【Theoretical Deepening】: Cracking the Convergence Dilemma of GANs: In-Depth Analysis from Theory to Practice
发布时间: 2024-09-15 16:31:54 阅读量: 36 订阅数: 31 

果壳处理器研究小组(Topic基于RISCV64果核处理器的卷积神经网络加速器研究)详细文档+全部资料+优秀项目+源码.zip
# Deep Dive into the Convergence Challenges of GANs: Theoretical Insights to Practical Applications
## 1. Introduction to Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) represent a significant breakthrough in the field of deep learning in recent years. They consist of two parts: the generator and the discriminator. The goal of the generator is to create data that is as similar as possible to real data, while the discriminator aims to accurately identify whether the data is real or generated by the generator. The two work in opposition to each other, jointly advancing the model.
### 1.1 The Basics of GAN Components and Operating Principles
The training process of GANs can be understood as a game between a "forger" and a "cop." The "forger" continuously attempts to create more realistic fake data, while the "cop" tries to more accurately distinguish between real and fake data. In this process, the capabilities of both sides improve, and the quality of the generated data becomes increasingly high.
### 1.2 GAN Application Domains
GAN applications are very broad, including image generation, image editing, image super-resolution, and data augmentation, among others. It can even be used to generate artworks, offering endless possibilities for artists and designers. Furthermore, GANs have tremendous potential in medical, game development, and natural language processing fields.
### 1.3 GAN Advantages and Challenges
The greatest advantage of GANs lies in their powerful generation capabilities, enabling them to generate highly realistic data without the need for extensive labeled datasets. However, GANs also face challenges, such as mode collapse, unstable training, and more. Addressing these issues requires a deep understanding of the principles and mechanisms of GANs.
# 2. Theoretical Foundations and Mathematical Principles of GANs
## 2.1 Basic Concepts and Components of GANs
### 2.1.1 The Interaction Mechanism Between Generators and Discriminators
Generative Adversarial Networks (GANs) consist of two core components: the Generator and the Discriminator. The Generator's task is to create data that looks real from random noise, while the Discriminator's task is to distinguish generated data from real data.
The training of the Generator relies on feedback from the Discriminator. During training, the Generator continuously generates data, the Discriminator evaluates its authenticity, and provides feedback. The Generator uses the information provided by the Discriminator to continuously adjust its parameters to improve the quality of the generated data.
To understand the interaction between the Generator and Discriminator, we can compare it to an adversarial game. In this game, the Generator and Discriminator compete and promote each other until they reach a balanced state where the Generator can produce data that is almost indistinguishable from real data, and the Discriminator cannot effectively differentiate between generated data and real data.
```python
# Below is a simplified code example of a GAN model
# Import necessary libraries
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, LeakyReLU
from keras.layers.advanced_activations import LeakyReLU
from keras.models import Sequential, Model
from keras.optimizers import Adam
# Architecture definition for the generator and discriminator
def build_generator(z_dim):
model = Sequential()
# Add network layers here
return model
def build_discriminator(img_shape):
model = Sequential()
# Add network layers here
return model
# Model building and compilation
z_dim = 100
img_shape = (28, 28, 1) # Example using the MNIST dataset
generator = build_generator(z_dim)
discriminator = build_discriminator(img_shape)
# During discriminator training, only the discriminator's weights are trained, and the generator's weights are set to non-trainable
discriminator.trainable = False
# Next, define the GAN model
z = Input(shape=(z_dim,))
img = generator(z)
valid = discriminator(img)
combined = Model(z, valid)
***pile(loss='binary_crossentropy', optimizer=Adam(0.0002, 0.5))
# Training logic
# Omit specific training code, but generally includes generating batches of fake and real data, then training the discriminator, followed by fixing the discriminator parameters and training the generator, iterating this process
```
### 2.1.2 Loss Functions and Optimization Goals
The training goal of GANs is to make the performance of the Generator and Discriminator as close as possible, which is typically represented as a minimax problem. Ideally, when the Generator and Discriminator reach a Nash equilibrium, the data generated by the Generator will not be effectively distinguished by the Discriminator.
Mathematically, GAN loss functions are typically defined using cross-entropy loss functions to measure the difference between generated data and real data. The Discriminator's loss function minimizes the gap between the probability of real data being recognized as true and the probability of generated data being recognized as true. Similarly, the Generator's loss function minimizes the probability of generated data being recognized as true.
```python
# GAN loss functions can take the following form
# For the Discriminator
def discriminator_loss(real_output, fake_output):
real_loss = binary_crossentropy(tf.ones_like(real_output), real_output)
fake_loss = binary_crossentropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
# For the Generator
def generator_loss(fake_output):
return binary_crossentropy(tf.ones_like(fake_output), fake_output)
```
When training GANs, we generally need to train the Discriminator and Generator alternately until the model converges. In practice, this process may require a large number of iterations and parameter adjustments to achieve the desired effect.
## 2.2 Mathematical Model Analysis of GANs
### 2.2.1 Probability Distributions and Sampling Theory
To understand how GANs work, it is necessary to first understand the concept of probability distributions. In GANs, the Generator samples from a latent space (usually a multidimensional Gaussian distribution) and then maps it to the data space through a neural network. The Discriminator tries to distinguish these generated data from the real data.
Sampling theory is a series of theories studying how to extract samples from probability distributions. In GANs, the Generator's sampling process needs to capture the key characteristics of the real data distribution to generate high-quality synthetic data. To achieve this, the Generator needs to continuously learn the structure of the real data distribution during training.
Mathematically, we can represent the Generator's sampling process as a mapping function \(G: Z \rightarrow X\), where \(Z\) is the latent space, and \(X\) is the data space. This process is parameterized by a neural network, with parameters \(\theta_G\) mapping the latent variable \(z\) to the data \(x\).
### 2.2.2 Generalization Ability and Model Capacity
Generalization ability is a machine learning model's ability to predict unseen data based on training data. The generalization ability of GANs is crucial for generating realistic data. Model capacity refers to the complexity of the model's ability to fit data. A model with too low capacity may lead to underfitting, while a model with too high capacity may lead to overfitting.
In GANs, generalization ability and model capacity are influenced by the architecture of the Generator and Discriminator. Too simple models may not capture the real data distribution, while too complex models may overfit on the training data, leading to decreased generalization performance.
To balance model capacity and generalization ability, it is usually necessary to carefully design the network architecture, and regularization techniques such as Dropout or weight decay may also be needed.
## 2.3 Challenges in GAN Training
### 2.3.1 Theoretical Explanation of Mode Collapse Issues
Mode Collapse is a severe problem in GAN training, where the Generator starts to repeatedly generate almost identical data points and no longer covers all modes of the real data distribution. This leads to a decrease in the diversity of generated data and a weakening of the model's generalization ability.
The theoretical explanation of mode collapse is usually related to the problem of gradient vanishing. When the Generator generates certain data that the Discriminator cannot effectively distinguish, the gradient information the Generator receives will be very small, causing learning to stop or proceed very slowly, thus stopping the Generator from learning.
```python
# Below is a simplified GAN training code, showing where mode collapse issues may occur
# Define the training loop
def train(epochs, batch_size=128, save_interval=50):
# Data loading and preprocessing code omitted
for epoch in range(epochs):
# Omitting the training steps for the Generator and Discriminator
# Assuming that the model training does not sufficiently
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【KEBA机器人高级攻略】:揭秘行业专家的进阶技巧

# 摘要
本论文对KEBA机器人进行全面的概述与分析,从基础知识到操作系统深入探讨,特别关注其启动、配置、任务管理和网络连接的细节。深入讨论了KEBA机器人的编程进阶技能,包括高级语言特性、路径规划及控制算法,以及机器人视觉与传感器的集成。通过实际案例分析,本文详细阐述了KEBA机器人在自动化生产线、高精度组装以及与人类协作方面的应用和优化。最后,探讨了KEBA机器人集成
【基于IRIG 106-19的遥测数据采集】:最佳实践揭秘
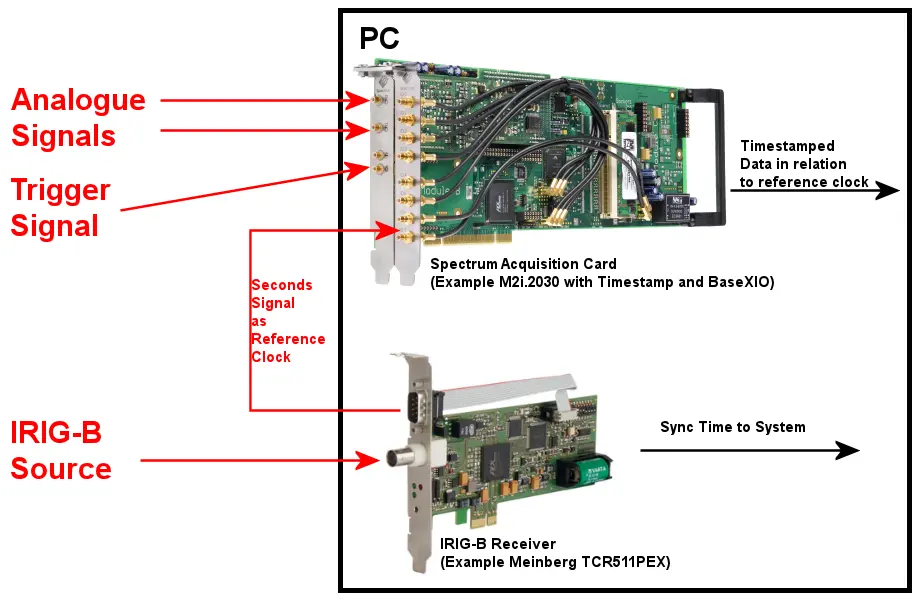
# 摘要
本文系统地介绍了IRIG 106-19标准及其在遥测数据采集领域的应用。首先概述了IRIG 106-19标准的核心内容,并探讨了遥测系统的组成与功能。其次,深入分析了该标准下数据格式与编码,以及采样频率与数据精度的关系。随后,文章详细阐述了遥测数据采集系统的设计与实现,包括硬件选型、软件框架以及系统优化策略,特别是实时性与可靠
【提升设计的艺术】:如何运用状态图和活动图优化软件界面
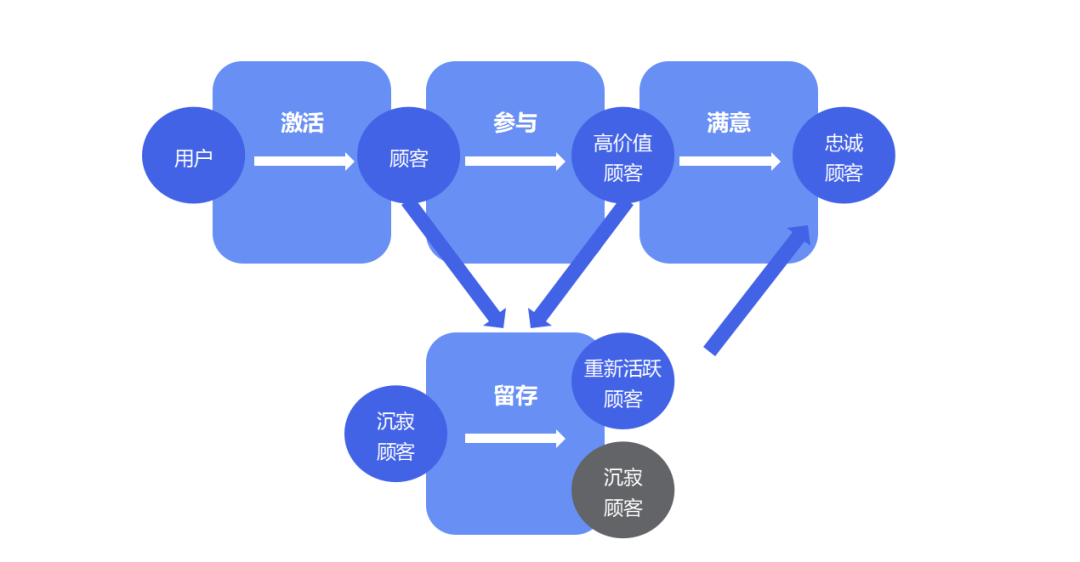
# 摘要
本文系统地探讨了状态图和活动图在软件界面设计中的应用及其理论基础。首先介绍了状态图与活动图的基本概念和组成元素,随后深入分析了在用户界面设计中绘制有效状态图和活动图的实践技巧。文中还探讨了设计原则,并通过案例分析展示了如何将这些图表有效地应用于界面设计。文章进一步讨论了状态图与活动图的互补性和结合使用,以及如何将理论知识转化为实践中的设计过程。最后,展望了面向未来的软
台达触摸屏宏编程故障不再难:5大常见问题及解决策略

# 摘要
台达触摸屏宏编程是一种为特定自动化应用定制界面和控制逻辑的有效技术。本文从基础概念开始介绍,详细阐述了台达触摸屏宏编程语言的特点、环境设置、基本命令及结构。通过分析常见故障类型和诊断方法,本文深入探讨了故障产生的根源,包括语法和逻辑错误、资源限制等。针对这
构建高效RM69330工作流:集成、测试与安全性的终极指南

# 摘要
本论文详细介绍了RM69330工作流的集成策略、测试方法论以及安全性强化,并展望了其高级应用和未来发展趋势。首先概述了RM69330工作流的基础理论与实践,并探讨了与现有系统的兼容性。接着,深入分析了数据集成的挑战、自动化工作流设计原则以及测试的规划与实施。文章重点阐述了工作流安全性设计原则、安全威胁的预防与应对措施,以及持续监控与审计的重要性。通过案例研究,展示了RM
Easylast3D_3.0速成课:5分钟掌握建模秘籍

# 摘要
Easylast3D_3.0是业界领先的三维建模软件,本文提供了该软件的全面概览和高级建模技巧。首先介绍了软件界面布局、基本操作和建模工具,然后深入探讨了材质应用、曲面建模以及动画制作等高级功能。通过实际案例演练,展示了Easylast3D_3.0在产品建模、角色创建和场景构建方面的应用。此外,本文还讨
【信号完整性分析速成课】:Cadence SigXplorer新手到专家必备指南
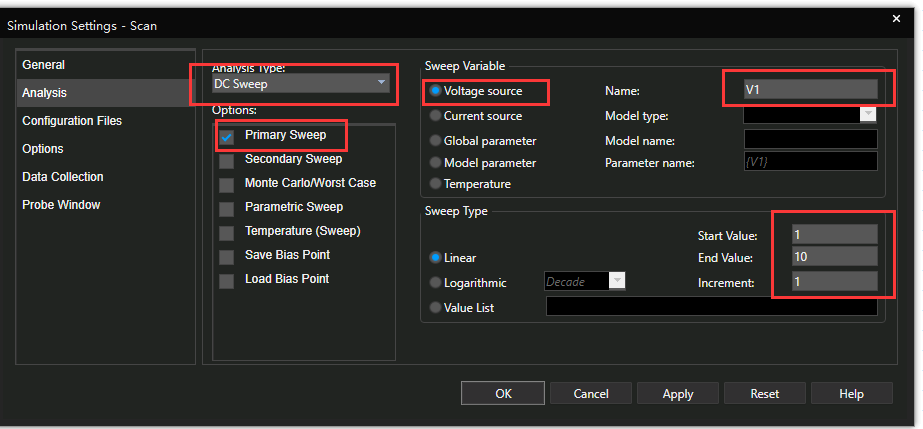
# 摘要
本论文旨在系统性地介绍信号完整性(SI)的基础知识,并提供使用Cadence SigXplorer工具进行信号完整性分析的详细指南。首先,本文对信号完整性的基本概念和理论进行了概述,为读者提供必要的背景知识。随后,重点介绍了Cadence SigXplorer界面布局、操作流程和自定义设置,以及如何优化工作环境以提高工作效率。在实践层面,论文详细解释了信号完整性分析的关键概念,包括信号衰
高速信号处理秘诀:FET1.1与QFP48 MTT接口设计深度剖析
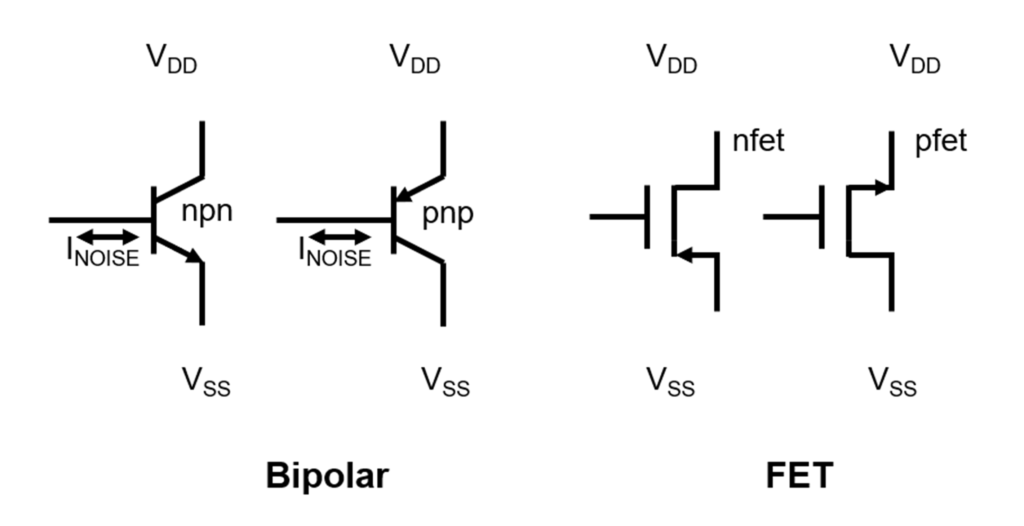
# 摘要
高速信号处理与接口设计在现代电子系统中起着至关重要的作用,特别是在数据采集、工业自动化等领域。本文首先概述了高速信号处理与接口设计的基本概念,随后深入探讨了FET1.1接口和QFP48 MTT接口的技术细节,包括它们的原理、硬件设计要点、软件驱动实现等。接着,分析了两种接口的协同设计,包括理论基础、
【MATLAB M_map符号系统】:数据点创造性表达的5种方法

# 摘要
本文详细介绍了M_map符号系统的基本概念、安装步骤、符号和映射机制、自定义与优化方法、数据点创造性表达技巧以及实践案例分析。通过系统地阐述M_map的坐标系统、个性化符号库的创建、符号视觉效果和性能的优化,本文旨在提供一种有效的方法来增强地图数据的可视化表现力。同时,文章还探讨了M_map在科学数据可视化、商业分析及教育领域的应用,并对其进阶技巧和未来的发展趋势提出了预测和建议。
物流监控智能化:Proton-WMS设备与传感器集成解决方案
# 摘要
物流监控智能化是现代化物流管理的关键组成部分,有助于提高运营效率、减少错误以及提升供应链的透明度。本文概述了Proton-WMS系统的架构与功能,包括核心模块划分和关键组件的作用与互动,以及其在数据采集、自动化流程控制和实时监控告警系统方面的实际应用。此外,文章探讨了设备与传感器集成技术的原理、兼容性考量以及解决过程中的问题。通过分析实施案例,本文揭示了Proton-WMS集成的关键成功要素,并讨论了未来技术发展趋势和系统升级规划,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )