深度学习详解:Transformer与GNN的最新进展
下载需积分: 25 | PDF格式 | 5.37MB |
更新于2024-06-29
| 38 浏览量 | 举报
深度学习是现代人工智能的核心组成部分,它是一种模仿人脑神经网络结构和功能的计算模型,用于处理复杂的数据模式和高级任务。在本资源中,作者Simon J. Prince带领读者逐步理解深度学习的基本概念和最新进展,特别关注了Transformer和图神经网络(GNN)这两种前沿技术。
第1章"Introduction"介绍了深度学习的背景和重要性,强调了其在机器学习领域的核心地位,以及与传统统计方法的区别。章节通过实际案例,如线性回归,展示了监督学习的基础,包括模型的构建、损失函数的选择和训练过程,以帮助读者建立对基本概念的理解。
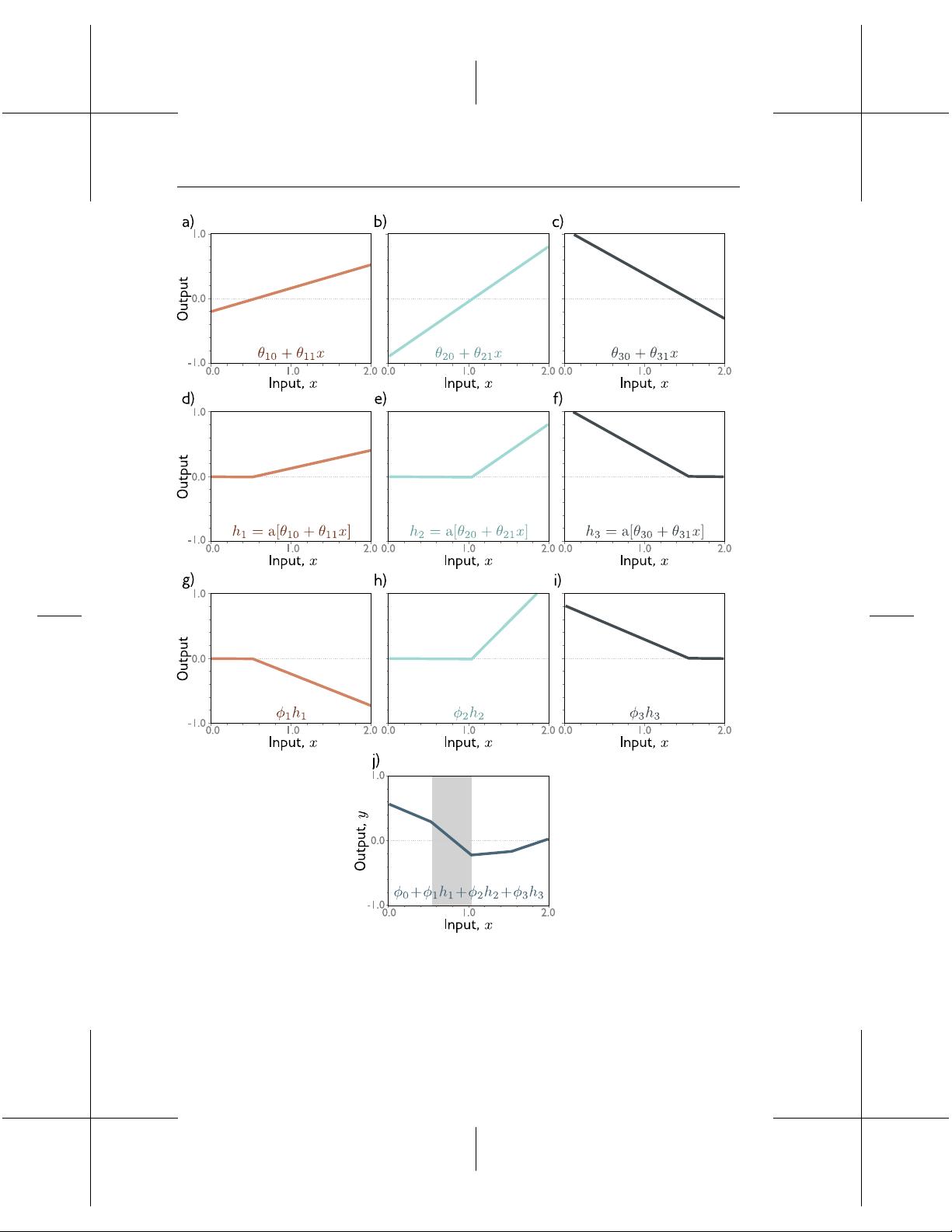
接着,第2章深入探讨了浅层神经网络,这部分内容包括神经网络的工作原理,如神经元之间的连接和权重更新。"Universal approximation theorem"指出神经网络具有强大的表达能力,可以近似任何连续函数,这对于理解深度学习的潜力至关重要。同时,该章节也讨论了多变量输入和输出的情况,通过可视化工具来帮助读者直观感受数据的维度变化。
进入21世纪的最新进展,第3章重点讲解了Transformer模型。Transformer是基于自注意力机制的架构,最初在自然语言处理中的大规模预训练模型如BERT和GPT系列中取得了显著成功。它摒弃了传统的循环或卷积结构,能够并行处理序列数据,极大地提高了模型的效率和性能。这一部分会深入解析Transformer的工作原理,并与传统神经网络进行对比。
此外,图神经网络(GNN)在第4章被详细阐述,这是针对网络数据(如社交网络、分子结构等)设计的一种特殊类型的深度学习模型。GNN通过聚合邻居节点的信息,学习图结构中的局部特征表示,这在推荐系统、社区检测和药物发现等领域有广泛应用。
整个资源旨在提供一个全面且易于理解的深度学习入门指南,涵盖了基础知识、实践技巧和前沿技术,帮助读者在不断发展的AI领域中跟上步伐。同时,作者鼓励读者积极参与反馈,共同提升文档质量。无论是对初学者还是专业人士,这份资源都是一份宝贵的参考资料。

14 2 Supervised learning
terms on the right-hand side of equation 2.5) and the cost function is the overall quantity
that is minimized (
i.e.
, the entire right-hand side of equation 2.5). A cost function
can contain additional terms that are not associated with individual data points. More
generally, an objective function is any function that is to be maximized or minimized.
Generative vs. discriminative models: The models y = f[x, ϕ] in this chapter are
discriminative models. These make an output prediction y from real-world measurements
x. Another approach is to build a generative model x = g[y, ϕ], in which the real-world
Problem 2.3
measurements x are computed as a function of the output y.
The generative approach has the disadvantage that it doesn’t directly predict y. To
perform inference, we must invert the generative equation as y = g
−1
[x, ϕ] and this may
be dicult. However, generative models have the advantage that we can build in prior
knowledge about how the data were generated. For example, if we wanted to predict the
3D position and orientation y of a car in an image x, then we could build knowledge
about car shape, 3D geometry, and light transport into the function x = g[y, ϕ].
This seems like a good idea, but in fact, discriminative models dominate modern machine
learning; any advantage gained from exploiting prior knowledge in generative models is
usually trumped by brute force learning of very exible discriminative models from large
amounts of training data.
Problems
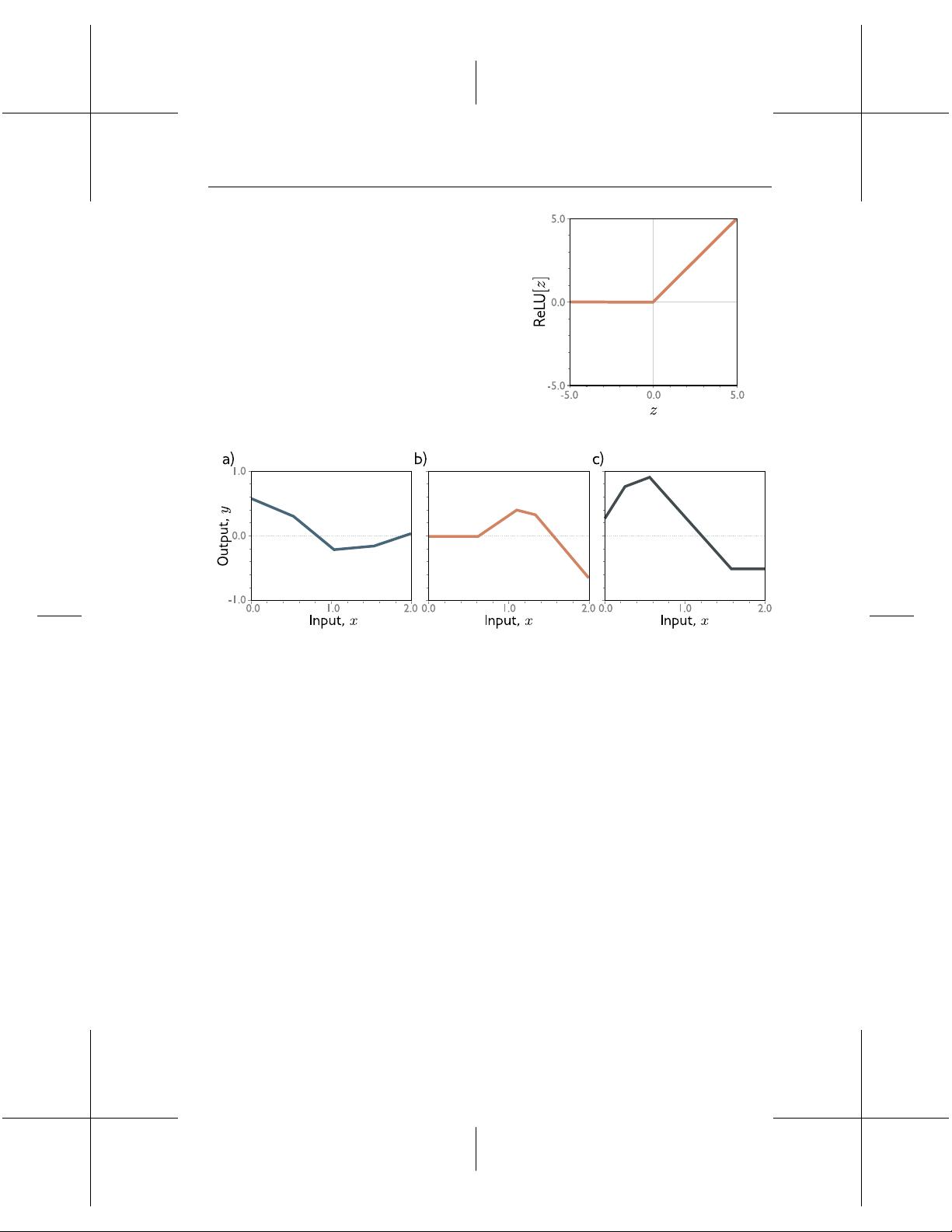
Problem 2.1 To walk ‘downhill’ on the loss function (equation 2.5), we measure its slope
with respect to the parameters ϕ
0
and ϕ
1
. Calculate expressions for the slopes ∂L/∂ϕ
0
and ∂L/∂ϕ
1
.
Problem 2.2 Show that we can nd the minimum of the loss function in closed form by
setting the expression for the derivatives from problem 2.1 to zero and solving for ϕ
0
and
ϕ
1
. Note that this works for linear regression but not for more complex models; this is
why we use iterative model tting methods like gradient descent (gure 2.4).
Problem 2.3 Consider reformulating linear regression as a generative model so we have
x = g[y, ϕ] = ϕ
0
+ ϕ
1
y. What is the new loss function? Find an expression for the inverse
function y = g
−1
[x, ϕ] that we would use to perform inference. Will this model make the
same predictions as the discriminative version for a given training dataset {x
i
, y
i
}?
This work is subject to a Creative Commons CC-BY-NC-ND license. (C) MIT Press.


剩余202页未读,继续阅读
相关推荐
1190 浏览量
2024-02-05 上传
319 浏览量
2025-02-05 上传
155 浏览量
2024-10-22 上传
168 浏览量
点击了解资源详情
214 浏览量

KerryMo
- 粉丝: 211
 我的内容管理
展开
我的内容管理
展开








最新资源
- 掌握Perl编程:第四版教程及习题解答
- MLDN J2EE框架深度学习笔记
- Shark 1.1-2安装程序压缩包分卷下载指南
- markingcode:快速查询datasheet的实用软件
- WPF窗体拖动实现教程:学习基础操作
- zzcms企业网站管理系统v1.0 beta版功能解析
- 基于MQTT和HTTP的记忆游戏网络协议项目
- POJ1006题解:运用中国剩余定理解Biorhythms
- 基于OpenCV和OpenGL的视差图三维重建技术
- 构建天气预报应用:JavaScript & API初体验
- 在线矢量绘图与监控系统Web应用解决方案
- 115外链终结者v1.7:115网数据截取工具
- POJ3292题解报告:半素数H数探索与算法实现
- CPU-Z: 深入了解硬件信息的利器
- Java简易计算器小程序开发教程
- 铜包钢复合线电缆邻近效应分析报告
