【Application Extension】: The Potential of GAN in Speech Synthesis: Welcoming a New Era of Voice AI
发布时间: 2024-09-15 16:43:06 阅读量: 25 订阅数: 32 
# 1. Overview of GAN Technology and Its Application in Speech Synthesis
Since its introduction in 2014, Generative Adversarial Networks (GANs) have become a hot topic in the field of deep learning. GANs consist of a generator and a discriminator, which oppose and learn from each other. This unique training approach has shown significant potential in dealing with high-dimensional data, especially achieving breakthrough results in areas such as image generation and artistic creation.
In recent years, the application of GAN technology in speech synthesis has gradually gained attention. Speech synthesis refers to the process of converting textual information into speech information, and GANs, through their unique generative adversarial mechanism, can effectively improve the naturalness and clarity of synthetic speech, addressing issues such as poor sound quality and insufficient emotional expression in traditional speech synthesis.
In this chapter, we will briefly introduce the basic concepts of GAN technology and explore its application in the field of speech synthesis. Additionally, we will learn how GANs improve the quality of speech synthesis through their unique learning mechanism and look forward to future development trends. By the end of this chapter, readers will have a comprehensive understanding of GAN technology and comprehend its practical application value in speech synthesis.
# 2. GAN Fundamental Theory and Architecture Analysis
### 2.1 Basic Principles of Generative Adversarial Networks (GANs)
#### 2.1.1 Core Components and Working Mechanism of GANs
Generative Adversarial Networks (GANs) consist of two parts: the generator and the discriminator. The generator's task is to create fake data that is as close to real data as possible. The discriminator, on the other hand, tries to distinguish between real data and the fake data generated by the generator. These two models compete with each other during training; the generator continuously learns to improve the quality of the data it generates, while the discriminator continuously improves its ability to distinguish between real and fake.
Technically, GAN training can be described in the following steps:
1. **Initialization**: Randomly initialize the parameters of the generator and discriminator.
2. **Generator Generating Data**: The generator receives a random noise vector and converts it into fake data.
3. **Discriminator Judging Data**: The discriminator receives a batch of data (including real and fake data generated by the generator) and outputs the probability that each piece of data is real.
4. **Loss Calculation and Parameter Update**:
- The generator's goal is to make the discriminator's output as close to 1 as possible (considering the generated data as real), so its loss function is typically the negative log-likelihood of the discriminator's output.
- The discriminator's goal is to correctly distinguish between real and fake data, so its loss function is the negative sum of the log-likelihood of real data and the log-likelihood of fake data.
5. **Iterative Training**: Repeat steps 2-4 until convergence.
#### 2.1.2 Challenges and Solutions During GAN Training
GAN training is very complex and prone to various issues, such as mode collapse, unstable training, and convergence to local optima. To address these challenges, researchers have proposed various strategies:
- **Wasserstein Loss**: Use the Wasserstein distance to measure the difference between two distributions, thus guiding the generator to produce more realistic data.
- **Label Smoothing**: Reduce the extreme values of real labels (usually 1) to lower the discriminator's overconfidence.
- **Gradient Penalty**: Introduce gradient penalty based on WGAN to ensure that the gradients of the generator and discriminator are neither too large nor too small during training.
- **Two-Phase Training**: Train the discriminator first to achieve a certain level of performance, then train the generator and discriminator simultaneously.
### 2.2 Different GAN Architectures and Variants
#### 2.2.1 Comparison of Common GAN Architectures
Different GAN architectures vary in terms of generation quality, training difficulty, and application scenarios. Here are some common GAN architectures and their characteristics:
- **DCGAN (Deep Convolutional GAN)**: Combines deep convolutional neural networks with GAN ideas, significantly improving the quality of generated images and making the process more stable.
- **StyleGAN**: Introduces the concept of style transfer by incorporating style codes into the generator, allowing it to control the style and texture of generated images.
- **CycleGAN**: Can achieve data transformation between two different domains, such as transforming horse images into zebra images. Its characteristic is that it does not require paired training data.
#### 2.2.2 Introduction and Application Scenarios of Special GAN Types
In addition to common GAN architectures, there are also some GAN variants designed for specific tasks:
- **Pix2Pix**: A conditional GAN often used for image-to-image translation tasks, such as converting sketch images into color images.
- **StackGAN**: Can generate high-resolution images by stacking multiple generators and discriminators, layer by layer, to enhance the details of the generated images.
- **BigGAN**: Generates high-quality images from large datasets by increasing the scale and number of parameters of the model.
### 2.3 Detailed Theoretical Analysis and Parameter Interpretation of GANs
#### 2.3.1 Parameter Interpretation and Theoretical Logic
In GANs, both the generator and discriminator are deep neural networks. Taking a simple fully connected network as an example, we can define the parameters as follows:
- `Wg`: Weight matrix of the generator
- `Wd`: Weight matrix of the discriminator
- `b_g`: Bias term of the generator
- `b_d`: Bias term of the discriminator
- `z`: Input noise vector of the generator
- `x`: Real data input
- `G(z)`: Function of the generator converting noise vector `z` into generated data
- `D(x)`: Function of the discriminator determining whether the input data `x` is real
During training, we aim to minimize the loss functions of the discriminator and generator:
- **Discriminator's loss function**:
$$ L_D = E_x[\log D(x)] + E_z[\log(1-D(G(z)))] $$
- **Generator's loss function**:
$$ L_G = E_z[\log(1-D(G(z)))] $$
Gradients for parameter updates are typically calculated using backpropagation. The parameters of the discriminator and generator are updated through gradient descent.
```python
# Pseudocode for the generator model
def generator(z):
# z is a random noise vector
return G(z) # Convert the noise vector into generated data
# Pseudocode for the discriminator model
def discriminator(x):
# x is the input data, which can be real or generated data
return D(x) # The output is the probability that the data is real
# Pseudocode for loss function calculation and parameter update
def train_step(x, z):
# Train the discriminator with real and generated data
D_real = discriminator(x)
G_fake = generator(z)
D_fake = discriminator(G_fake)
loss_d = ... # Calculate the discriminator's loss function
loss_g = ... # Calculate the generator's loss function
# Update the discriminator's parameters
d_optimizer.step(loss_d)
# Update the generator's parameters
g_optimizer.step(loss_g)
# Training loop
for epoch in range(num_epochs):
for x, z in data_loader:
train_step(x, z)
```
### 2.4 GAN Architecture Analysis and Model Structural Evolution
#### 2.4.1 Architecture Analysis
GAN architecture has evolved from simple fully connected networks to deep convolutional networks. This transition has greatly improved the quality and diversity of generated images. Convolutional GAN architectures, such as DCGAN, replace the fully connected layers in GANs with convolutional and transposed convolutional layers, allowing the generator to produce images with higher resolution and more complex structures.
Batch normalization is often used in the design of discriminators to accelerate training and improve the quality of generated images. To enhance the stability of the training process, discriminators are frequently designed as deep networks.
```mermaid
graph TD;
Z[z (random noise vector)]
G[Generator <br> G(z)]
D[Discriminator <br> D(x)]
X[Real Data x]
XG[Generated Data G(z)]
Z --> G -->|G(z)| D
X -->|x| D
D -->|D(x)| C1[Discriminator Loss]
D -->|D(G(z))| C2[Generator Loss]
```
#### 2.4.2 Model Structural Evolution
GAN architecture has continuously evolved with in-depth research. For example, StyleGAN introduced AdaIN (Adaptive Instance Normalization) and progressive training strategies, allowing for fine control over the local and global styles of generated images. BigGAN significantly improved the resolution and quality of generated images by increasing model capacity and the scale of parameters.
When choosing an architecture, it is necessary to consider the specific requirements of the target task, such as the resolution of generated images, stylistic consistency, and diversity. For specific tasks, it may be necessary to improve existing GAN architectures or develop new ones to meet the requirements.
In GAN research and applications, theoretical analysis, parameter interpretation, and model structural evolution are inseparable. A deep understanding of these contents can help researchers and practitioners design, train, and apply generative adversarial networks more effectively.
# 3. GAN Application Practice in Speech Synthesis
## 3.1 Theoretical Application of GAN in Speech Synthesis
### 3.1.1 Role of GAN in Improving Speech Quality
A significant application of Generative Adversarial Networks (GANs) in speech synthesis is to enhance the naturalness and quality of synthetic speech. Traditional speech synthesis systems, such as parametric synthesis or Concatenative TTS (Text-to-Speech), often face drawbacks like unnatural sound and lack of realism. GANs, through adversarial learning, can generate more realistic speech waveforms.
To make GANs work in speech synthesis, researchers usually design GANs as a sequence generation model, where the generator (Generator) is responsible for generating spe

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【EmuELEC全面入门与精通】:打造个人模拟器环境(7大步骤)

# 摘要
EmuELEC是一款专为游戏模拟器打造的嵌入式Linux娱乐系统,旨在提供一种简便、快速的途径来设置和运行经典游戏机模拟器。本文首先介绍了EmuELEC的基本概念、硬件准备、固件获取和初步设置。接着,深入探讨了如何定制EmuELEC系统界面,安装和配置模拟器核心,以及扩展其功能。文章还详细阐述了游戏和媒体内容的管理方法,包括游戏的导入、媒体内容的集成和网络功能的
【TCAD仿真流程全攻略】:掌握Silvaco,构建首个高效模型
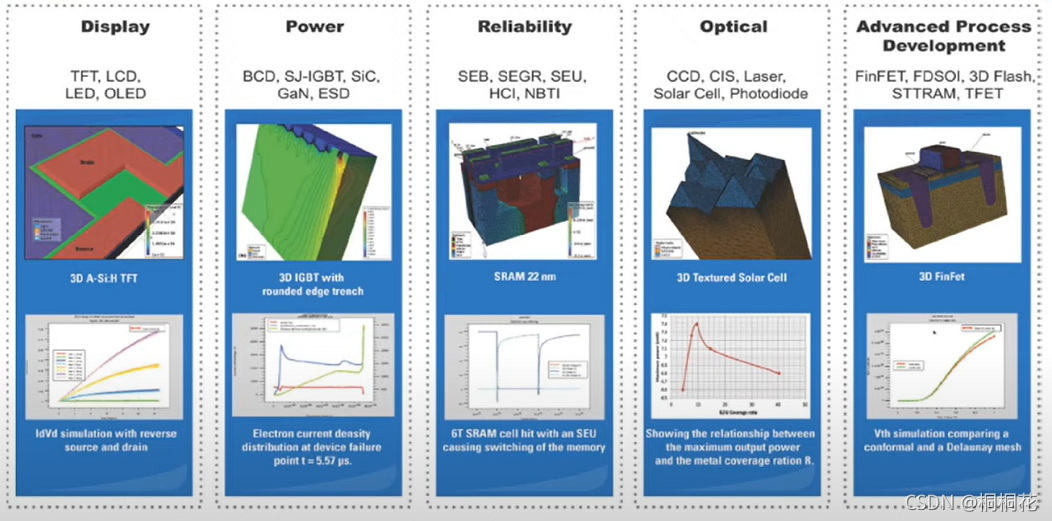
# 摘要
本文首先介绍了TCAD仿真和Silvaco软件的基础知识,然后详细讲述了如何搭建和配置Silvaco仿真环境,包括软件安装、环境变量设置、工作界面和仿真
【数据分析必备技巧】:0基础学会因子分析,掌握数据背后的秘密
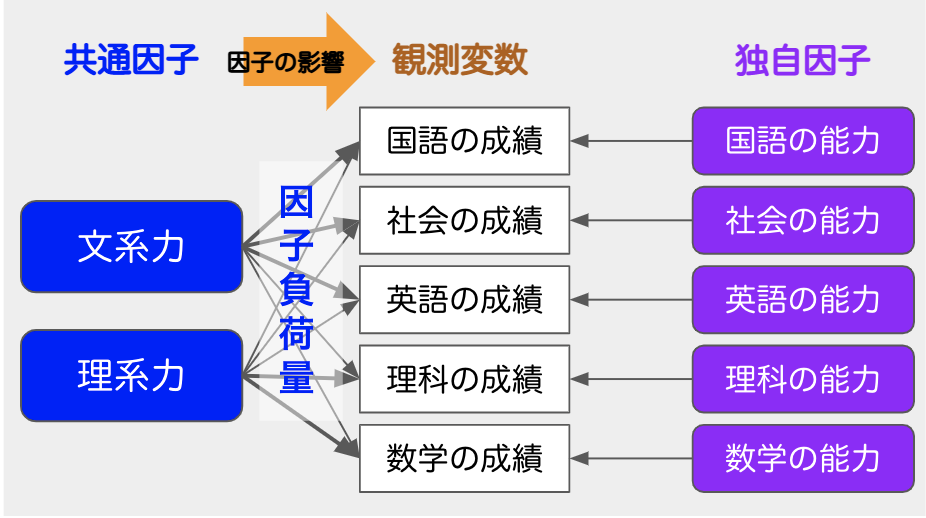
# 摘要
因子分析是一种强有力的统计方法,被广泛用于理解和简化数据结构。本文首先概述了因子分析的基本概念和统计学基础,包括描述性统计、因子分析理论模型及适用场景。随后,文章详细介绍了因子分析的实际操作步骤,如数据的准备、预处理和应用软件操作流程,以及结果的解读与报告撰写。通过市场调研、社会科学统计和金融数据分析的案例实战,本文展现了因子分析在不同领域的应用价值。最后,文章探讨了因子分析
【树莓派声音分析宝典】:从零开始用MEMS麦克风进行音频信号处理

# 摘要
本文详细介绍了基于树莓派的MEMS麦克风音频信号获取、分析及处理技术。首先概述了MEMS麦克风的基础知识和树莓派的音频接口配置,进而深入探讨了模拟信号数字化处理的原理和方法。随后,文章通过理论与实践相结合的方式,分析了声音信号的属性、常用处理算法以及实际应用案例。第四章着重于音频信号处理项目的构建和声音事件的检测响应,最后探讨了树莓派音频项目的拓展方向、
西门子G120C变频器维护速成

# 摘要
西门子G120C变频器作为工业自动化领域的一款重要设备,其基础理论、操作原理、硬件结构和软件功能对于维护人员和使用者来说至关重要。本文首先介绍了西门子G120C变频器的基本情况和理论知识,随后阐述了其硬件组成和软件功能,紧接着深入探讨了日常维护实践和常见故障的诊断处理方法。此外
