial Networks), BigGAN, and StyleGAN were proposed, expanding the boundaries of GAN technology.
### 2.1.2 The Mathematical Model and Optimization Objective of GANs
The essence of GAN lies in the adversarial process, where the parameters of the generator and discriminator are continuously updated to achieve a state of Nash Equilibrium. Mathematically, the optimization goal of GAN can be represented as:
```
min_G max_D V(D, G) = E_x[log D(x)] + E_z[log(1 - D(G(z)))]
```
Where `D` is the discriminator, `G` is the generator, `x` represents real data samples, and `z` is random noise drawn from a prior distribution. The generator `G` aims to produce samples as close to the real data as possible, while the discriminator `D` tries to distinguish between generated samples and real samples.
## 2.2 Key Components of GANs
### 2.2.1 The Role and Structure of the Generator
The generator's task is to receive a random noise vector `z`, learn the distribution of real data, and generate samples that are as similar as possible to real data. The generator is typically realized by a multi-layer neural network, which can have dozens or even hundreds of layers.
The typical structure of a generator network includes multiple fully connected or convolutional layers, which may be followed by batch normalization layers and ReLU activation functions. Convolutional neural network structures are more common in image generation scenarios, as they effectively capture local features.
### 2.2.2 The Mechanism and Training of the Discriminator
The main task of the discriminator is to distinguish whether the input sample is real or generated by the generator. It is also a neural network, usually similar in structure to the generator. The discriminator improves performance by maximizing the probability of distinguishing real data from generated data.
During training, the discriminator tries to distinguish between real data and fake data generated by the generator. To enhance the performance of the discriminator, it needs to process both real and generated samples and provide a judgment. As training progresses, the generator learns to produce more realistic data to deceive the discriminator.
## 2.3 Challenges in the GAN Training Process
### 2.3.1 Mode Collapse Problem
Mode collapse is a common issue in GAN training. It refers to the generator beginning to produce samples from only a few distributions, ignoring other parts of the data space, resulting in reduced diversity.
There are various methods to address mode collapse, such as adding regularization terms, using historical data to combat the generator, or adopting more complex network structures. More advanced techniques like WGAN use the Wasserstein distance instead of the traditional objective function, which can effectively alleviate the mode collapse problem.
### 2.3.2 Loss Functions and Training Strategies
The design of the GAN loss function and training strategy is a key factor affecting its training effectiveness. Traditional GANs use cross-entropy loss functions, but there are some drawbacks, such as the difficulty in balancing the competition intensity between the generator and discriminator.
To optimize the training process, researchers have tried various methods, such as introducing label smoothing techniques, using gradient penalties to stabilize training, or applying gradient clipping with different strategies. In addition, some studies focus on improvements in model architecture, such as the self-attention mechanism introduced in BigGAN, all aimed at improving the training stability and generation quality of the model.
# 3. Practical Applications of GANs in Deepfakes
### 3.1 Basic Techniques of Deepfakes
#### 3.1.1 Overview of Deepfake Techniques for Images and Videos
Deepfake technology has gradually evolved into a comprehensive technology, including deep learning applications in images, videos, and voices. For images and videos, deepfake technology mainly relies on Generative Adversarial Networks (GANs) to achieve highly realistic fake content. This content can be anything from replacing a person's face, changing body movements, to applying one person's voice to another.
The emergence of deepfake technology is due to the demand for high-quality generated content. On the one hand, this brings good news to the film and entertainment industry, making the production of cooler special effects possible; on the other hand, it also brings many risks to society, such as using personal images and voices for inappropriate occasions, leading to privacy infringement and the spread of fake information.
#### 3.1.2 Deepfake Techniques for Voice Synthesis
Voice synthesis technology, also known as Text-to-Speech (TTS), has made significant progress. The voice synthesis technology in deepfakes can utilize GANs to generate realistic voices based on sound generation models such as WaveNet and Tacotron.
These technologies first collect a large amount of voice data and then use deep learning models to learn the characteristics of sound. The role of GAN here is to ensure, through the adversarial mechanism, that the generated sound is indistinguishable from the naturalness of real sounds. This technology has important application value in podcast production, voice assistants, and personalized education. However, similarly, it also brings the risk of being abused, such as deepfake-generated voices being used for fraud, defamation, and even impersonating public figures to make inappropriate statements.
### 3.2 Practical Applications of GANs in Image Deepfakes
#### 3.2.1 Facial Replacement and Expression Transfer Technologies
Facial replacement technology is mainly realized through GANs, among which one of the most famous models is DeepFake. This technology can seamlessly replace a person's face with another person's face while maintaining the naturalness of expressions and movements. The core of this technology lies in the generator's ability to produc

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【技术教程五要素】:高效学习路径构建的5大策略
# 摘要
技术学习的本质与价值在于其能够提升个人和组织的能力,以应对快速变化的技术环境。本文探讨了学习理论的构建与应用,包括认知心理学和教育心理学在技术学习中的运用,以及学习模式从传统教学到在线学习的演变。此外,本文还关注实践技能的培养与提升,强调技术项目管理的重要性以及技术工具与资源的利用。在高效学习方法的探索与实践中,本文提出多样化的学习方法、时间管理与持续学习策略。最后,文章展望了未来技术学习面临的挑战与趋势,包括技术快速发展的挑战和人工智能在技术教育中的应用前景。
【KEBA机器人维护秘籍】:专家教你如何延长设备使用寿命

# 摘要
本文系统地探讨了KEBA机器人的维护与优化策略,涵盖了从基础维护知识到系统配置最佳实践的全面内容。通过分析硬件诊断、软件维护、系统优化、操作人员培训以及实际案例研究,本文强调了对KEBA机器人进行系统维护的重要性,并为操作人员提供了一系列技能提升和故障排除的方法。文章还展望了未来维护技术的发展趋势,特别是预测性维护和智能化技术在提升机器人性能和可靠性方面的应用前景。
# 关键字
KEBA机器人;硬件诊断;
【信号完整性优化】:Cadence SigXplorer高级使用案例分析
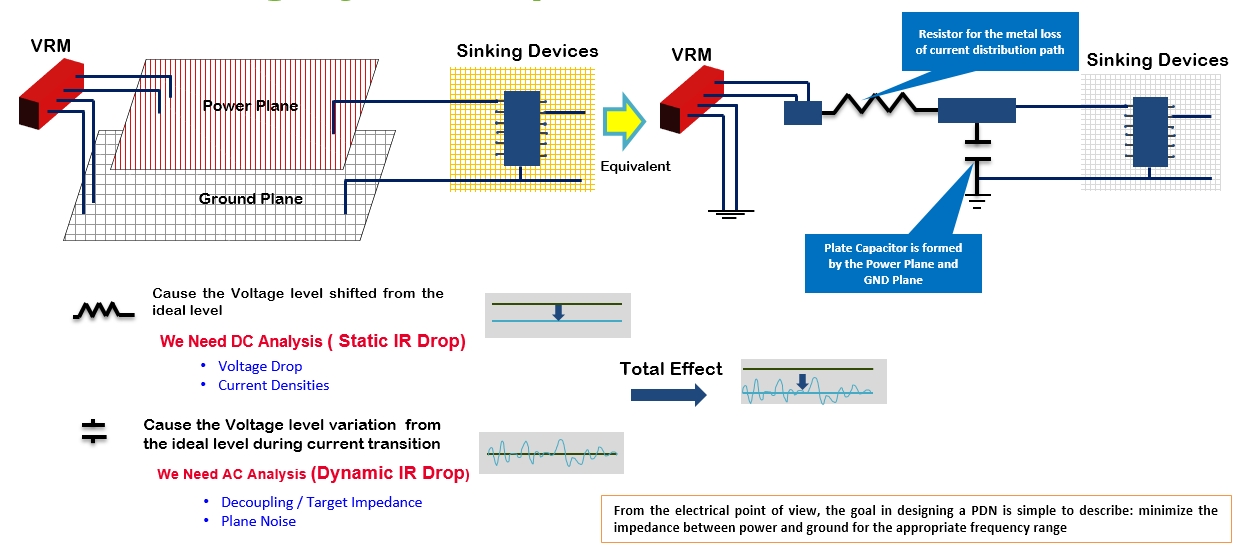
# 摘要
信号完整性是高速电子系统设计中的关键因素,影响着电路的性能与可靠性。本文首先介绍了信号完整性的基础概念,为理解后续内容奠定了基础。接着详细阐述了Cadence SigXplorer工具的界面和功能,以及如何使用它来分析和解决信号完整性问题。文中深入讨论了信号完整性问题的常见类型,如反射、串扰和时序问题,并提供了通过仿真模拟与实
【IRIG 106-19安全规定:数据传输的守护神】:保障您的数据安全无忧
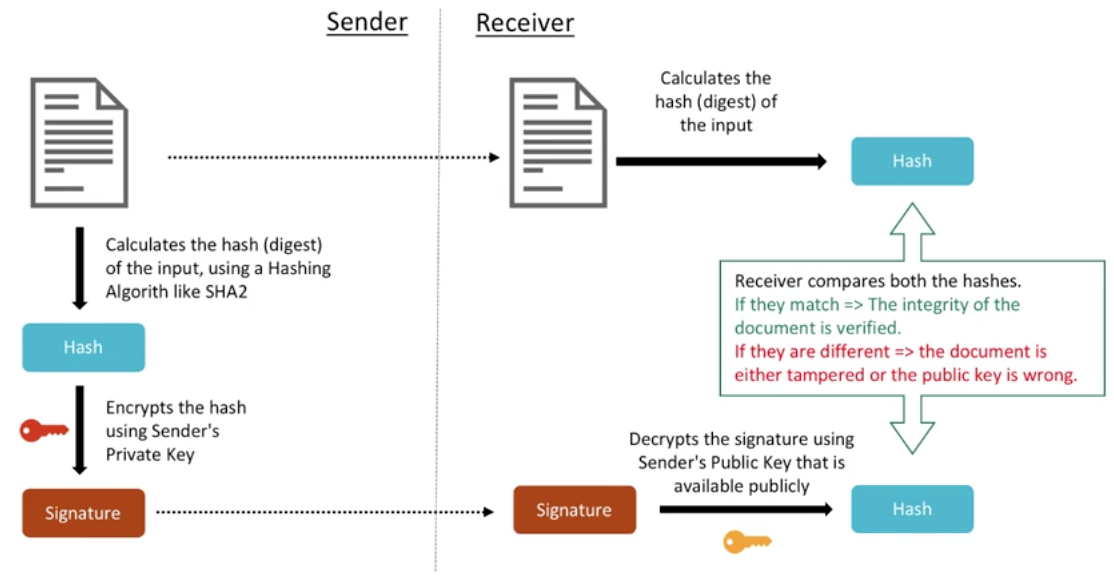
# 摘要
本文全面概述了IRIG 106-19安全规定,并对其技术基础和实践应用进行了深入分析。通过对数据传输原理、安全威胁与防护措施的探讨,本文揭示了IRIG 106-19所确立的技术框架和参数,并详细阐述了关键技术的实现和应用。在此基础上,本文进一步探讨了数据传输的安全防护措施,包括加密技术、访问控制和权限管理,并通过实践案例
【Python数据处理实战】:轻松搞定Python数据处理,成为数据分析师!

# 摘要
随着数据科学的蓬勃发展,Python语言因其强大的数据处理能力而备受推崇。本文旨在全面概述Python在数据处理中的应用,从基础语法和数据结构讲起,到必备工具的深入讲解,再到实践技巧的详细介绍。通过结合NumPy、Pandas和Matplotlib等库,本文详细介绍了如何高效导入、清洗、分析以及可视化数据,确保读者能掌握数据处理的核心概念和技能。最后,通过一个项目实战章
Easylast3D_3.0高级建模技巧大公开:专家级建模不为人知的秘密
# 摘要
Easylast3D_3.0是一款先进的三维建模软件,广泛应用于工程、游戏设计和教育领域。本文系统介绍了Easylast3D_3.0的基础概念、界面布局、基本操作技巧以及高级建模功能。详细阐述了如何通过自定义工作空间、视图布局、基本建模工具、材质与贴图应用、非破坏性建模技术、高级表面处理、渲染技术等来提升建模效率和质量。同时,文章还探讨了脚本与自动化在建模流
PHP脚本执行系统命令的艺术:安全与最佳实践全解析

# 摘要
PHP脚本执行系统命令的能力增加了其灵活性和功能性,但同时也引入了安全风险。本文介绍了PHP脚本执行系统命令的基本概念,分析了PHP中执行系统命令
PCB设计技术新视角:FET1.1在QFP48 MTT上的布局挑战解析
# 摘要
本文详细探讨了FET1.1技术在PCB设计中的应用,特别强调了QFP48 MTT封装布局的重要性。通过对QFP48 MTT的物理特性和电气参数进行深入分析,文章进一步阐述了信号完整性和热管理在布局设计中的关键作用。文中还介绍了FET1.1在QFP48 MTT上的布局实践,从准备、执行到验证和调试的全过程。最后,通过案例研究,本文展示了FET1.1布局技术在实际应用中可能遇到的问题及解决策略,并展望了未来布
【Sentaurus仿真速成课】:5个步骤带你成为半导体分析专家

# 摘要
本文全面介绍了Sentaurus仿真软件的基础知识、理论基础、实际应用和进阶技巧。首先,讲述了Sentaurus仿真的基本概念和理论,包括半导体物理基础、数值模拟原理及材料参数的处理。然后,本文详细阐述了Sentaurus仿真
台达触摸屏宏编程初学者必备:基础指令与实用案例分析

# 摘要
本文旨在全面介绍台达触摸屏宏编程的基础知识和实践技巧。首先,概述了宏编程的核心概念与理论基础,详细解释了宏编程指令体系及数据处理方法,并探讨了条件判断与循环控制。其次,通过实用案例实践,展现了如何在台达触摸屏上实现基础交互功能、设备通讯与数据交换以及系统与环境的集成。第三部分讲述了宏编程的进阶技巧,包括高级编程技术、性能优化与调试以及特定领域的应用。最后,分析了宏编程的未来趋势,包括智能化、自动化的新趋势,开源社区与生态的贡献,以及宏编程教育与培训的现状和未来发展。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )