【Interdisciplinary Applications】: The Ethical Boundaries of GAN in Artistic Creation: Exploring the Integration of AI and Human Creativity
发布时间: 2024-09-15 16:51:54 阅读量: 29 订阅数: 33 

Analysis of the reliability and precision of spike timing by a single model neuron
# Introduction to Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are a type of deep learning model composed of two parts: the generator and the discriminator. The generator is responsible for creating fake data that closely resembles real data, while the discriminator learns to distinguish between real data and the fake data produced by the generator. This adversarial training method is what gives GANs their name, and the core idea is to iteratively improve the quality of the data generated by the generator until it becomes difficult for the discriminator to differentiate between real and fake.
The strength of GANs lies in their powerful generative capabilities; they can learn the distribution of data in an unsupervised manner, automatically discovering key features in the data and creating new instances. This has shown tremendous potential in various fields, including image, video, music, and text generation.
However, the training process for GANs is complex and unstable, prone to issues such as mode collapse, which requires us to adopt appropriate techniques and optimization methods to overcome. For example, incorporating Wasserstein distance can improve training stability, while techniques like label smoothing and gradient penalty can prevent overfitting by the generator.
```
# Pseudocode example: A simple GAN structure
def generator(z):
# Map random noise z to the data space
return mapping_to_data_space(z)
def discriminator(X):
# Determine whether the input data is real or generated by the generator
return mapping_to_prob_space(X)
# Training process
for epoch in range(num_epochs):
for batch in data_loader:
# Train the discriminator
real_data, generated_data = get_real_and_generated_data(batch)
d_loss_real = loss_function(discriminator(real_data), 1)
d_loss_generated = loss_function(discriminator(generated_data), 0)
d_loss = d_loss_real + d_loss_generated
discriminator_optimizer.zero_grad()
d_loss.backward()
discriminator_optimizer.step()
# Train the generator
z = get_random_noise(batch_size)
generated_data = generator(z)
g_loss = loss_function(discriminator(generated_data), 1)
generator_optimizer.zero_grad()
g_loss.backward()
generator_optimizer.step()
```
With this foundational introduction, we can see how GANs stand out in the field of machine learning and open up new possibilities for AI in artistic creation. As research deepens and technology advances, the application scope of GANs is set to expand even further.
# GANs in Artistic Creation: Theoretical Aspects
## 2.1 Basic Principles and Architecture of GANs
### 2.1.1 Components of an Adversarial Network
Generative Adversarial Networks (GANs) consist of two parts: the generator and the discriminator. The generator's role is to create data; it takes a random noise vector and transforms it into fake data that closely resembles real data. The discriminator's task is to determine whether an image is real or fake, generated by the generator.
The relationship between the generator and discriminator is akin to that of a "counterfeiter" and a "policeman." The counterfeiter tries to mimic real currency as closely as possible to deceive the policeman, while the policeman endeavors to learn how to distinguish between counterfeit and real currency. The adversarial relationship between them drives the model's progress in learning.
**Parameter Explanation and Code Analysis:**
In Python, we can build GAN models using frameworks such as TensorFlow or PyTorch. Below is a simplified example of code for the generator and discriminator, along with pseudocode for the training process.
```python
import tensorflow as tf
from tensorflow.keras.layers import Dense, Conv2D, Flatten
# Generator model (simplified example)
def build_generator(z_dim):
model = tf.keras.Sequential()
# Input layer to hidden layer
model.add(Dense(128, activation='relu', input_dim=z_dim))
# Hidden layer to output layer, output image size is 64x64
model.add(Dense(64*64*1, activation='tanh'))
model.add(Reshape((64, 64, 1)))
return model
# Discriminator model (simplified example)
def build_discriminator(image_shape):
model = tf.keras.Sequential()
# Input layer, image size is 64x64
model.add(Flatten(input_shape=image_shape))
# Input layer to hidden layer
model.add(Dense(128, activation='relu'))
# Hidden layer to output layer, output decision result
model.add(Dense(1, activation='sigmoid'))
return model
```
In practical applications, more complex network structures and regularization techniques are needed to prevent model overfitting. For example, convolutional layers (Conv2D) can be used instead of fully connected layers (Dense) to adapt to the characteristics of image data.
### 2.1.2 GAN Training Process and Optimization Techniques
The GAN training process is a dynamic balancing act. If the discriminator improves too quickly, the generator will struggle to learn how to produce sufficiently realistic data; conversely, if the generator progresses too fast, the discriminator may become unable to distinguish between real and fake data. Therefore, when training GANs, it is necessary to finely tune learning rates and other hyperparameters.
**Optimization Techniques:**
1. **Learning Rate Decay:** Gradually decrease the learning rate as training progresses to allow the model to search more finely in the parameter space.
2. **Gradient Penalty (WGAN-GP):** Use gradient penalties to ensure that the data distribution generated by the model does not stray too far from the real data distribution.
3. **Batch Normalization:** Stabilize the training process and reduce the problem of vanishing gradients.
4. **Feature Matching:** Guide the generator's learning by comparing the feature statistics of real data with generated data.
**Code Example:**
```python
# GAN training pseudocode
# Define the loss function
def gan_loss(y_true, y_pred):
return tf.keras.losses.BinaryCrossentropy(from_logits=True)(y_true, y_pred)
# Define optimizers
g_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
d_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
# Training loop
for epoch in range(epochs):
for batch in data_loader:
# Train the discriminator
real_data = batch
fake_data = generator(tf.random.normal([batch_size, z_dim]))
with tf.GradientTape() as tape:
predictions_real = discriminator(real_data, training=True)
predictions_fake = discriminator(fake_data, training=True)
loss_real = gan_loss(tf.ones_like(predictions_real), predictions_real)
loss_fake = gan_loss(tf.zeros_like(predictions_fake), predictions_fake)
loss = (loss_real + loss_fake) / 2
gradients_of_discriminator = tape.gradient(loss, discriminator.trainable_variables)
d_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
# Train the generator
with tf.GradientTape() as tape:
generated_data = generator(tf.random.normal([batch_size, z_dim]), training=True)
predictions = discriminator(generated_data, training=False)
gen_loss = gan_loss(tf.ones_like(predictions), predictions)
gradients_of_generator = tape.gradient(gen_loss, generator.trainable_variables)
g_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
```
In practical applications, this code needs to be combined with specific library functions and models. Learning rate decay can typically be achieved using the optimizer's built-in decayers, while gradient penalties need to be added as additional terms in the loss function. Batch normalization is usually applied directly to each layer of the model, and feature matching requires collecting the statistical measures of real data during training, then training the generator to match these statistics with those of the generated data.
## 2.2 Artistic Expressions of GANs
### 2.2.1 Definition of Creativity and the Role of Human Artists
Creativity is at the heart of artistic creation; it refers to the ability to generate new ideas or things. In the field of artificial intelligence, creativity is often understood as the ability to recombine existing information in new or unique contexts.
In the application of GANs in art, the role of human artists is that of a guide and collaborator. They direct the model by setting initial parameters, designing network architectures, and training frameworks. At the same time, human artists can also post-process the generated results, adding personal creative elements.
### 2.2.2 Characteristics and Classification of GAN-Generated Art
GAN-generated artworks typically have the following characteristics:
- **Diversity:** GANs are capable of producing artworks in various styles and forms.
- **Rich in Detail:** With the appropriate dataset and model structure, GANs can create artworks with detailed content.
- **Novelty:** GANs are capable of creating unprecedented forms and styles of art.
The cla

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
潮流分析的艺术:PSD-BPA软件高级功能深度介绍

# 摘要
电力系统分析在保证电网安全稳定运行中起着至关重要的作用。本文首先介绍了潮流分析的基础知识以及PSD-BPA软件的概况。接着详细阐述了PSD-BPA的潮流计算功能,包括电力系统的基本模型、潮流计算的数学原理以及如何设置潮流计算参数。本文还深入探讨了PSD-BPA的高级功
RTC4版本迭代秘籍:平滑升级与维护的最佳实践

# 摘要
本文重点讨论了RTC4版本迭代的平滑升级过程,包括理论基础、实践中的迭代与维护,以及维护与技术支持。文章首先概述了RTC4的版本迭代概览,然后详细分析了平滑升级的理论基础,包括架构与组件分析、升级策略与计划制定、技术要点。在实践章节中,本文探讨了版本控制与代码审查、单元测试
嵌入式系统中的BMP应用挑战:格式适配与性能优化
# 摘要
本文综合探讨了BMP格式在嵌入式系统中的应用,以及如何优化相关图像处理与系统性能。文章首先概述了嵌入式系统与BMP格式的基本概念,并深入分析了BMP格式在嵌入式系统中的应用细节,包括结构解析、适配问题以及优化存储资源的策略。接着,本文着重介绍了BMP图像的处理方法,如压缩技术、渲染技术以及资源和性能优化措施。最后,通过具体应用案例和实践,展示了如何在嵌入式设备中有效利用BMP图像,并探讨了开发工具链的重要性。文章展望了高级图像处理技术和新兴格式的兼容性,以及未来嵌入式系统与人工智能结合的可能方向。
# 关键字
嵌入式系统;BMP格式;图像处理;性能优化;资源适配;人工智能
参考资
SSD1306在智能穿戴设备中的应用:设计与实现终极指南
# 摘要
SSD1306是一款广泛应用于智能穿戴设备的OLED显示屏,具有独特的技术参数和功能优势。本文首先介绍了SSD1306的技术概览及其在智能穿戴设备中的应用,然后深入探讨了其编程与控制技术,包括基本编程、动画与图形显示以及高级交互功能的实现。接着,本文着重分析了SSD1306在智能穿戴应用中的设计原则和能效管理策略,以及实际应用中的案例分析。最后,文章对SSD1306未来的发展方向进行了展望,包括新型显示技术的对比、市场分析以及持续开发的可能性。
# 关键字
SSD1306;OLED显示;智能穿戴;编程与控制;用户界面设计;能效管理;市场分析
参考资源链接:[SSD1306 OLE
ECOTALK数据科学应用:机器学习模型在预测分析中的真实案例

# 摘要
本文对机器学习模型的基础理论与技术进行了综合概述,并详细探讨了数据准备、预处理技巧、模型构建与优化方法,以及预测分析案例研究。文章首先回顾了机器学习的基本概念和技术要点,然后重点介绍了数据清洗、特征工程、数据集划分以及交叉验证等关键环节。接
PM813S内存管理优化技巧:提升系统性能的关键步骤,专家分享!
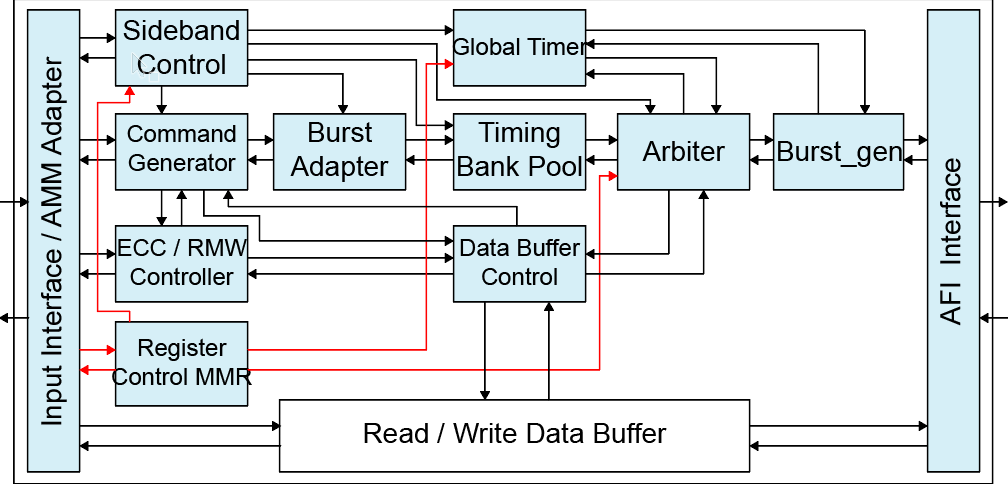
# 摘要
PM813S作为一款具有先进内存管理功能的系统,其内存管理机制对于系统性能和稳定性至关重要。本文首先概述了PM813S内存管理的基础架构,然后分析了内存分配与回收机制、内存碎片化问题以及物理与虚拟内存的概念。特别关注了多级页表机制以及内存优化实践技巧,如缓存优化和内存压缩技术的应用。通过性能评估指标和调优实践的探讨,本文还为系统监控和内存性能提
CC-LINK远程IO模块AJ65SBTB1现场应用指南:常见问题快速解决
# 摘要
CC-LINK远程IO模块作为一种工业通信技术,为自动化和控制系统提供了高效的数据交换和设备管理能力。本文首先概述了CC-LINK远程IO模块的基础知识,接着详细介绍了其安装与配置流程,包括硬件的物理连接和系统集成要求,以及软件的参数设置与优化。为应对潜在的故障问题,本文还提供了故障诊断与排除的方法,并探讨了故障解决的实践案例。在高级应用方面,文中讲述了如何进行编程与控制,以及如何实现系统扩展与集成。最后,本文强调了CC-LINK远程IO模块的维护与管理的重要性,并对未来技术发展趋势进行了展望。
# 关键字
CC-LINK远程IO模块;系统集成;故障诊断;性能优化;编程与控制;维护
【光辐射测量教育】:IT专业人员的培训课程与教育指南

# 摘要
光辐射测量是现代科技中应用广泛的领域,涉及到基础理论、测量设备、技术应用、教育课程设计等多个方面。本文首先介绍了光辐射测量的基础知识,然后详细探讨了不同类型的光辐射测量设备及其工作原理和分类选择。接着,本文分析了光辐射测量技术及其在环境监测、农业和医疗等不同领域的应用实例。教育课程设计章节则着重于如何构建理论与实践相结合的教育内容,并提出了评估与反馈机制。最后,本文展望了光辐射测量教育的未来趋势,讨论了技术发展对教育内容和教
【Ubuntu 16.04系统更新与维护】:保持系统最新状态的策略
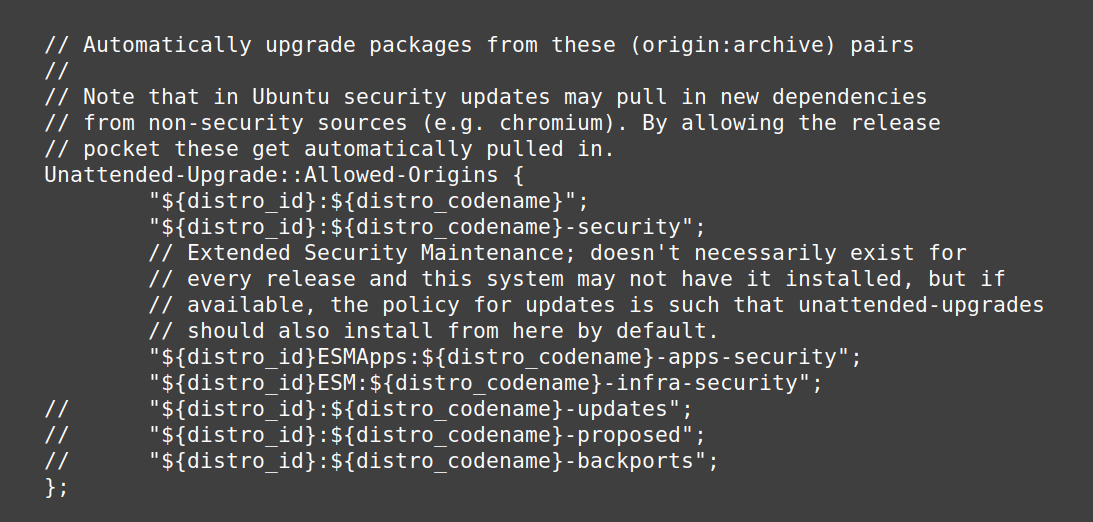
# 摘要
本文针对Ubuntu 16.04系统更新与维护进行了全面的概述,探讨了系统更新的基础理论、实践技巧以及在更新过程中可能遇到的常见问题。文章详细介绍了安全加固与维护的策略,包括安全更新与补丁管理、系统加固实践技巧及监控与日志分析。在备份与灾难恢复方面,本文阐述了
分析准确性提升之道:谢菲尔德工具箱参数优化攻略

# 摘要
本文介绍了谢菲尔德工具箱的基本概念及其在各种应用领域的重要性。文章首先阐述了参数优化的基础理论,包括定义、目标、方法论以及常见算法,并对确定性与随机性方法、单目标与多目标优化进行了讨论。接着,本文详细说明了谢菲尔德工具箱的安装与配置过程,包括环境选择、参数配置、优化流程设置以及调试与问题排查。此外,通过实战演练章节,文章分析了案例应用,并对参数调优的实验过程与结果评估给出了具体指
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )