Spark Standalone架构详解:RDD与计算抽象关键特性
144 浏览量
更新于2024-08-31
收藏 1.01MB PDF 举报
SparkStandalone架构是Apache Spark的核心组件之一,它提供了一个分布式计算框架的基础结构,支持多种编程语言,如Scala、Java和Python,这极大地提高了开发效率和应用范围。Spark的核心设计之一是RDD(Resilient Distributed Datasets)机制,它是Spark对分布式数据集的内存抽象,通过受限的共享内存模式实现容错性和高效性能。
RDD的五个关键特性:
1. **分区** (Partitions): RDD被划分为一系列的数据分区,每个分区独立且可以在不同的节点上存储,这样既实现了数据分布,又允许并行处理。
2. **分区上的计算函数** (Function per Partition): 每个分区都有一个特定的计算函数,这个函数定义了如何处理该分区内的数据,这是RDD执行计算的基础。
3. **依赖关系** (Dependency Graph): RDD之间的依赖关系表示了任务执行的顺序,当一个RDD依赖于另一个RDD的结果时,前者的计算会在后者的计算完成后启动。
4. **键值对分区器** (Optional Partitioner): 对于键值对RDD,一个Partitioner用于确定数据的分布策略,常见的有HashPartitioner,确保数据均匀分布。
5. **首选位置信息** (Optional Preferred Locations): 提供了数据在存储层面上的首选位置,例如HDFS块的存放位置,有助于优化数据访问速度。
在Spark的计算抽象中,以下几个核心概念起着关键作用:
1. **Application**:用户编写的Spark程序,它由Driver(驱动程序)和Executor(执行器)组成,Driver负责协调任务执行,Executor负责执行实际的计算任务。
2. **Job**:用户在程序中调用Action触发的计算单元,Job通常包含多个Stage,用于划分计算任务的不同阶段。
3. **Stage**:根据任务的性质,Stage可以分为ShuffleMapStage(进行shuffle操作的阶段)和ResultStage(生成最终结果的阶段)。Shuffle操作如groupByKey会导致数据重新分布,形成新的Stage。
4. **TaskSet**:每个Stage对应一个TaskSet,封装了一组具有相同处理逻辑的Task,这些Task可以并行执行,提高了并发处理能力。
5. **Task**:是Spark执行的基本单元,它们在物理节点上运行,包括Shuffle相关的任务以及其他类型的任务。
SparkStandalone架构的设计要点强调了数据的分布和并行处理,通过RDD和Job/Stage的划分,实现了任务的高效执行和容错性。这种设计不仅提升了计算性能,还简化了开发者在分布式环境下的编程复杂性。理解这些设计要点对于深入学习和使用Spark至关重要。
SparkStandalone架构设计要点分析架构设计要点分析
Apache Spark是一个开源的通用集群计算系统,它提供了High-level编程API,支持Scala、Java和Python三种编程语言。
Spark内核使用Scala语言编写,通过基于Scala的函数式编程特性,在不同的计算层面进行抽象,代码设计非常优秀。
RDD抽象
RDD(Resilient Distributed Datasets),弹性分布式数据集,它是对分布式数据集的一种内存抽象,通过受限的共享内存方
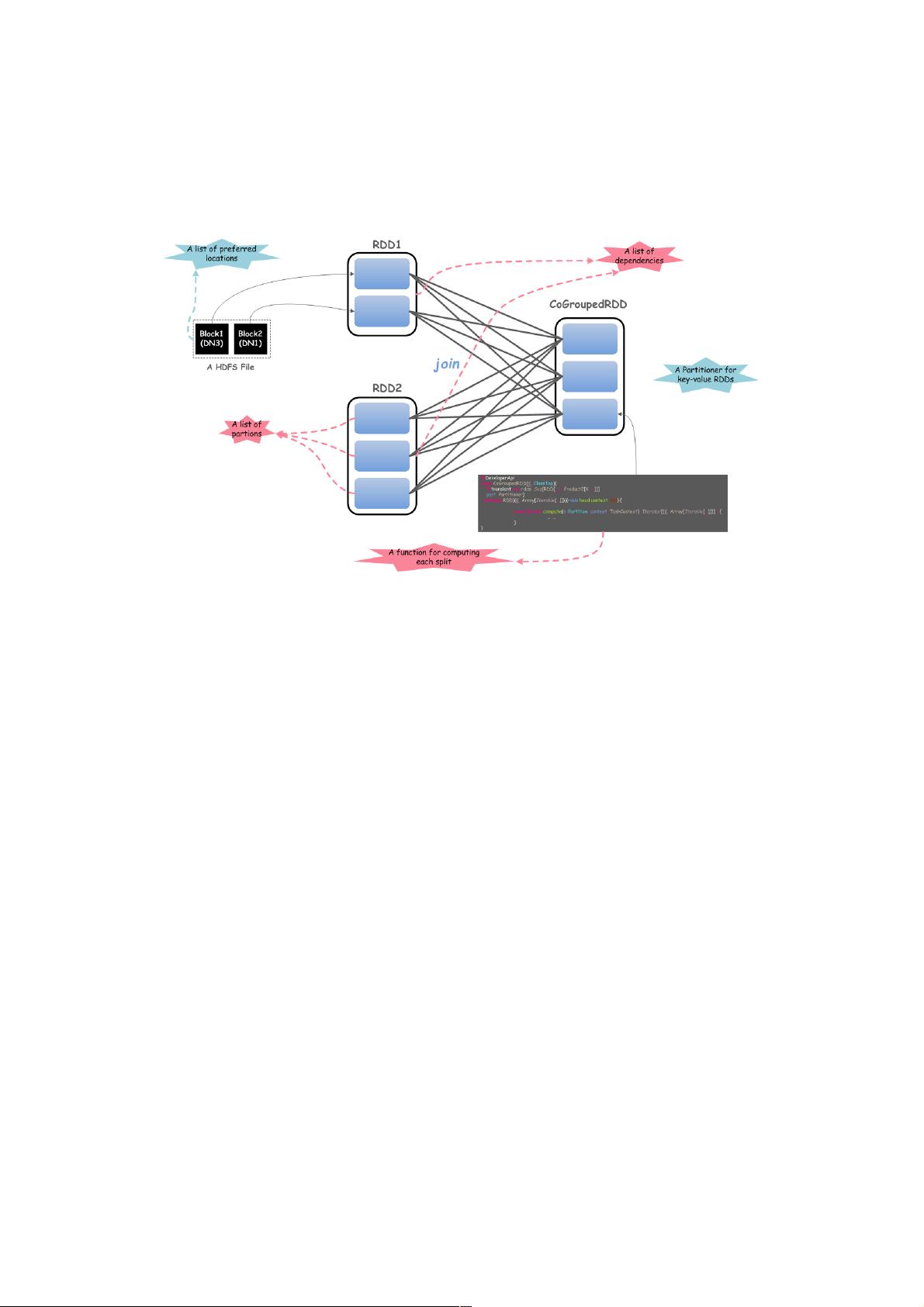
式来提供容错性,同时这种内存模型使得计算比传统的数据流模型要高效。RDD具有5个重要的特性,如下图所示:
上图展示了2个RDD进行JOIN操作,体现了RDD所具备的5个主要特性,如下所示:
1.一组分区
2.计算每一个数据分片的函数
3.RDD上的一组依赖
4.可选,对于键值对RDD,有一个Partitioner(通常是HashPartitioner)
5.可选,一组Preferred location信息(例如,HDFS文件的Block所在location信息)
有了上述特性,能够非常好地通过RDD来表达分布式数据集,并作为构建DAG图的基础:首先抽象一次分布式计算任务的逻
辑表示,最终将任务在实际的物理计算环境中进行处理执行。
计算抽象
在描述Spark中的计算抽象,我们首先需要了解如下几个概念:
1.Application
用户编写的Spark程序,完成一个计算任务的处理。它是由一个Driver程序和一组运行于Spark集群上的Executor组成。
2.Job
用户程序中,每次调用Action时,逻辑上会生成一个Job,一个Job包含了多个Stage。
3.Stage
Stage包括两类:ShuffleMapStage和ResultStage,如果用户程序中调用了需要进行Shuffle计算的Operator,如groupByKey
等,就会以Shuffle为边界分成ShuffleMapStage和ResultStage。
4.TaskSet
基于Stage可以直接映射为TaskSet,一个TaskSet封装了一次需要运算的、具有相同处理逻辑的Task,这些Task可以并行计
算,粗粒度的调度是以TaskSet为单位的。
5.Task
Task是在物理节点上运行的基本单位,Task包含两类:ShuffleMapTask和ResultTask,分别对应于Stage中ShuffleMapStage
下载后可阅读完整内容,剩余6页未读,立即下载
2019-12-24 上传
2024-05-15 上传
点击了解资源详情
2023-03-31 上传
2024-11-04 上传
2024-11-04 上传
2024-11-04 上传
2024-11-04 上传

weixin_38742571
- 粉丝: 13
- 资源: 955
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
