[Model Debugging]: GAN Training Troubleshooting Guide: Expert Tips for Resolving Common Issues
发布时间: 2024-09-15 16:54:07 阅读量: 39 订阅数: 33 

debugging:改进您的打印调试
## 1.1 Introduction to GANs
Generative Adversarial Networks (GANs) consist of two neural networks: the Generator and the Discriminator. The Generator is responsible for creating data, while the Discriminator evaluates the authenticity of the data. During training, the Generator and Discriminator continuously compete with each other. The Generator aims to deceive the Discriminator into thinking its generated data is real, while the Discriminator strives to distinguish between real and generated data.
## 1.2 Applications of GANs
GANs are widely applied in various fields such as image generation, style transfer, and data augmentation. For example, in image generation, GANs can produce highly realistic pictures, which are significantly applied in game development and film special effects creation. In the field of style transfer, GANs can transfer the style of one image onto another, facilitating artistic creation and design applications.
## 1.3 Basic Steps of GAN Training
The training process of a GAN typically involves the following basic steps:
1. **Initialize Networks**: Randomly initialize the weights of the Generator and Discriminator.
2. **Prepare Dataset**: Prepare the input dataset for training the GAN.
3. **Training Loop**: Iterative process where the Generator tries to fool the Discriminator, and the Discriminator tries to detect the generated data.
4. **Evaluation and Adjustment**: Assess model performance based on the loss function and adjust model parameters if necessary.
5. **Model Saving**: Save the trained model for later use and optimization.
Maintaining a balance between the two networks is crucial during GAN training. If one network is too strong, the training process could fail. For instance, if the Discriminator is too powerful, the Generator will struggle to make progress, and vice versa. Therefore, adjusting the learning rate, network architecture, and training techniques are key factors in successfully training a GAN.
## 2. Overview of Model Debugging Theory
## 2.1 Theoretical Basis of Model Training
### 2.1.1 Basic Concepts of Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) consist of two networks: a Generator and a Discriminator. The Generator's task is to create data that is as realistic as possible, while the Discriminator's task is to differentiate between generated and real data. During training, the Generator continuously tries to produce higher quality data, and the Discriminator keeps improving its ability to distinguish. This adversarial mechanism prompts both networks to make progress until the Generator can produce convincing results.
The training process of GANs can be seen as a game of cat-and-mouse between two parties. To effectively train GANs, it is necessary to maintain a balance between the Generator and Discriminator, preventing one from becoming too dominant, which could lead to training failure.
### 2.1.2 Training Dynamics and Stability Analysis of GANs
A major challenge in training GANs is ensuring stability. Since the training of GANs is fundamentally a dynamic process, it requires careful design of training strategies to maintain system stability. For example, using different learning rates, batch normalization, weight initialization, ***
***mon issues in GAN training dynamics include mode collapse, where the Generator begins to produce a very limited range of data, making it easy for the Discriminator to recognize the generated data. To address this problem, researchers have developed various techniques, such as minimizing the Wasserstein distance (WGAN) and introducing label smoothing, to improve training stability.
## 2.2 Model Performance Evaluation
### 2.2.1 Definition and Importance of Evaluation Metrics
In GAN training, performance evaluation is very important as it helps us understand the model'***mon evaluation metrics include the Inception Score (IS), Fréchet Inception Distance (FID), and Precision & Recall. The IS focuses on the diversity and quality of generated images, while the FID focuses on the similarity between generated images and real images. Precision & Recall evaluate GAN performance from the perspective of classification accuracy and recall rate.
Each metric has its focus, so in practice, multiple metrics should be combined for a comprehensive performance evaluation. Additionally, these metrics can guide the model's tuning. For example, a high FID value indicates that the model is not doing well in reproducing the real data distribution and may require adjustments to the model structure or training strategy.
### 2.2.2 Analysis and Selection of Loss Functions
The loss function is an important tool for guiding model learning. In GANs, different loss functions can lead to different training behaviors and performance. Traditional GANs use cross-entropy loss functions, but subsequent research has proposed various improved versions, such as Least Squares GAN (LSGAN) and Wasserstein GAN (WGAN).
The choice of loss function is key to balancing the adversarial process between the Generator and Discriminator. For example, the Wasserstein distance in WGAN can provide smoother and continuous gradient information, helping to alleviate the gradient vanishing problem and allowing for more stable training. The choice of loss function has a decisive impact on the training dynamics and final performance of GANs.
## 2.3 Debugging Methodology
### 2.3.1 Common Problems and Challenges in Debugging
During the debugging process of a GAN, the model may encounter various problems, including but not limited to mode collapse, gradient vanishing or explosion, overfitting, and underfitting. The existence of these problems leads to unstable training or poor results. Understanding the mechanisms behind these problems is crucial for adopting targeted debugging strategies.
For example, gradient vanishing and explosion problems can be addressed through gradient clipping or by using appropriate optimizers. Overfitting can be alleviated by adding more data, introducing regularization techniques, or reducing model complexity. Identifying the nature of the problem is the first step in solving it.
### 2.3.2 Debugging Strategies and Best Practices
Best practices for debugging GANs include, but are not limited to: ensuring sufficient training time to prevent underfitting; using appropriate batch sizes and learning rates to maintain training stability; implementing regularization strategies to prevent overfitting; and using techniques like early stopping to avoid unnecessary computational overhead.
Specifically, various debugging tools and techniques can be used to monitor and diagnose problems during model training. For instance, by visualizing the changes in the loss functions of the Generator and Discriminator, one can observe whether the training has fallen into local minima or mode collapse. In practice, adjusting the model structure or parameters and gradually improving model performance is an effective strategy for debugging GANs.
## 3. GAN Training Failure Diagnosis
In the field of deep learning, Generative Adversarial Networks (GANs) are widely popular for their ability to generate realistic data. However, their training process is complex and susceptible to various issues, leading to model collapse, instability, or poor generation quality. To master the GAN training process and address potential problems, this chapter will delve into various aspects of GAN training failure diagnosis.
## 3.1 Model Collapse and Instability Issues
### 3.1.1 Typical Causes and Solutions for Model Collapse
Model collapse refers to a situation during GAN training where the Generator or Discriminator completely fails, causing training to cease. This phenomenon can be caused by various factors, including but not limited to inappropriate loss function design, incorrect network architecture choice, poor parameter initialization, or excessively high learning rates.
**Typical Causes**:
1. **Inappropriate Loss Function Design**: If the loss function is overly simplified or fails to effectively guide network learning, the model may quickly collapse.
2. **Incorrect Network Architecture**: The choice of network architecture should be based on specific tasks and data characteristics. A network that is too simple may not capture the complexity of the data, while a network that is too complex may lead to overfitting or unstable training.
3. **Improper Parameter Initialization**: Proper parameter initialization is crucial for model training. Improper initialization may lead to excessively large or small outputs from the model at the beginning of training, subsequently causing collapse.
4. **High Learning Rate**: A high learning rate can cause excessively large parameter updates, preventing the model from converging.
**Solutions**:
1. **Optimize the Loss Function**: Design the loss function based on task characteristics, introducing auxiliary loss terms to enhance training stability.
2. **Choose Appropriate Network Architecture**: Design a reasonable network structure or select an architecture that has proven effective in similar tasks.
3. **Improve Parameter Initialization Strategy**: Adopt appropriate parameter initialization methods, such as He or Glorot initialization.
4. **Adjust the Learning Rate**: Use adapti

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
嵌入式系统中的BMP应用挑战:格式适配与性能优化
# 摘要
本文综合探讨了BMP格式在嵌入式系统中的应用,以及如何优化相关图像处理与系统性能。文章首先概述了嵌入式系统与BMP格式的基本概念,并深入分析了BMP格式在嵌入式系统中的应用细节,包括结构解析、适配问题以及优化存储资源的策略。接着,本文着重介绍了BMP图像的处理方法,如压缩技术、渲染技术以及资源和性能优化措施。最后,通过具体应用案例和实践,展示了如何在嵌入式设备中有效利用BMP图像,并探讨了开发工具链的重要性。文章展望了高级图像处理技术和新兴格式的兼容性,以及未来嵌入式系统与人工智能结合的可能方向。
# 关键字
嵌入式系统;BMP格式;图像处理;性能优化;资源适配;人工智能
参考资
【光辐射测量教育】:IT专业人员的培训课程与教育指南

# 摘要
光辐射测量是现代科技中应用广泛的领域,涉及到基础理论、测量设备、技术应用、教育课程设计等多个方面。本文首先介绍了光辐射测量的基础知识,然后详细探讨了不同类型的光辐射测量设备及其工作原理和分类选择。接着,本文分析了光辐射测量技术及其在环境监测、农业和医疗等不同领域的应用实例。教育课程设计章节则着重于如何构建理论与实践相结合的教育内容,并提出了评估与反馈机制。最后,本文展望了光辐射测量教育的未来趋势,讨论了技术发展对教育内容和教
ECOTALK数据科学应用:机器学习模型在预测分析中的真实案例

# 摘要
本文对机器学习模型的基础理论与技术进行了综合概述,并详细探讨了数据准备、预处理技巧、模型构建与优化方法,以及预测分析案例研究。文章首先回顾了机器学习的基本概念和技术要点,然后重点介绍了数据清洗、特征工程、数据集划分以及交叉验证等关键环节。接
PM813S内存管理优化技巧:提升系统性能的关键步骤,专家分享!
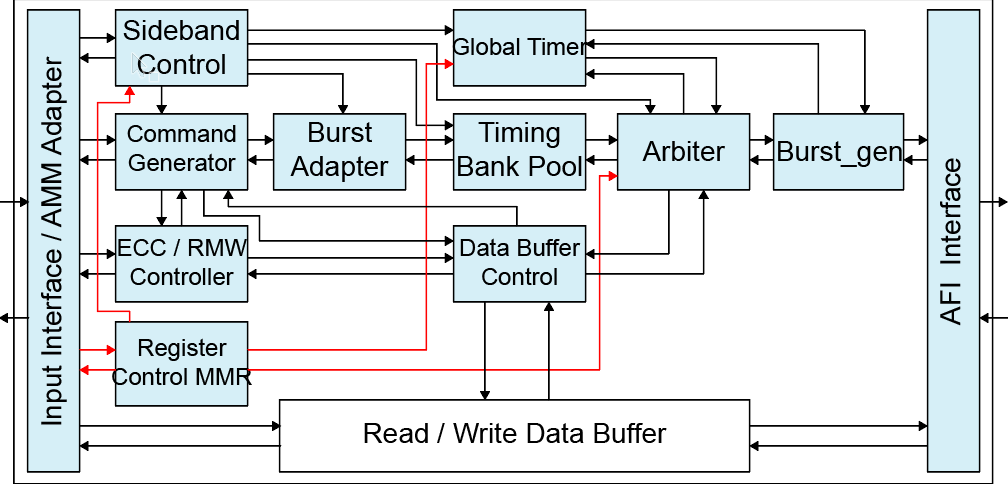
# 摘要
PM813S作为一款具有先进内存管理功能的系统,其内存管理机制对于系统性能和稳定性至关重要。本文首先概述了PM813S内存管理的基础架构,然后分析了内存分配与回收机制、内存碎片化问题以及物理与虚拟内存的概念。特别关注了多级页表机制以及内存优化实践技巧,如缓存优化和内存压缩技术的应用。通过性能评估指标和调优实践的探讨,本文还为系统监控和内存性能提
分析准确性提升之道:谢菲尔德工具箱参数优化攻略

# 摘要
本文介绍了谢菲尔德工具箱的基本概念及其在各种应用领域的重要性。文章首先阐述了参数优化的基础理论,包括定义、目标、方法论以及常见算法,并对确定性与随机性方法、单目标与多目标优化进行了讨论。接着,本文详细说明了谢菲尔德工具箱的安装与配置过程,包括环境选择、参数配置、优化流程设置以及调试与问题排查。此外,通过实战演练章节,文章分析了案例应用,并对参数调优的实验过程与结果评估给出了具体指
潮流分析的艺术:PSD-BPA软件高级功能深度介绍

# 摘要
电力系统分析在保证电网安全稳定运行中起着至关重要的作用。本文首先介绍了潮流分析的基础知识以及PSD-BPA软件的概况。接着详细阐述了PSD-BPA的潮流计算功能,包括电力系统的基本模型、潮流计算的数学原理以及如何设置潮流计算参数。本文还深入探讨了PSD-BPA的高级功
CC-LINK远程IO模块AJ65SBTB1现场应用指南:常见问题快速解决
# 摘要
CC-LINK远程IO模块作为一种工业通信技术,为自动化和控制系统提供了高效的数据交换和设备管理能力。本文首先概述了CC-LINK远程IO模块的基础知识,接着详细介绍了其安装与配置流程,包括硬件的物理连接和系统集成要求,以及软件的参数设置与优化。为应对潜在的故障问题,本文还提供了故障诊断与排除的方法,并探讨了故障解决的实践案例。在高级应用方面,文中讲述了如何进行编程与控制,以及如何实现系统扩展与集成。最后,本文强调了CC-LINK远程IO模块的维护与管理的重要性,并对未来技术发展趋势进行了展望。
# 关键字
CC-LINK远程IO模块;系统集成;故障诊断;性能优化;编程与控制;维护
【Ubuntu 16.04系统更新与维护】:保持系统最新状态的策略
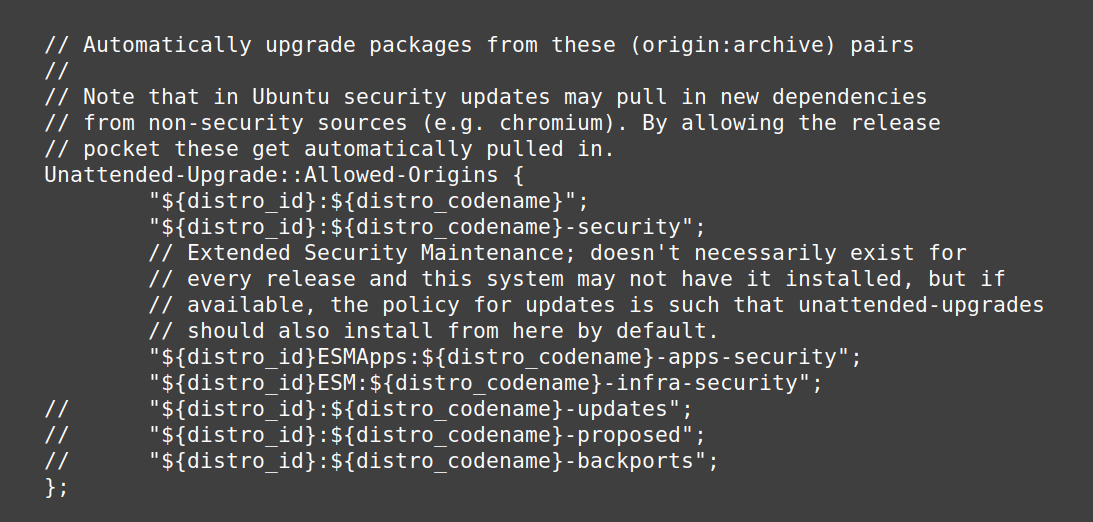
# 摘要
本文针对Ubuntu 16.04系统更新与维护进行了全面的概述,探讨了系统更新的基础理论、实践技巧以及在更新过程中可能遇到的常见问题。文章详细介绍了安全加固与维护的策略,包括安全更新与补丁管理、系统加固实践技巧及监控与日志分析。在备份与灾难恢复方面,本文阐述了
SSD1306在智能穿戴设备中的应用:设计与实现终极指南
# 摘要
SSD1306是一款广泛应用于智能穿戴设备的OLED显示屏,具有独特的技术参数和功能优势。本文首先介绍了SSD1306的技术概览及其在智能穿戴设备中的应用,然后深入探讨了其编程与控制技术,包括基本编程、动画与图形显示以及高级交互功能的实现。接着,本文着重分析了SSD1306在智能穿戴应用中的设计原则和能效管理策略,以及实际应用中的案例分析。最后,文章对SSD1306未来的发展方向进行了展望,包括新型显示技术的对比、市场分析以及持续开发的可能性。
# 关键字
SSD1306;OLED显示;智能穿戴;编程与控制;用户界面设计;能效管理;市场分析
参考资源链接:[SSD1306 OLE
RTC4版本迭代秘籍:平滑升级与维护的最佳实践

# 摘要
本文重点讨论了RTC4版本迭代的平滑升级过程,包括理论基础、实践中的迭代与维护,以及维护与技术支持。文章首先概述了RTC4的版本迭代概览,然后详细分析了平滑升级的理论基础,包括架构与组件分析、升级策略与计划制定、技术要点。在实践章节中,本文探讨了版本控制与代码审查、单元测试
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )