深度学习入门:从单层感知器到深度网络解析
5 浏览量
更新于2024-07-15
收藏 776KB PDF 举报
"从单层感知器到深度学习的演变及深度学习框架介绍"
单层神经网络,也称为感知器,是神经网络的最基本形式。它由输入层和输出层构成,其中输入单元仅负责传递数据,不进行任何计算,而输出层的神经元会对输入数据进行处理以产生预测结果。在感知器中,计算层指的是参与计算的神经元层,而单层神经网络只有一个这样的计算层。虽然传统上感知器被描述为两层网络(包括输入层和输出层),但在此文中,作者基于计算层数量来定义网络,因此感知器被视为单层网络。
当预测目标是多维向量时,可以增加输出层的神经元数量来适应需求。例如,如果目标是向量[2, 3],我们可以添加第二个输出单元。每个输出单元的计算公式类似于原始的单个输出神经元,只是多了相应的权重。通过使用二维下标来表示权重,可以更清晰地组织和理解这些权重之间的关系,这在矩阵运算中尤其有用。
矩阵乘法的概念在这里起到了关键作用。输入数据表示为一个列向量,权重表示为一个矩阵,输出则为另一个向量。计算过程可以简化为矩阵乘法的形式,即 g(W * a) = z,其中 g 是激活函数,W 是权重矩阵,a 是输入向量,z 是输出向量。这种表示方式使得神经网络的计算变得高效且直观。
随着网络复杂性的增加,从单层感知器发展到深度学习,更多的计算层被引入,形成了多层神经网络。深度学习框架,如TensorFlow、PyTorch、Keras等,提供了构建和训练这些复杂网络的工具。这些框架不仅支持自动求导(用于反向传播优化权重),还提供了大量预训练模型和便捷的数据处理功能,极大地推动了深度学习的发展和应用。
在深度学习中,每一层神经网络可以视为对输入数据特征的逐步抽象和学习,每一层提取出更高级别的特征。通过多层非线性变换,深度学习网络能够解决复杂的分类和回归问题,如图像识别、自然语言处理和语音识别等。同时,深度学习框架还允许用户自定义网络架构,以适应特定任务的需求。
从单层感知器到深度学习的演进是通过增加网络的层次和复杂性,以模拟人脑的多层次信息处理方式。现代深度学习框架提供了一个强大而灵活的平台,使得研究人员和工程师能够构建和训练复杂的神经网络模型,解决各种实际问题。
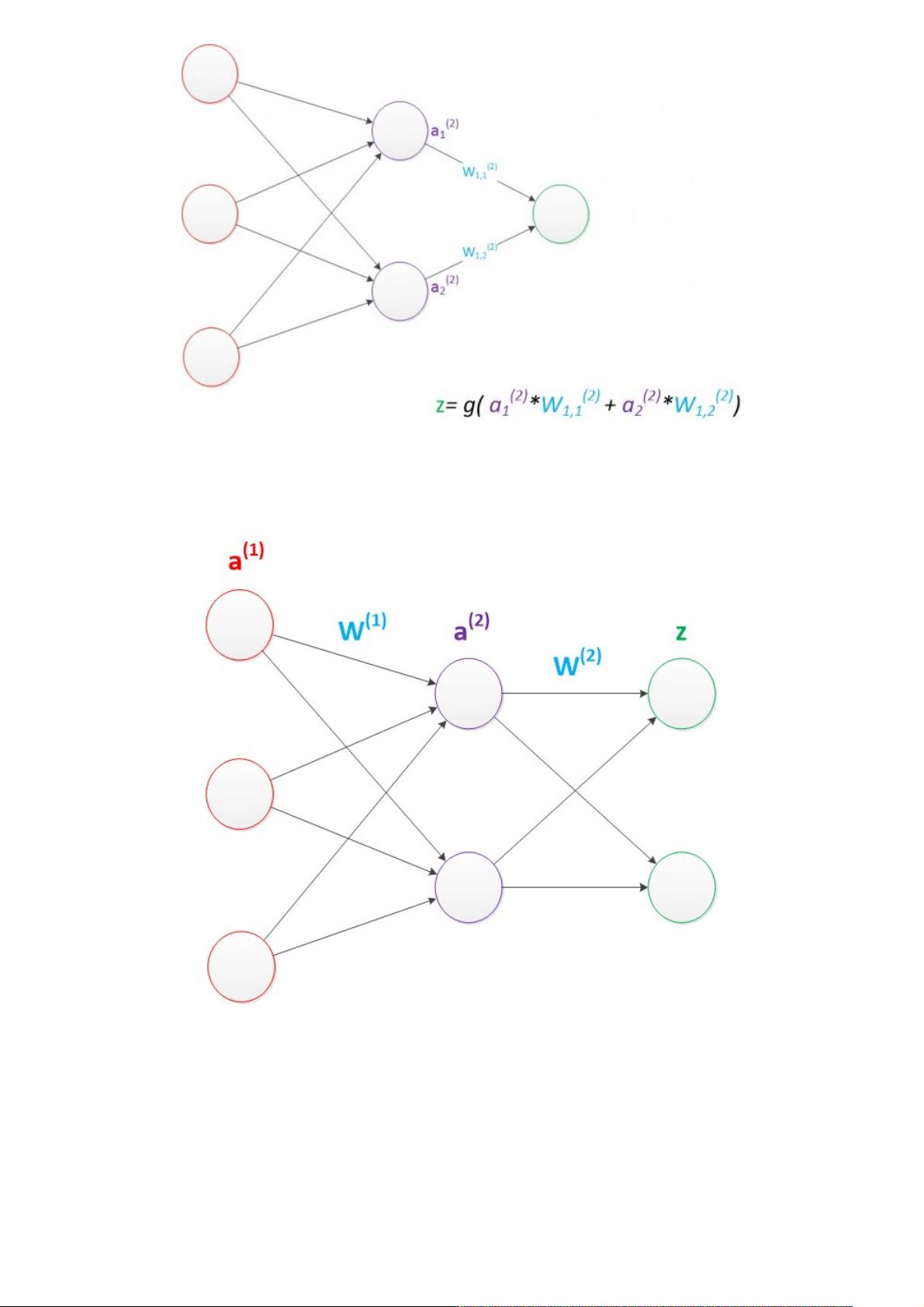
图8 两层神经网络(输出层计算)
假设我们的预测目标是一个向量,那么与前面类似,只需要在“输出层”再增加节点即可。
我们使用向量和矩阵来表示层次中的变量。a(1),a(2),z是网络中传输的向量数据。W(1)和W(2)是网络的矩阵参数。
如下图。
图9 两层神经网络(向量形式)
使用矩阵运算来表达整个计算公式的话如下:
g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = z;
由此可见,使用矩阵运算来表达是很简洁的,而且也不会受到节点数增多的影响(无论有多少节点参与运算,乘法两
端都只有一个变量)。因此神经网络的教程中大量使用矩阵运算来描述。
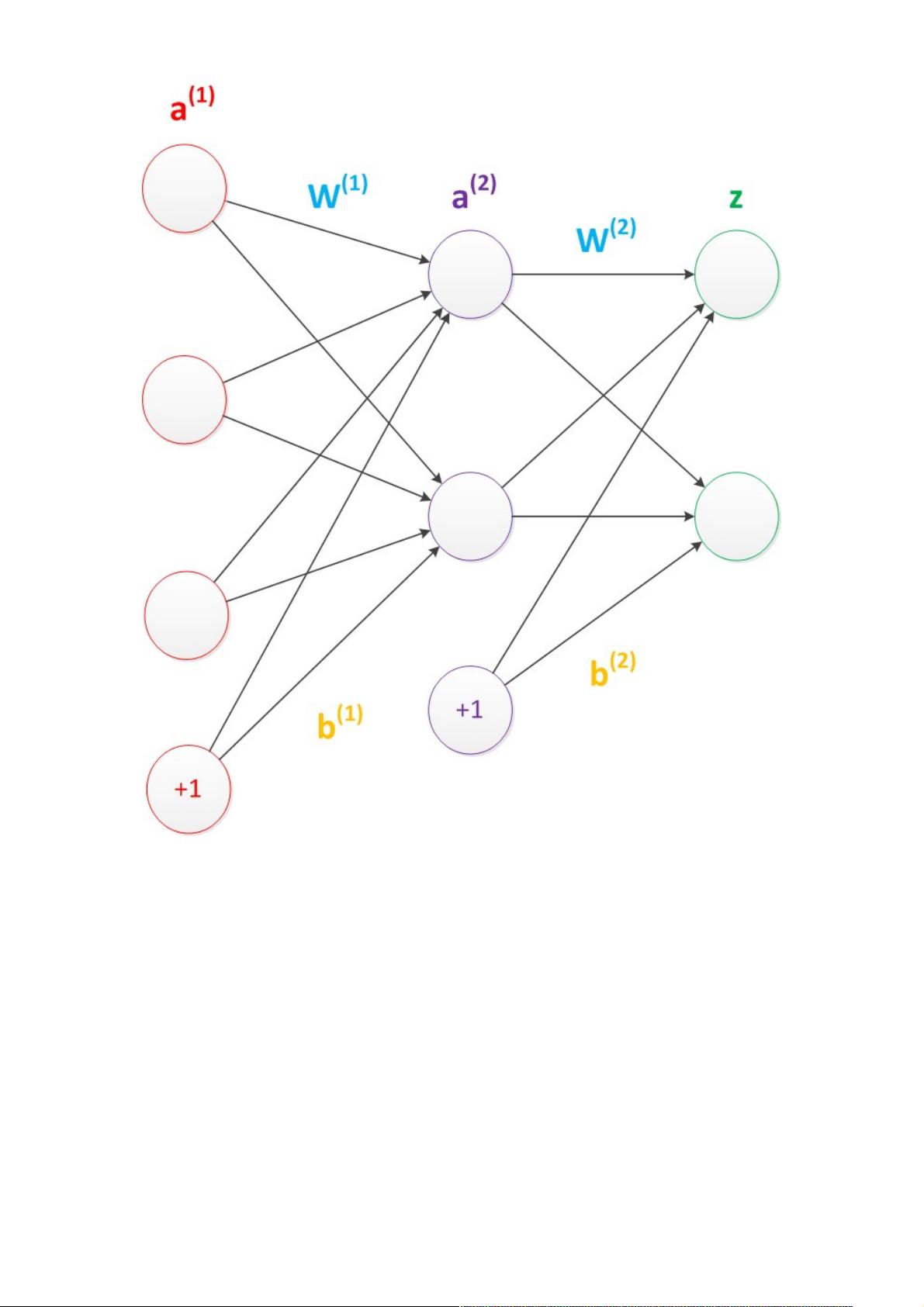
需要说明的是,至今为止,我们对神经网络的结构图的讨论中都没有提到偏置节点(bias unit)。事实上,这些节点是
默认存在的。它本质上是一个只含有存储功能,且存储值永远为1的单元。在神经网络的每个层次中,除了输出层以
外,都会含有这样一个偏置单元。正如线性回归模型与逻辑回归模型中的一样。
剩余25页未读,继续阅读
点击了解资源详情
2021-01-20 上传
2012-06-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情









