Kudu+Impala:实现实时数据准实时分析的步骤与架构
需积分: 0 151 浏览量
更新于2024-08-05
收藏 2.01MB PDF 举报
本文档主要介绍了如何在CDH5.4.7环境中结合Kudu和Impala实现准实时数据的导入和分析。Kudu是一个专为大数据处理设计的列式存储系统,它支持流式数据导入和高效的数据查询,与Impala的交互式分析功能相得益彰。以下将详细介绍步骤和相关技术细节。
首先,我们来理解Kudu在数据存储中的作用。在Impala中创建Kudu表时,需特别指定`storage_handler`为`com.cloudera.kudu.hive.KuduStorageHandler`,这使得Impala能够与Kudu表进行交互。为了确保数据的一致性和性能,表结构设计时,构成主键(Primary Key)的列(如id)需要放在前面。创建表后,可以访问Kudu管理界面来监控和管理表结构。
数据导入方面,本文介绍的是使用Kafka作为数据源。Kafka是一个分布式流处理平台,适合于处理实时或准实时的数据。首先,通过设置Zookeeper地址创建一个名为`test`的主题,然后使用Kafka自带的示例生产者程序(Producer),实现实时数据的推送。生产者可以交互式地向Kafka主题中发送数据,比如字符串形式的`id`和`name`字段。
当数据从Kafka流入后,Kudu会自动处理这些数据,将其分发到集群的各个节点,并存储在列式格式中,提高查询性能。由于Kudu的特性,即使数据是实时或准实时到达,Impala也能快速地进行分析查询,因为Kudu提供了高效的读取和索引机制。
为了充分利用这一方案,用户还需要熟悉如何在Impala中编写查询语句,以连接到Kudu表并执行分析任务。例如,使用`IMPALA shell`客户端或者SQL语法,可以查询`my_first_table`中的数据,享受其快速响应和实时分析能力。
总结来说,这篇文档涵盖了从Kudu表的设计、创建、Kafka数据源的集成,到实际数据导入和Impala查询的整个过程,对于理解和实施基于Kudu和Impala的准实时数据分析至关重要。通过这种方式,企业可以更有效地处理不断产生的实时数据,提升数据分析的效率和准确性。
!
!
How$to:使用 Kudu+Impala 导入分析准实时数据/
!
Impala 设计的初衷是为 Hadoop 上的海量数据提供交互式的分析功能。对于某些场景而
言,数据并不是一次性全量导进 HDFS 的,而是通过实时、或者准实时的方式导入的,因此需要
一种全新的存储系统,一方面支持数据的流式导入,另一方面支持数据的列式存储(例如 Parquet
存储格式)。Kudu 应运而生,目前 Cloudera 发布了 Beta 版(尚未提供技术支持)。!
!
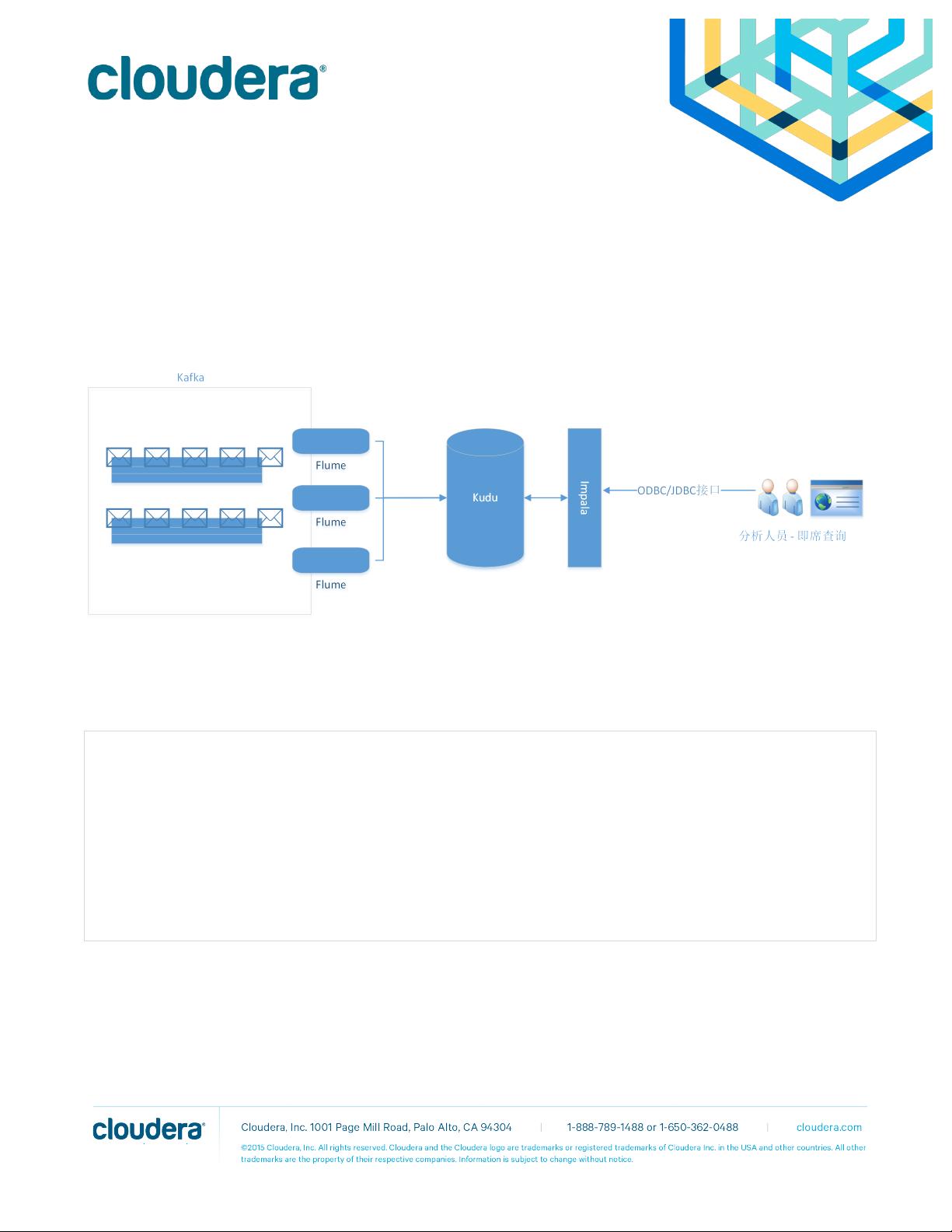
通过该文档,你将学习到如何使用 CDH5.4.7+实现该场景。以下是系统架构图:!
!
!
!
数据存储部分(Kudu)/
通过 Impala 创建 Kudu 表,要求构成 Primary!Key 的列必须排在前面:!
create&TABLE&my_first_table&(!
!!!!id#BIGIN T,!
!!!!name%STRING!
)!
TBLPROPERTIES(!
!!!!'storage_handler'.=.'com.cloudera.kudu.hive.KuduStorageHandler',!
!!!!!"#$#%&'()*+,'-* !. / .!-0+ 1234&+&'()*!5!
!!!!'kudu.ma ster_addresses'-= -'ip ?172?31?28?144:7051',!
!!!!'kudu.key_columns'/= /'id'!
);
!
创建表后,可以通过 Kudu 管理界面进行查看!
下载后可阅读完整内容,剩余3页未读,立即下载
2018-12-26 上传
2022-03-18 上传
2020-11-02 上传
2021-02-24 上传
2019-03-20 上传
2021-05-10 上传
102 浏览量
点击了解资源详情
点击了解资源详情

方2郭
- 粉丝: 32
- 资源: 324
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