【NASA电池数据集深度解析】:航天电池数据分析的终极指南
# 摘要
本论文提供了航天电池技术的全面分析,从基础理论到实际应用案例,以及未来发展趋势。首先,本文概述了航天电池技术的发展背景,并介绍了NASA电池数据集的理论基础,包括电池的关键性能指标和数据集结构。随后,文章着重分析了基于数据集的航天电池性能评估方法,包括统计学方法和机器学习技术的应用,以及深度学习在预测电池性能中的作用。此外,本文还探讨了数据可视化在分析航天电池数据集中的重要性和应用,包括工具的选择和高级可视化技巧。案例研究部分深入分析了NASA数据集中的故障模式识别及其在预防性维护中的应用。最后,本文预测了航天电池数据分析的未来趋势,强调了新兴技术的应用、数据科学与电池技术的交叉融合
HMC7044编程接口全解析:上位机软件开发与实例分析
# 摘要
本文全面介绍并分析了HMC7044编程接口的技术规格、初始化过程以及控制命令集。基于此,深入探讨了在工业控制系统、测试仪器以及智能传感器网络中的HMC7044接口的实际应用案例,包括系统架构、通信流程以及性能评估。此外,文章还讨论了HMC7044接口高级主题,如错误诊断、性能优化和安全机制,并对其在新技术中的应用前景进行了展望。
# 关键字
HMC7044;编程接口;数据传输速率;控制命令集;工业控制;性能优化
参考资源链接:[通过上位机配置HMC7044寄存器及生产文件使用](https://wenku.csdn.net/doc/49zqopuiyb?spm=1055.2635
【COMSOL Multiphysics软件基础入门】:XY曲线拟合中文操作指南
# 摘要
本文全面介绍了COMSOL Multiphysics软件在XY曲线拟合中的应用,旨在帮助用户通过高级拟合功能进行高效准确的数据分析。文章首先概述了COMSOL软件,随后探讨了XY曲线拟合的基本概念,包括数学基础和在COMSOL中的应用。接着,详细阐述了在COMSOL中进行XY曲线拟合的具体步骤,包括数据准备、拟合过程,
【GAMS编程高手之路】:手册未揭露的编程技巧大公开!
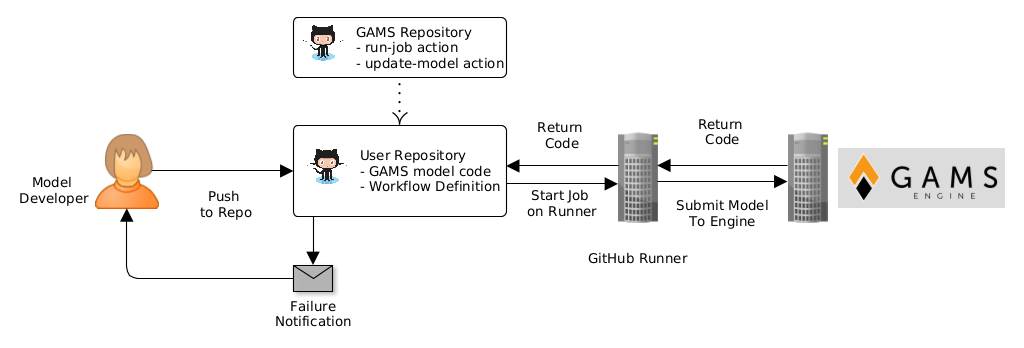
# 摘要
本文全面介绍了一种高级建模和编程语言GAMS(通用代数建模系统)的使用方法,包括基础语法、模型构建、进阶技巧以及实践应用案例。GAMS作为一种强大的工具,在经济学、工程优化和风险管理领域中应用广泛。文章详细阐述了如何利用GAMS进行模型创建、求解以及高级集合和参数处理,并探讨了如何通过高级
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )