探究ChatGPT能力崛起:大规模预训练的秘密
需积分: 5 64 浏览量
更新于2024-06-21
收藏 928KB PDF 举报
本文主要探讨了OpenAI的预训练模型ChatGPT各项能力的起源和演变过程。ChatGPT的强大不仅限于自然语言处理,它在语言生成、上下文学习和世界知识等方面的表现超越了研究人员的预期。初代GPT-3在2020年发布时,展示了三项关键能力:
1. 语言生成:GPT-3能够根据提示词生成连贯的句子,这是人与模型进行交互的基础方式。其生成的内容不仅局限于文本,还能够展现出理解并回应用户意图的能力。
2. 上下文学习(in-context learning):与传统的语言模型不同,GPT-3通过观察和学习大量示例,能够在新的情境中理解和应用知识,解决实际问题。这表明模型在训练过程中不仅仅是在记忆词汇,而是在理解并学习任务模式。
3. 世界知识:ChatGPT不仅具备事实性知识,还能展现一定程度的常识推理,这意味着它能理解和应用跨领域信息,进行复杂的推理。
这些能力的根源在于大规模的预训练。使用包含3000亿单词的庞大数据集,模型在训练过程中不断吸收和理解文本中的信息,从而实现了在没有明确编程的情况下,展现出超出语言模型传统的泛化和适应能力。
然而,文章也指出,尽管ChatGPT表现出惊人的能力,但国际学术界认为其与传统模型(如BERT、BART、T5)之间的差距巨大,类似导弹与弓箭的对比,强调了对这一领域的高度重视。国内的研究机构和业界研究院需要密切关注并迎头赶上,否则可能会面临技术断层的风险。
文章呼吁国内同行提高技术水准,扩大学术视野,以确保不落后于国际前沿。最后引用《百年孤独》中的名言,表达了对当前处境的严肃态度,警示我们必须警觉并积极应对这一技术变革的挑战。
本文深入剖析了ChatGPT的强大能力背后的技术路线,旨在促进大型语言模型的透明度,并倡导国内学术界与业界加强合作,共同推动人工智能技术的发展。
一个足够好的开源的近似模型了(根据 OPT 论文和斯坦福大学的 HELM 评
估)。
虽然初代的 GPT-3 可能表面上看起来很弱,但后来的实验证明,初代 GPT-
3 有着非常强的潜力。这些潜力后来被代码训练、指令微调 (instruction
tuning) 和 基 于 人 类 反 馈 的 强 化 学 习 (reinforcement learning with
human feedback, RLHF) 解锁,最终体展示出极为强大的突现能力。
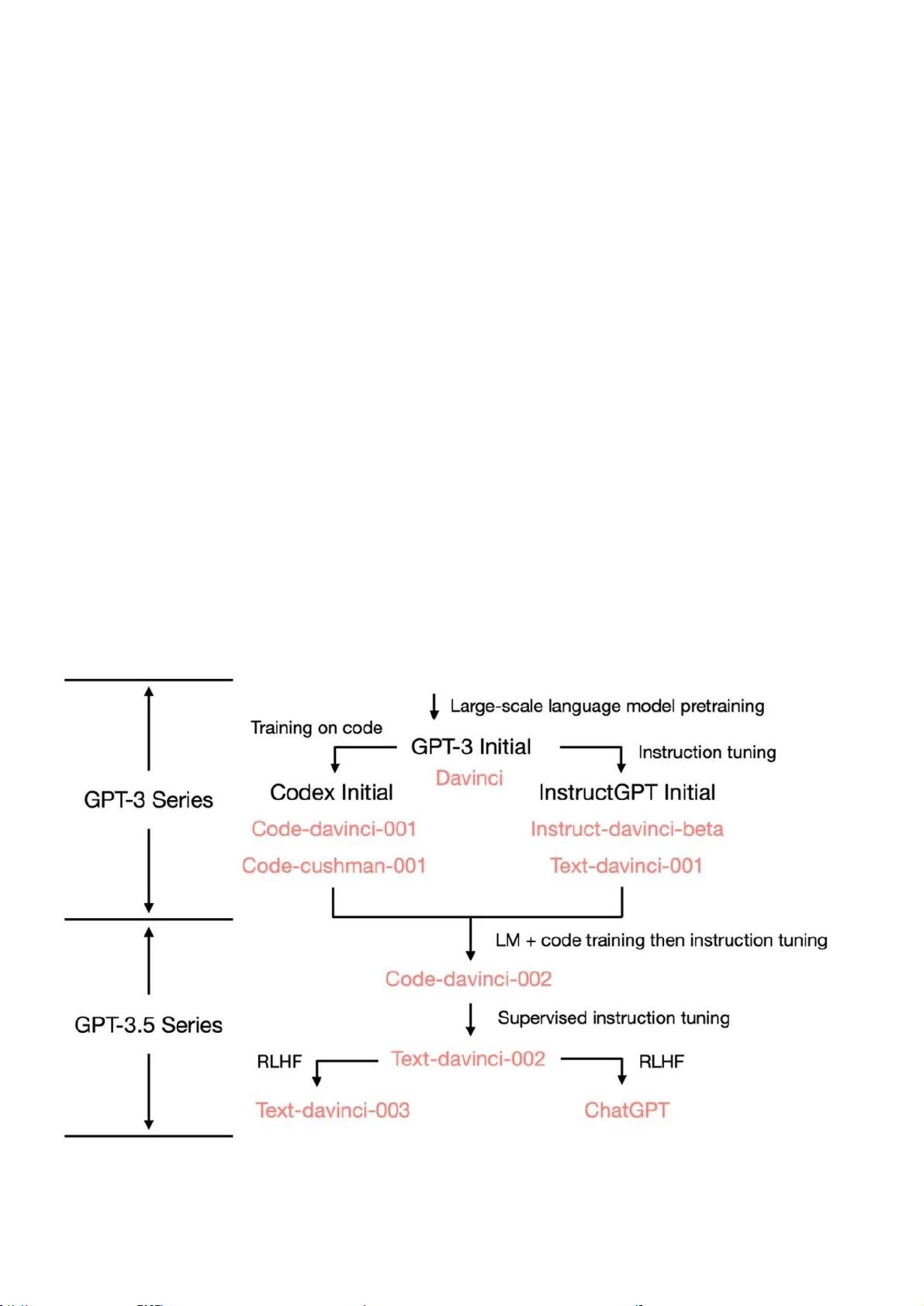
二、从2020版GPT-3到2022版ChatGPT
从最初的 GPT-3 开始,为了展示 OpenAI 是如何发展到ChatGPT的,我们
看一下 GPT-3.5 的进化树:
剩余19页未读,继续阅读
114 浏览量
190 浏览量
点击了解资源详情
144 浏览量
2025-01-05 上传

safesmile
- 粉丝: 1
- 资源: 656
 我的内容管理
展开
我的内容管理
展开







最新资源
- 周立功 RS485通讯 51单片机
- 网络编程 Web编程
- MC9S08AC60单片机数据手册(英文)
- java2d教材 .
- C#完全手册.pdf
- CRC算法原理及C语言实现.pdf
- BGP.Internet.Routing.Architectures.2nd.Edition.2000
- S3C44B0试验配置
- 自地球诞生以来最全的C语言笔试面试题!将近有250页的word文档!
- VC&MFC讲解教材
- 高质量C-C++编程指南
- XMPP核心(PDF)
- struts入门详解(初学者)
- 索尼(SONY)DSR-190P 数码摄像机说明书
- 学习ASP.NET的最优顺序(好的计划等于效率的提高)
- 关于智能手机的学习资料《智能手机》
