【Algorithm Comparison】: A Major Contest of GAN Architecture Performance: Who is the Pioneer of Deep Learning?
发布时间: 2024-09-15 16:35:56 阅读量: 18 订阅数: 23 
# 1. Introduction to Generative Adversarial Networks (GANs)
In the field of artificial intelligence, Generative Adversarial Networks (GANs) are a class of generative models that are trained using deep learning techniques. They learn data distributions through an adversarial process and create new instances of data. Since being proposed by Ian Goodfellow in 2014, GANs have garnered widespread attention from researchers and industry due to their powerful data generation capabilities.
The fundamental concept of GAN is to view the training process as a game between two neural networks: the Generator and the Discriminator. The Generator aims to produce data that is as realistic as possible, while the Discriminator tries to distinguish between generated data and real data. This adversarial mechanism is unique to GANs; it encourages both networks to progress interactively, ultimately allowing the Generator to produce outputs indistinguishable from real data.
This chapter will introduce the principles and architecture of GANs, as well as their potential applications across various fields, providing readers with a comprehensive understanding of GANs.
# 2. Basic Theory and Architecture of GANs
### 2.1 Theoretical Basis of GANs
#### 2.1.1 How GANs Work
Generative Adversarial Networks (GANs) consist of two primary components: the Generator and the Discriminator. During training, the goal of the Generator is to create fake data that closely resembles the true data distribution, while the Discriminator's goal is to differentiate between real and fake data generated by the Generator.
The Generator takes a random noise vector z as input and maps it to the data space through the network, outputting a sample G(z) that is尽可能 close to the real data. The Discriminator, on the other hand, receives a data sample x as input and outputs the probability D(x) that the sample comes from the real data distribution.
When training a GAN, the objective function often takes the form of a logarithmic function. The training goal for the Generator is to minimize the log-likelihood function log(1-D(G(z))), while the Discriminator aims to maximize the log-likelihood function log(D(x)) + log(1-D(G(z))).
The code block below demonstrates a simple GAN structure:
```python
import torch
import torch.nn as nn
# Generator network structure
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
# Network layer details omitted for brevity
)
def forward(self, z):
return self.main(z)
# Discriminator network structure
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# Network layer details omitted for brevity
)
def forward(self, x):
return self.main(x)
# Initialize models and optimizers
generator = Generator()
discriminator = Discriminator()
g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0002)
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0002)
```
In the above code, the `Generator` and `Discriminator` classes define the structures of the Generator and Discriminator, respectively. The `forward` method defines the forward propagation of the network layers. The `g_optimizer` and `d_optimizer` are used to optimize the parameters of the Generator and Discriminator.
#### 2.1.2 Key Components of GANs
The key components of GANs include the Generator and the Discriminator. The Generator learns to produce samples that increasingly approach the true data distribution, while the Discriminator gradually enhances its ability to discern real data from fake data.
The Generator consists of multiple fully connected layers, convolutional layers, or transposed convolutional layers, aiming to capture the true data distribution. To achieve this, the Generator typically includes a random noise input that is mapped through the neural network layer by layer to ultimately generate realistic data samples.
The Discriminator is a binary classifier that aims to give the probability that input data is real or fake data generated by the Generator. Like the Generator, the Discriminator is composed of multiple fully connected layers, convolutional layers, or pooling layers, and its recognition ability can be improved through training.
### 2.2 Common Variants of GAN Architectures
#### 2.2.1 Principles and Applications of DCGAN
The Deep Convolutional Generative Adversarial Network (DCGAN) is an important variant of GAN. It incorporates the structures of Convolutional Neural Networks (CNNs) into GANs, allowing the network to learn to generate high-resolution images more effectively. DCGAN uses deep convolutional layers in place of traditional fully connected layers and introduces Batch Normalization techniques to improve training stability.
DCGAN has a wide range of applications, including art creation, face image generation, and medical image analysis. Its exceptional image generation capabilities make it stand out in these fields.
The code block below shows an example of a convolutional layer in the Discriminator of DCGAN:
```python
class Discriminator(nn.Module):
# ... (other parts of the code)
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 64, 4, stride=2, padding=1), # Input channels 3, output channels 64
nn.LeakyReLU(negative_slope=0.2, inplace=True),
# ... (other convolutional layers)
)
def forward(self, x):
return self.main(x)
```
In the above code, `Conv2d` is the convolutional layer, and `LeakyReLU` is an activation function. Input images are processed through the convolutional layers and activation functions to extract features progressively, which are then passed to the classifier for real vs. fake data judgment.
#### 2.2.2 Innovations in CycleGAN
CycleGAN is a special architecture of GANs that innovates by not requiring paired training data to achieve image transformation between two different domains. CycleGAN imposes cycle consistency constraints (Cycle Consistency Loss) on two different Generators and Discriminators, allowing the model to learn the mapping between domains without relying on paired samples.
This architecture has shown its superiority in tasks such as style transfer, image-to-image translation, and seasonal image generation.
The code block below demonstrates the cycle consistency loss function in CycleGAN:
```python
def cycle_consistency_loss(real_A, reconstructed_A, lambda_weight):
loss = torch.mean(torch.abs(real_A - reconstructed_A))
return lambda_weight * loss
```
Here, `real_A` is an image from domain A, `reconstructed_A` is the result of an image being transformed through domain B and then back to domain A by the A-domain Generator. `lambda_weight` is the weight for the cycle consistency loss, used to balance this loss term's contribution to the overall loss.
#### 2.2.3 Analysis of StyleGAN Advantages
StyleGAN introduces operations in the latent space within the GAN architecture, allowing the model to control attributes of the generated images, such as pose, expression, and hair. StyleGAN introduces a latent style space (W-space) and a series of mapping networks, permitting more detailed and specific control over the generated images.
The advantage of StyleGAN lies in the higher quality, more detailed, and higher-resolution images it generates. Additionally, it allows users to create images with specific styles or attributes by modifying vectors in the W-space.
### 2.3 Performance Evaluation Standards for GANs
#### 2.3.1 FID and Inception Score
A common metric for evaluating the quality of images generated by GANs is the Fréchet Inception Distance (FID) score, which assesses the Generator's performance by comparing the distribution difference of real and generated images in feature space. A lower FID score indicates higher quality generated images.
Another commonly used evaluation metric is the Inception Score (IS), which uses a pre-trained Inception model to evaluate the diversity and quality of generated images. The Inception Score combines the assessment of both the quality and diversity of generated images, with a higher IS score indicating more realistic and diverse images.
The table below compares the FID and IS scores of different GAN models on standard datasets:
| Model | FID | Inception Score |
|--------------|-------|-----------------|
| StyleGAN | 12.8 | 19.6 |
| BigGAN | 15.6

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【R语言数据预处理全面解析】:数据清洗、转换与集成技术(数据清洗专家)

# 1. R语言数据预处理概述
在数据分析与机器学习领域,数据预处理是至关重要的步骤,而R语言凭借其强大的数据处理能力在数据科学界占据一席之地。本章节将概述R语言在数据预处理中的作用与重要性,并介绍数据预处理的一般流程。通过理解数据预处理的基本概念和方法,数据科学家能够准备出更适合分析和建模的数据集。
## 数据预处理的重要性
数据预处理在数据分析中占据核心地位,其主要目的是将原
【R语言热力图解读实战】:复杂热力图结果的深度解读案例
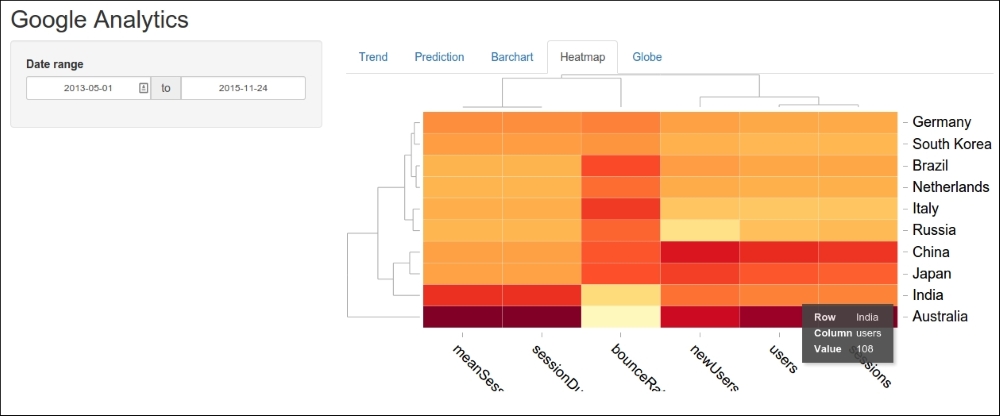
# 1. R语言热力图概述
热力图是数据可视化领域中一种重要的图形化工具,广泛用于展示数据矩阵中的数值变化和模式。在R语言中,热力图以其灵活的定制性、强大的功能和出色的图形表现力,成为数据分析与可视化的重要手段。本章将简要介绍热力图在R语言中的应用背景与基础知识,为读者后续深入学习与实践奠定基础。
热力图不仅可以直观展示数据的热点分布,还可以通过颜色的深浅变化来反映数值的大小或频率的高低,
【R语言图表演示】:visNetwork包,揭示复杂关系网的秘密

# 1. R语言与visNetwork包简介
在现代数据分析领域中,R语言凭借其强大的统计分析和数据可视化功能,成为了一款广受欢迎的编程语言。特别是在处理网络数据可视化方面,R语言通过一系列专用的包来实现复杂的网络结构分析和展示。
visNetwork包就是这样一个专注于创建交互式网络图的R包,它通过简洁的函数和丰富
【R语言交互式数据探索】:DataTables包的实现方法与实战演练

# 1. R语言交互式数据探索简介
在当今数据驱动的世界中,R语言凭借其强大的数据处理和可视化能力,已经成为数据科学家和分析师的重要工具。本章将介绍R语言中用于交互式数据探索的工具,其中重点会放在DataTables包上,它提供了一种直观且高效的方式来查看和操作数据框(data frames)。我们会
【R语言生态学数据分析】:vegan包使用指南,探索生态学数据的奥秘
# 1. R语言在生态学数据分析中的应用
生态学数据分析的复杂性和多样性使其成为现代科学研究中的一个挑战。R语言作为一款免费的开源统计软件,因其强大的统计分析能力、广泛的社区支持和丰富的可视化工具,已经成为生态学研究者不可或缺的工具。在本章中,我们将初步探索R语言在生态学数据分析中的应用,从了解生态学数据的特点开始,过渡到掌握R语言的基础操作,最终将重点放在如何通过R语言高效地处理和解释生态学数据。我们将通过具体的例子和案例分析,展示R语言如何解决生态学中遇到的实际问题,帮助研究者更深入地理解生态系统的复杂性,从而做出更为精确和可靠的科学结论。
# 2. vegan包基础与理论框架
##
Highcharter包创新案例分析:R语言中的数据可视化,新视角!

# 1. Highcharter包在数据可视化中的地位
数据可视化是将复杂的数据转化为可直观理解的图形,使信息更易于用户消化和理解。Highcharter作为R语言的一个包,已经成为数据科学家和分析师展示数据、进行故事叙述的重要工具。借助Highcharter的高级定制
【R语言图表美化】:ggthemer包,掌握这些技巧让你的数据图表独一无二

# 1. ggthemer包介绍与安装
## 1.1 ggthemer包简介
ggthemer是一个专为R语言中ggplot2绘图包设计的扩展包,它提供了一套更为简单、直观的接口来定制图表主题,让数据可视化过程更加高效和美观。ggthemer简化了图表的美化流程,无论是对于经验丰富的数据
【R语言网络图数据过滤】:使用networkD3进行精确筛选的秘诀
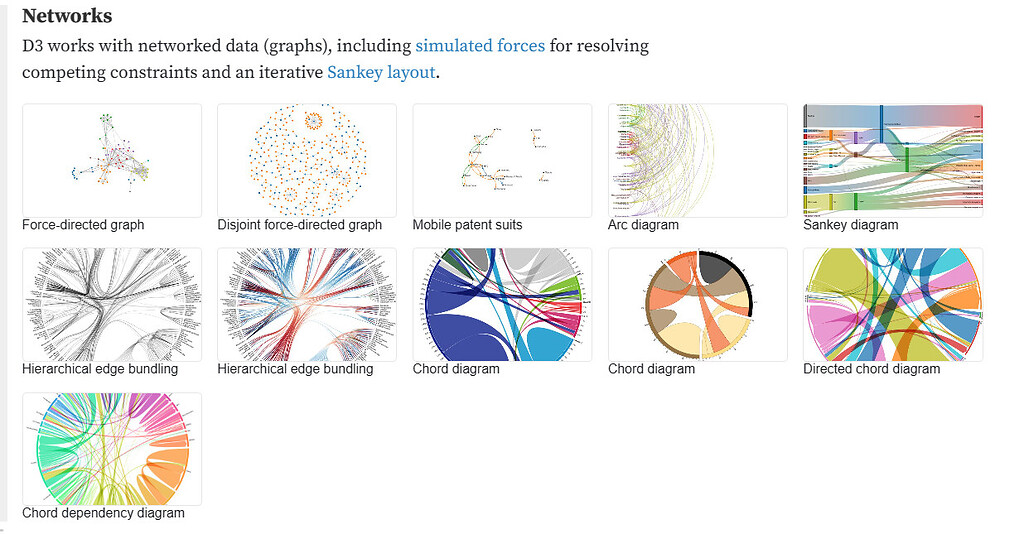
# 1. R语言与网络图分析的交汇
## R语言与网络图分析的关系
R语言作为数据科学领域的强语言,其强大的数据处理和统计分析能力,使其在研究网络图分析上显得尤为重要。网络图分析作为一种复杂数据关系的可视化表示方式,不仅可以揭示出数据之间的关系,还可以通过交互性提供更直观的分析体验。通过将R语言与网络图分析相结合,数据分析师能够更
rgwidget在生物信息学中的应用:基因组数据的分析与可视化
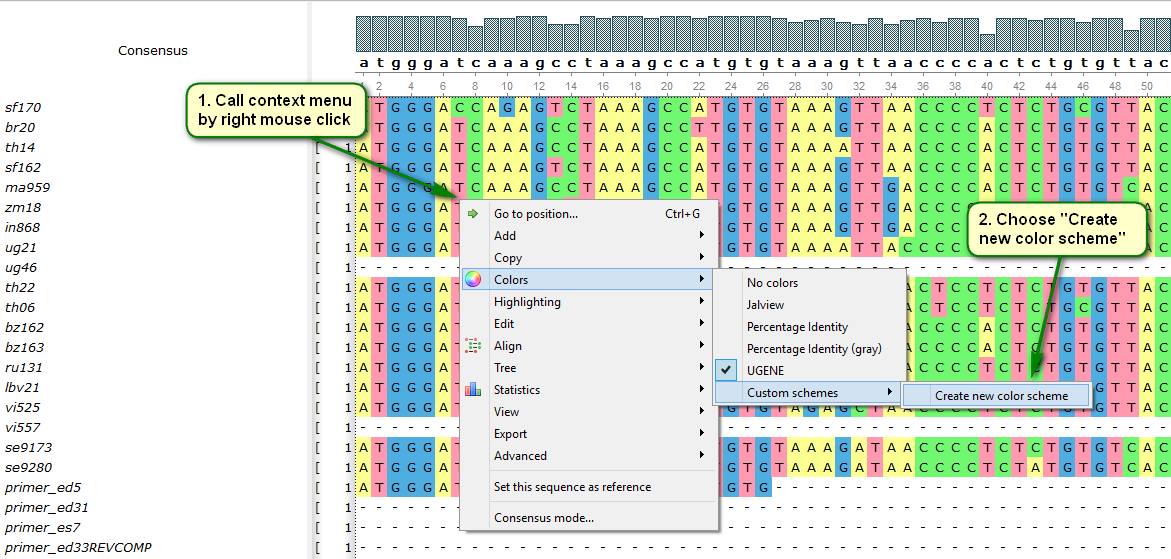
# 1. 生物信息学与rgwidget简介
生物信息学是一门集生物学、计算机科学和信息技术于一体的交叉学科,它主要通过信息化手段对生物学数据进行采集、处理、分析和解释,从而促进生命科学的发展。随着高通量测序技术的进步,基因组学数据呈现出爆炸性增长的趋势,对这些数据进行有效的管理和分析成为生物信息学领域的关键任务。
rgwidget是一个专为生物信息学领域设计的图形用户界面工具包,它旨在简化基因组数据的分析和可视化流程。rgwidge
【R语言数据美颜】:RColorBrewer包应用详解,提升图表美感
# 1. RColorBrewer包概述与安装
RColorBrewer是一个专门为R语言设计的包,它可以帮助用户轻松地为数据可视化选择色彩。通过提供预先定义好的颜色方案,这个包能够帮助数据分析师和数据科学家创建美观、具有代表性的图表和地图。
## 1.1 包的安装和初步了解
在开始使用RColorBrewer之前,需要确保已经安装了R包。可以使用以下命令进行安装:
```R
install.packages("RColorBrewer")
```
安装完成后,使用`library()`函数来加载包:
```R
library(RColorBrewer)
```
## 1.2 颜
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )