【Algorithm Optimization】: GAN Training Efficiency Enhancement Guide: Quickly Build Efficient AI Models
发布时间: 2024-09-15 16:40:39 阅读量: 25 订阅数: 33 
# 【Algorithm Optimization】: Tips to Improve GAN Training Efficiency: Quickly Build Efficient AI Models
## 1. Fundamentals and Challenges of Generative Adversarial Networks (GANs)
### 1.1 Basic Concepts and Principles of GANs
Generative Adversarial Networks (GANs) consist of two parts: the Generator and the Discriminator. The Generator's job is to create as realistic data as possible, while the Discriminator's task is to differentiate between generated data and real data. During training, the Generator and Discriminator compete against each other, enhancing the model through adversarial means.
### 1.2 Challenges and Problems of GANs
Although GANs show great potential in many fields, they still face many challenges. For example, the mode collapse problem, where the data generated by the Generator is too singular and lacks diversity; and the problem of unstable training, which is manifested by the difficulty in reaching a balance between the Generator and Discriminator, leading to training that is hard to converge. These issues need to be resolved in practical applications.
### 1.3 Value of GANs in Practical Applications
GANs can be used not only for image generation and editing but also for image-to-image translation, style transfer, text-to-image generation, and more. Their emergence has greatly propelled the development of AI and shown significant application value in many fields.
# 2. GAN Optimization Strategies within Theoretical Frameworks
## 2.1 Mathematical Principles and Architecture of GANs
### 2.1.1 Theoretical Basis of Adversarial Networks
The fundamental idea of Generative Adversarial Networks (GAN) is to improve performance by training two neural networks—the Generator and the Discriminator—in mutual opposition. The Generator's goal is to produce data close to the real distribution, while the Discriminator attempts to distinguish between generated data and real data. This adversarial process can be seen as a zero-sum game, where the Generator and Discriminator improve their abilities in continuous opposition.
In this framework, the Generator G and Discriminator D are trained using the following two loss functions:
- For the Generator G, the goal is to minimize D(G(z)), that is, to increase the probability of the generated data being misclassified by the Discriminator.
- For the Discriminator D, the goal is to maximize D(x) + D(G(z)), that is, to correctly distinguish between real data and generated data.
In practice, training GANs is often very difficult. The difficulties mainly come from two aspects:
- Mode Collapse: The Generator may discover some specific inputs that can deceive the Discriminator, and therefore repeatedly generate these inputs, resulting in insufficient diversity in the generated data.
- Unstable Training: Due to the nonlinearity and non-stationarity of GAN training, the training process can easily fall into an unstable state, which may manifest as oscillations in the performance of the Discriminator or Generator.
### 2.1.2 Analysis of GAN Loss Functions
The loss function is the core of GAN training. In traditional GAN models, binary cross-entropy loss functions are used. However, with the deepening of research, a series of improved loss functions have emerged to solve problems during training.
- WGAN (Wasserstein GAN): By using the Wasserstein distance to measure the difference between the real data distribution and the generated data distribution, WGAN has improved the training stability of GANs and is able to generate higher quality samples.
- LSGAN (Least Squares GAN): Using least squares loss instead of binary cross-entropy loss can result in a more stable training process and higher quality generated images.
- DCGAN (Deep Convolutional GAN): By introducing convolutional neural networks, the training process of GANs and the clarity of the generated images have been improved.
From a mathematical perspective, optimizing GANs is equivalent to solving a minimax problem. A typical GAN loss function can be represented as:
```python
# Pseudocode
def GAN_loss(generator, discriminator, real_data, fake_data):
# Calculate the Generator's loss
gen_loss = -log(discriminator(fake_data))
# Calculate the Discriminator's loss
real_loss = -log(discriminator(real_data))
fake_loss = log(1 - discriminator(fake_data))
disc_loss = real_loss + fake_loss
return gen_loss, disc_loss
```
In practical applications, it is often necessary to design and adjust the loss function more carefully to adapt to different datasets and tasks.
## 2.2 Stability and Convergence During Training
### 2.2.1 Tips for Stabilizing GAN Training
To avoid mode collapse and unstable training, researchers have proposed a series of techniques and strategies, which in practice have proven to be effective:
- **Gradient Penalty**: The gradient penalty introduced in WGAN is an effective strategy to prevent excessive changes in the Generator that lead to unstable training.
- **Learning Rate Decay**: Gradually decreasing the learning rate as the training progresses helps the model converge more stably.
- **Using Batch Normalization**: Adding Batch Normalization between layers of the Generator and Discriminator can help stabilize the training process and improve performance.
```python
# Pseudocode
def gradient_penalty(discriminator, real_data, fake_data, lambda):
# Calculate mixed data
alpha = torch.rand(real_data.size(0), 1, 1, 1)
interpolates = alpha * real_data + (1 - alpha) * fake_data
interpolates = autograd.Variable(interpolates, requires_grad=True)
# Calculate discriminator output for mixed data
disc_interpolates = discriminator(interpolates)
# Calculate gradients
gradients = autograd.grad(outputs=disc_interpolates, inputs=interpolates,
grad_outputs=torch.ones(disc_interpolates.size()).to(device),
create_graph=True, retain_graph=True, only_inputs=True)[0]
# Calculate gradient norm penalty
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * lambda
return gradient_penalty
```
### 2.2.2 Convergence Analysis and Improvement Methods
The convergence of GANs is a complex theoretical problem because the training process of GANs is a dynamic adversarial process. Improving GAN convergence can start from the following aspects:
- **Carefully Designed Initialization**: Reasonable initialization of the Generator and Discriminator weights helps the start of training, preventing the model from falling into mode collapse or overfitting at the beginning.
- **Hierarchical Training**: Train a simpler model first, then use the learned features as a starting point for a higher-level model.
- **Improved Optimization Algorithms**: Using adaptive learning rate optimization algorithms such as Adam, RMSprop can help the model converge faster.
By combining these techniques, the GAN training process can become more stable and predictable in practical applications.
## 2.3 The Art of Hyperparameter Tuning
### 2.3.1 How to Choose and Adjust Hyperparameters
The choice of hyperparameters has a significant impact on GAN performance. Hyperparameters include, but are not limited to:
- Learning Rate: Controls the step size of weight updates.
- Batch Size: The number of data samples used for weight updates each time.
- Network Layers and Units: This determines the depth and width of the network.
Basic strategies for adjusting hyperparameters include:
- **Start Small and Go Big**: Start with a smaller batch size and learning rate, gradually increase, and observe the model's training performance.
- **Grid Search**: Perform a rough grid search within a reasonable range of hyperparameters to find a point with relatively good performance.
- **Adaptive Adjustment**: Adjust hyperparameters such as learning rate adaptively as the m

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
潮流分析的艺术:PSD-BPA软件高级功能深度介绍

# 摘要
电力系统分析在保证电网安全稳定运行中起着至关重要的作用。本文首先介绍了潮流分析的基础知识以及PSD-BPA软件的概况。接着详细阐述了PSD-BPA的潮流计算功能,包括电力系统的基本模型、潮流计算的数学原理以及如何设置潮流计算参数。本文还深入探讨了PSD-BPA的高级功
RTC4版本迭代秘籍:平滑升级与维护的最佳实践

# 摘要
本文重点讨论了RTC4版本迭代的平滑升级过程,包括理论基础、实践中的迭代与维护,以及维护与技术支持。文章首先概述了RTC4的版本迭代概览,然后详细分析了平滑升级的理论基础,包括架构与组件分析、升级策略与计划制定、技术要点。在实践章节中,本文探讨了版本控制与代码审查、单元测试
嵌入式系统中的BMP应用挑战:格式适配与性能优化
# 摘要
本文综合探讨了BMP格式在嵌入式系统中的应用,以及如何优化相关图像处理与系统性能。文章首先概述了嵌入式系统与BMP格式的基本概念,并深入分析了BMP格式在嵌入式系统中的应用细节,包括结构解析、适配问题以及优化存储资源的策略。接着,本文着重介绍了BMP图像的处理方法,如压缩技术、渲染技术以及资源和性能优化措施。最后,通过具体应用案例和实践,展示了如何在嵌入式设备中有效利用BMP图像,并探讨了开发工具链的重要性。文章展望了高级图像处理技术和新兴格式的兼容性,以及未来嵌入式系统与人工智能结合的可能方向。
# 关键字
嵌入式系统;BMP格式;图像处理;性能优化;资源适配;人工智能
参考资
SSD1306在智能穿戴设备中的应用:设计与实现终极指南
# 摘要
SSD1306是一款广泛应用于智能穿戴设备的OLED显示屏,具有独特的技术参数和功能优势。本文首先介绍了SSD1306的技术概览及其在智能穿戴设备中的应用,然后深入探讨了其编程与控制技术,包括基本编程、动画与图形显示以及高级交互功能的实现。接着,本文着重分析了SSD1306在智能穿戴应用中的设计原则和能效管理策略,以及实际应用中的案例分析。最后,文章对SSD1306未来的发展方向进行了展望,包括新型显示技术的对比、市场分析以及持续开发的可能性。
# 关键字
SSD1306;OLED显示;智能穿戴;编程与控制;用户界面设计;能效管理;市场分析
参考资源链接:[SSD1306 OLE
ECOTALK数据科学应用:机器学习模型在预测分析中的真实案例

# 摘要
本文对机器学习模型的基础理论与技术进行了综合概述,并详细探讨了数据准备、预处理技巧、模型构建与优化方法,以及预测分析案例研究。文章首先回顾了机器学习的基本概念和技术要点,然后重点介绍了数据清洗、特征工程、数据集划分以及交叉验证等关键环节。接
PM813S内存管理优化技巧:提升系统性能的关键步骤,专家分享!
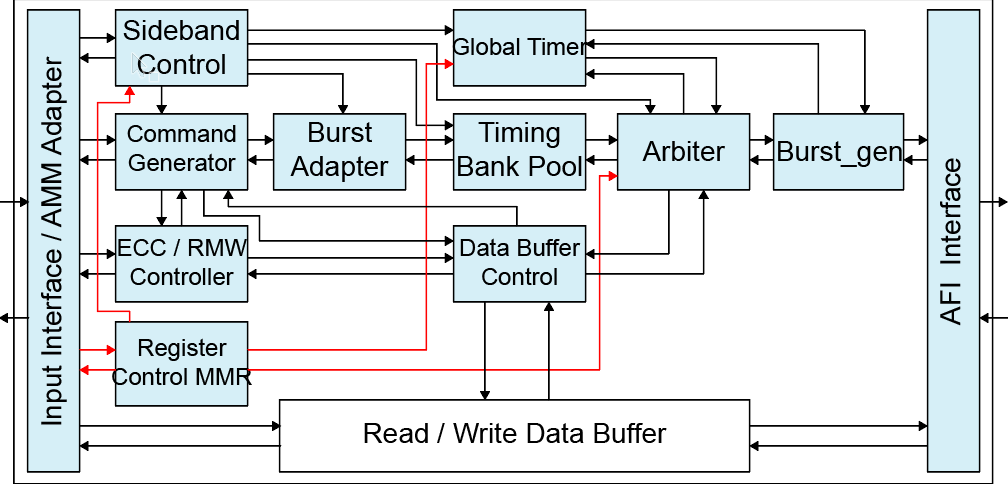
# 摘要
PM813S作为一款具有先进内存管理功能的系统,其内存管理机制对于系统性能和稳定性至关重要。本文首先概述了PM813S内存管理的基础架构,然后分析了内存分配与回收机制、内存碎片化问题以及物理与虚拟内存的概念。特别关注了多级页表机制以及内存优化实践技巧,如缓存优化和内存压缩技术的应用。通过性能评估指标和调优实践的探讨,本文还为系统监控和内存性能提
CC-LINK远程IO模块AJ65SBTB1现场应用指南:常见问题快速解决
# 摘要
CC-LINK远程IO模块作为一种工业通信技术,为自动化和控制系统提供了高效的数据交换和设备管理能力。本文首先概述了CC-LINK远程IO模块的基础知识,接着详细介绍了其安装与配置流程,包括硬件的物理连接和系统集成要求,以及软件的参数设置与优化。为应对潜在的故障问题,本文还提供了故障诊断与排除的方法,并探讨了故障解决的实践案例。在高级应用方面,文中讲述了如何进行编程与控制,以及如何实现系统扩展与集成。最后,本文强调了CC-LINK远程IO模块的维护与管理的重要性,并对未来技术发展趋势进行了展望。
# 关键字
CC-LINK远程IO模块;系统集成;故障诊断;性能优化;编程与控制;维护
【光辐射测量教育】:IT专业人员的培训课程与教育指南

# 摘要
光辐射测量是现代科技中应用广泛的领域,涉及到基础理论、测量设备、技术应用、教育课程设计等多个方面。本文首先介绍了光辐射测量的基础知识,然后详细探讨了不同类型的光辐射测量设备及其工作原理和分类选择。接着,本文分析了光辐射测量技术及其在环境监测、农业和医疗等不同领域的应用实例。教育课程设计章节则着重于如何构建理论与实践相结合的教育内容,并提出了评估与反馈机制。最后,本文展望了光辐射测量教育的未来趋势,讨论了技术发展对教育内容和教
【Ubuntu 16.04系统更新与维护】:保持系统最新状态的策略
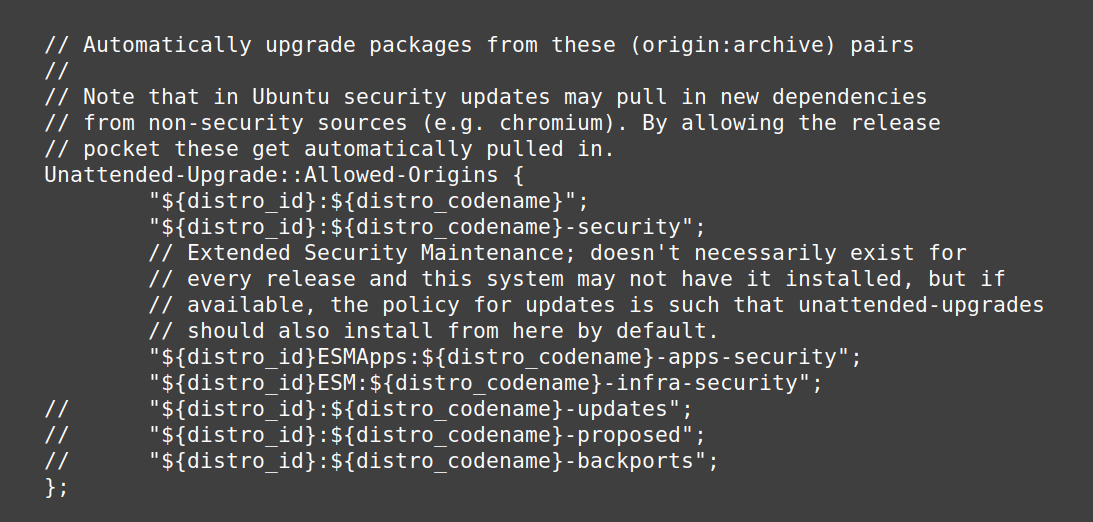
# 摘要
本文针对Ubuntu 16.04系统更新与维护进行了全面的概述,探讨了系统更新的基础理论、实践技巧以及在更新过程中可能遇到的常见问题。文章详细介绍了安全加固与维护的策略,包括安全更新与补丁管理、系统加固实践技巧及监控与日志分析。在备份与灾难恢复方面,本文阐述了
分析准确性提升之道:谢菲尔德工具箱参数优化攻略

# 摘要
本文介绍了谢菲尔德工具箱的基本概念及其在各种应用领域的重要性。文章首先阐述了参数优化的基础理论,包括定义、目标、方法论以及常见算法,并对确定性与随机性方法、单目标与多目标优化进行了讨论。接着,本文详细说明了谢菲尔德工具箱的安装与配置过程,包括环境选择、参数配置、优化流程设置以及调试与问题排查。此外,通过实战演练章节,文章分析了案例应用,并对参数调优的实验过程与结果评估给出了具体指
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )