SparkStandalone架构解析:RDD与计算抽象深度探讨
198 浏览量
更新于2024-08-28
收藏 1.01MB PDF 举报
"SparkStandalone架构设计要点分析"
Apache Spark是一个强大的大数据处理框架,以其高效的内存计算和易用性而闻名。Spark的核心设计理念是提供高级编程接口,支持多种编程语言,如Scala、Java和Python,使得开发人员能方便地构建分布式应用。Spark内核基于Scala,利用其函数式编程特性实现灵活的计算抽象。
RDD(Resilient Distributed Datasets)是Spark的核心数据结构,它是一种弹性分布式数据集,能够在多台机器上存储和计算数据。RDD的关键特点在于它的容错性和内存优化的计算模型。通过受限的共享内存,RDD可以在节点故障时恢复数据,同时内存计算模型显著提高了数据处理速度,相比磁盘I/O,内存计算大大减少了延迟。
RDD具备五个核心特性:
1. 分区(Partitions):数据被分割成多个独立的部分,每个部分可以在集群中的不同节点上并行处理。
2. 计算函数(Compute Function):每个分区都有一个对应的计算函数,用于转换或操作数据。
3. 依赖(Dependencies):RDD之间的关系形成了一种有向无环图(DAG),反映了数据的转换历史。
4. 分区器(Partitioner,可选):对于键值对RDD,分区器定义了数据的分布策略,如哈希分区器,用于优化数据分布和并行计算。
5. 预留位置信息(Preferred Location,可选):存储数据块的理想位置信息,有助于减少数据传输,提高效率。
Spark Standalone架构是Spark的一种部署模式,它提供了一个完整的集群管理解决方案,允许在一个集群上独立运行多个Spark应用。在Spark Standalone中,应用由Driver程序和Executor组成。Driver程序负责任务调度和管理,而Executor是运行在工作节点上的进程,执行计算任务。
- Application:用户编写的Spark程序,由Driver程序和Executor组成,处理特定的计算任务。
- Job:每当用户触发一个Action操作(如save、collect等),Spark会创建一个Job,Job由多个Stage串联组成。
- Stage:Stage是计算的逻辑划分,分为ShuffleMapStage(预处理阶段)和ResultStage(结果阶段)。ShuffleMapStage执行需要洗牌操作的任务,如groupByKey,而ResultStage则执行最终结果的计算。
- TaskSet:每个Stage被拆分成TaskSet,每个TaskSet包含一组具有相同计算逻辑的Task,可以并行执行。
- Task:Task是实际在Executor上运行的最小执行单元,执行特定的计算任务,可以是ShuffleMapTask或ResultTask。
Spark的这种计算模型使得它能够高效地处理大规模数据,通过DAG执行计划和Stage的划分,优化数据的传输和计算顺序,从而达到高效执行的目的。同时,RDD的容错机制确保了系统的高可用性。Spark Standalone架构的设计使得它成为一个独立且易于部署的解决方案,适合各种规模的集群环境。
SparkStandalone架构设计要点分析架构设计要点分析
Apache Spark是一个开源的通用集群计算系统,它提供了High-level编程API,支持Scala、Java和Python三种编程语言。
Spark内核使用Scala语言编写,通过基于Scala的函数式编程特性,在不同的计算层面进行抽象,代码设计非常优秀。
RDD抽象
RDD(Resilient Distributed Datasets),弹性分布式数据集,它是对分布式数据集的一种内存抽象,通过受限的共享内存方
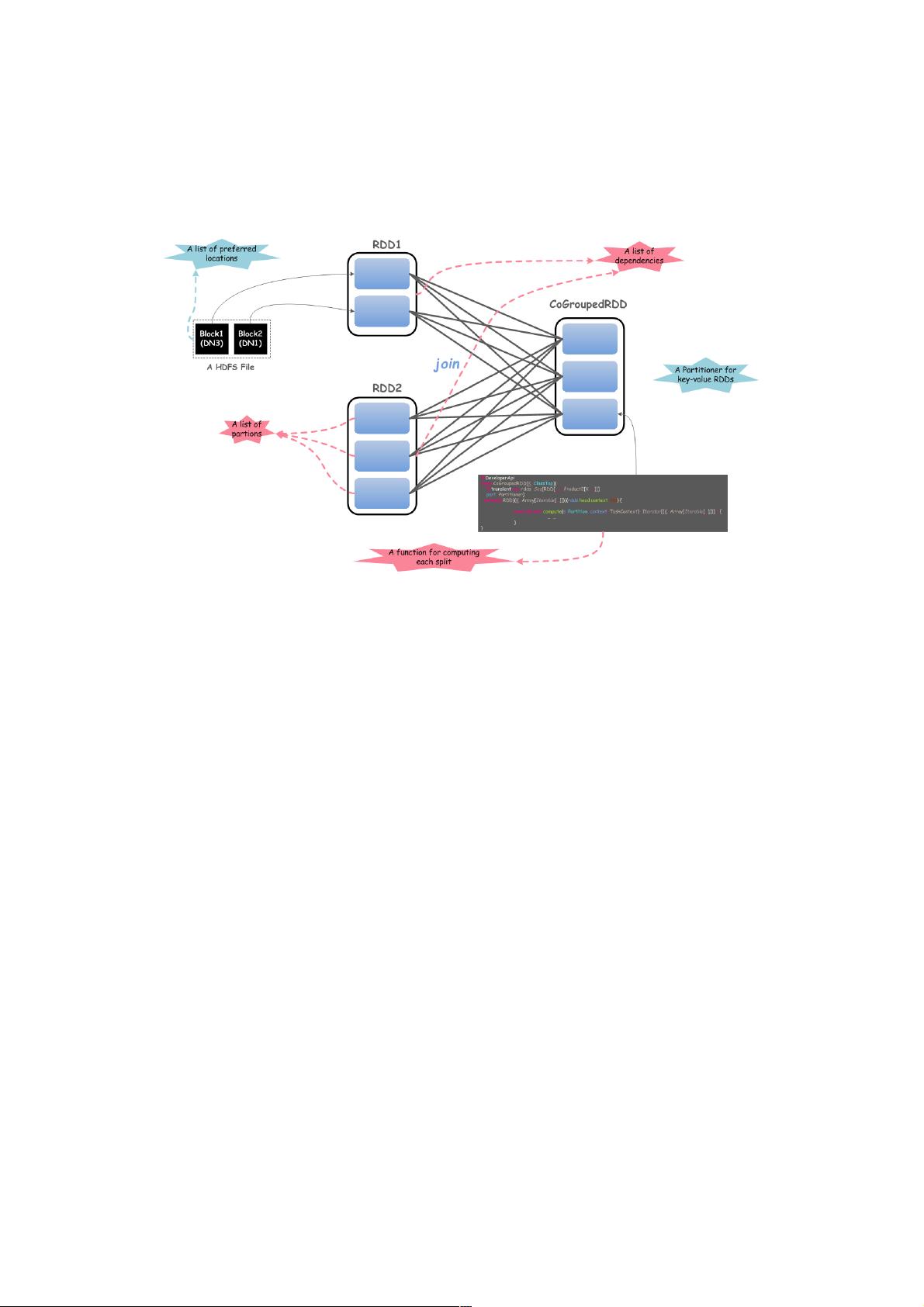
式来提供容错性,同时这种内存模型使得计算比传统的数据流模型要高效。RDD具有5个重要的特性,如下图所示:
上图展示了2个RDD进行JOIN操作,体现了RDD所具备的5个主要特性,如下所示:
1.一组分区
2.计算每一个数据分片的函数
3.RDD上的一组依赖
4.可选,对于键值对RDD,有一个Partitioner(通常是HashPartitioner)
5.可选,一组Preferred location信息(例如,HDFS文件的Block所在location信息)
有了上述特性,能够非常好地通过RDD来表达分布式数据集,并作为构建DAG图的基础:首先抽象一次分布式计算任务的逻
辑表示,最终将任务在实际的物理计算环境中进行处理执行。
计算抽象
在描述Spark中的计算抽象,我们首先需要了解如下几个概念:
1.Application
用户编写的Spark程序,完成一个计算任务的处理。它是由一个Driver程序和一组运行于Spark集群上的Executor组成。
2.Job
用户程序中,每次调用Action时,逻辑上会生成一个Job,一个Job包含了多个Stage。
3.Stage
Stage包括两类:ShuffleMapStage和ResultStage,如果用户程序中调用了需要进行Shuffle计算的Operator,如groupByKey
等,就会以Shuffle为边界分成ShuffleMapStage和ResultStage。
4.TaskSet
基于Stage可以直接映射为TaskSet,一个TaskSet封装了一次需要运算的、具有相同处理逻辑的Task,这些Task可以并行计
算,粗粒度的调度是以TaskSet为单位的。
5.Task
Task是在物理节点上运行的基本单位,Task包含两类:ShuffleMapTask和ResultTask,分别对应于Stage中ShuffleMapStage
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
116 浏览量
429 浏览量
2023-03-31 上传
C2000,28335Matlab Simulink代码生成技术,处理器在环,里面有电力电子常用的GPIO,PWM,ADC,DMA,定时器中断等各种电力电子工程师常用的模块儿,只需要有想法剩下的全部自
1580 浏览量
2025-01-04 上传
2025-01-04 上传

weixin_38642349
- 粉丝: 2
- 资源: 895
 我的内容管理
展开
我的内容管理
展开







