C#实现网络爬虫:基础教程与并发优化
网络爬虫是一种重要的信息技术应用,它在信息检索和处理中扮演着关键角色,用于自动从互联网上抓取和收集数据。本文将介绍如何使用C#语言实现一个基础的网络爬虫,并探讨其工作流程和核心组件。
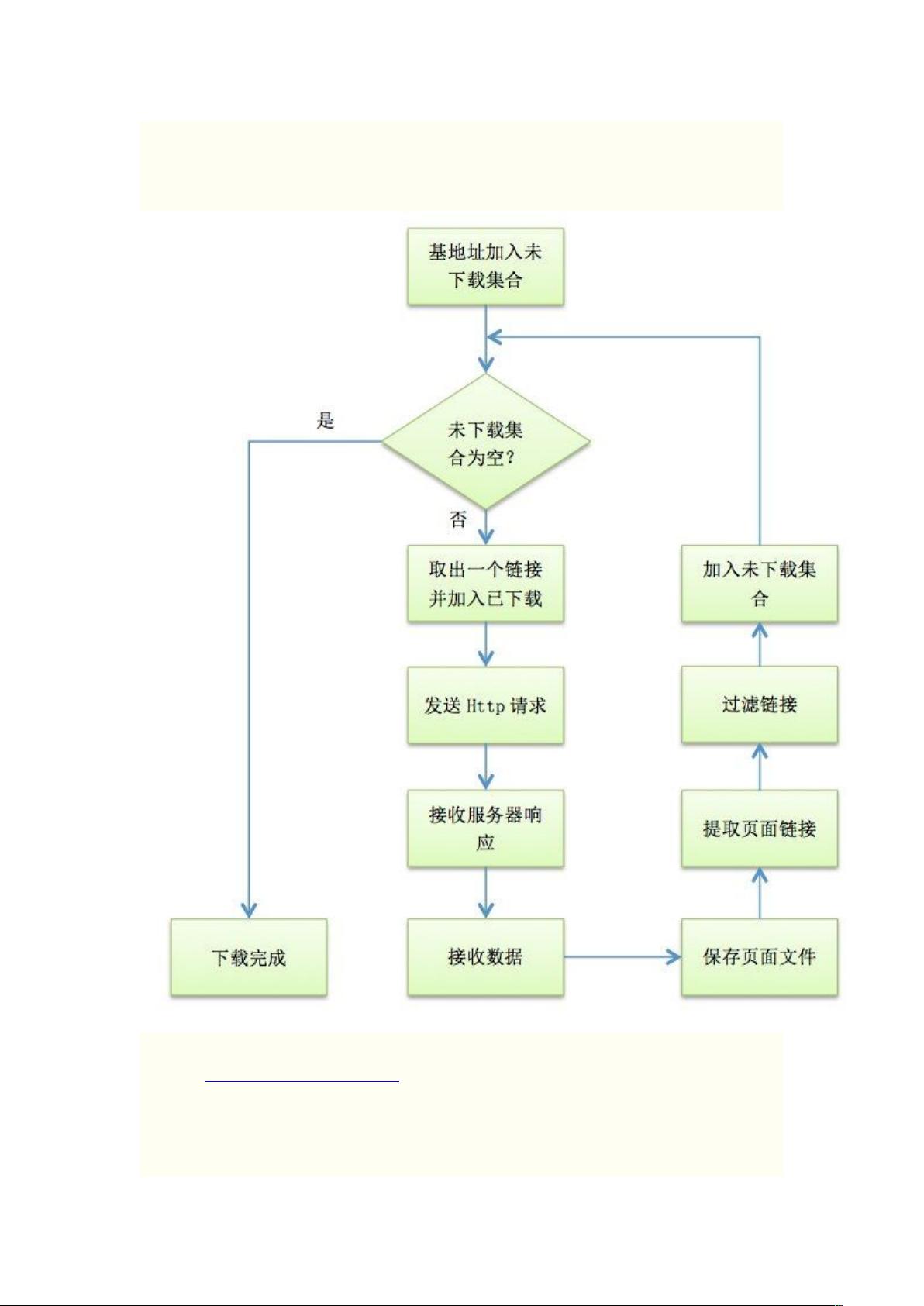
首先,爬虫的工作流程涉及以下几个关键步骤:
1. 待下载集合与已下载集合管理:为了高效地执行爬取任务,需要维护两个集合,一个是待下载URL的队列(通常是队列数据结构),用于存储尚未访问的网址;另一个是已下载URL的集合,用于跟踪已经抓取的内容,防止重复。使用`Dictionary<string, int>`来存储每个URL及其对应的深度,其中字符串是URL,整数表示相对于基URL的层级。
2. HTTP请求与响应处理:C#提供了内置的`HttpWebRequest`和`HttpWebResponse`类,使得创建和管理HTTP请求变得简单。爬虫通过发起HTTP GET请求来获取网页内容,这些请求是异步的,这样可以同时处理多个请求,提高下载效率。代码示例中的`DispatchWork`方法负责调度这些请求,确保在多个工作实例(非线程但模拟并发)之间进行负载均衡。
3. 并发控制:通过创建多个工作实例(`_reqsBusy`数组和`_reqCount`变量),程序可以并发地处理多个下载任务。当一个工作实例完成一个请求后,它会标记自己为忙的状态为`false`,然后调用`DispatchWork`方法,后者会分配新的下载任务给空闲的工作实例。
4. 发送请求:实际的网络请求部分涉及到设置`HttpWebRequest`对象的URL、头信息等参数,然后调用`GetResponse`方法触发请求。具体实现可能会包含错误处理、超时控制以及解析响应内容(如HTML)的过程。
总结来说,C#实现的网络爬虫通过维护URL集合、利用内置HTTP库、并行处理请求和控制并发,有效地实现了从指定URL开始的网页抓取。这个过程展示了编程与网络通信、数据结构和多线程协作的基本原理。理解并掌握这些概念对于编写高效、稳定的网络爬虫至关重要。如果你打算进一步探索网络爬虫,还需要学习如何处理cookies、处理JavaScript渲染的动态内容、遵循网站的robots.txt规则,以及可能面临的反爬虫策略等问题。
下载后可阅读完整内容,剩余7页未读,立即下载
109 浏览量
122 浏览量
点击了解资源详情
301 浏览量
109 浏览量
1063 浏览量
1598 浏览量
108 浏览量
1486 浏览量

CoeusTong
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Windows环境下Oracle RAC集群安装步骤详解
- PSP编程入门:Lua教程详解
- GDI+ SDK详解:罕见的技术文档
- LoadRunner基础教程:企业级压力测试详解
- Crystal Reports 7:增强交叉表功能教程与设计技巧
- 软件开发文档编写指南:从需求分析到经济评估
- Delphi 使用ShellExecute API详解
- Crystal Reports 6.x 的交叉表功能与限制解析
- 掌握Linux:60个核心命令详解
- Oracle PL/SQL 存储过程详解及应用
- Linux 2.6内核基础配置详解与关键选项
- 软件工程需求与模型选择:原型化与限制
- 掌握GCC链接器ld:中文翻译与实用指南
- Ubuntu 8.04 安装与入门指南:新手快速上手必备
- 面向服务架构(SOA)与Web服务入门
- 详解Linux下GNUMake编译工具使用指南
