深入理解Kafka:架构、原理与核心API
153 浏览量
更新于2024-08-31
收藏 475KB PDF 举报
"kafka架构与原理"
Kafka是一款分布式流处理平台,它的设计目标是处理大规模实时数据流。它提供了一种高效、可扩展、高可用的解决方案,用于在生产者和消费者之间传递消息,同时也支持数据的持久化和容错。
在Kafka中,以下几个核心概念至关重要:
1. **Kafka集群**:Kafka运行在一组服务器上,形成一个集群,这些服务器协同工作以存储和传输数据。集群中的每个服务器称为**Broker**。
2. **主题(Topics)**:主题是Kafka中数据流的基本单位,它们类似于分类或频道,用于存储特定类型的消息。每个主题可以被划分为多个**分区(Partitions)**,以实现水平扩展和负载均衡。
3. **分区(Partitions)**:每个主题包含多个分区,分区是物理上的概念,每个分区是一个有序且不可变的消息序列。分区内的消息按照特定的顺序(通常是生产时的时间戳或自增ID)存储,确保消息的顺序性。
4. **日志(Logs)**:每个分区对应一个逻辑日志文件,存储着分区内的所有消息。日志提供了持久化功能,即使服务器出现故障,也能保证数据不丢失。
5. **消息记录**:消息记录由键、值和时间戳组成,键和值可以是任何类型的数据,时间戳记录了消息产生的时刻。
6. **API**:Kafka提供了四个主要的API:
- **生产者API**:允许应用程序将记录流发布到一个或多个主题,通过选择合适的分区策略,保证消息的正确分布。
- **消费者API**:消费者可以订阅一个或多个主题,读取并处理来自这些主题的记录流,通常采用拉取(Pull)模式从Broker获取数据。
- **Streams API**:用于创建流处理应用程序,可以从一个或多个输入主题转换数据并写入输出主题,实现数据的实时处理和转换。
- **Connector API**:用于构建可重用的生产者或消费者,将Kafka主题与其他系统(如数据库)连接,实现数据的同步和集成。
7. **通信协议**:Kafka使用简单、高性能的TCP协议进行客户端和服务器之间的通信,支持多种语言的客户端库,包括Java和其他语言。
8. **ZooKeeper**:Kafka依赖ZooKeeper进行集群管理和协调,例如管理Broker、主题和分区的状态。
9. **容错性**:通过副本机制,每个分区都有一个主分区(leader)和若干个跟随者(followers),当leader故障时,followers可以自动晋升为新的leader,保证服务的连续性。
10. **水平扩展**:通过增加更多的Broker和分区,Kafka可以轻松地处理更大的消息量和更多的并发消费者。
Kafka是一个强大的消息中间件,适用于大数据实时处理、日志收集、网站活动追踪等多种场景。其高吞吐量、低延迟、容错性和易于扩展的特性使其在现代分布式系统中扮演了关键角色。
kafka架构与原理架构与原理
1、简介
它可以让你发布和订阅记录流。在这方面,它类似于一个消息队列或企业消息系统。
它可以让你持久化收到的记录流,从而具有容错能力。
首先,明确几个概念:
Kafka运行在一个或多个服务器上。
Kafka集群分类存储的记录流被称为主题(Topics)。
每个消息记录包含一个键,一个值和时间戳。
Kafka有四个核心API:
生产者 API 允许应用程序发布记录流至一个或多个Kafka的话题(Topics)。
消费者API 允许应用程序订阅一个或多个主题,并处理这些主题接收到的记录流。
Streams API 允许应用程序充当流处理器(stream processor),从一个或多个主题获取输入流,并生产一个输出流至一个或多
个的主题,能够有效地变换输入流为输出流。
Connector API 允许构建和运行可重用的生产者或消费者,能够把 Kafka主题连接到现有的应用程序或数据系统。例如,一个
连接到关系数据库的连接器(connector)可能会获取每个表的变化。
Kafka的客户端和服务器之间的通信是靠一个简单的,高性能的,与语言无关的TCP协议完成的。这个协议有不同的版本,并
保持向前兼容旧版本。Kafka不光提供了一个Java客户端,还有许多语言版本的客户端。
2、 架构
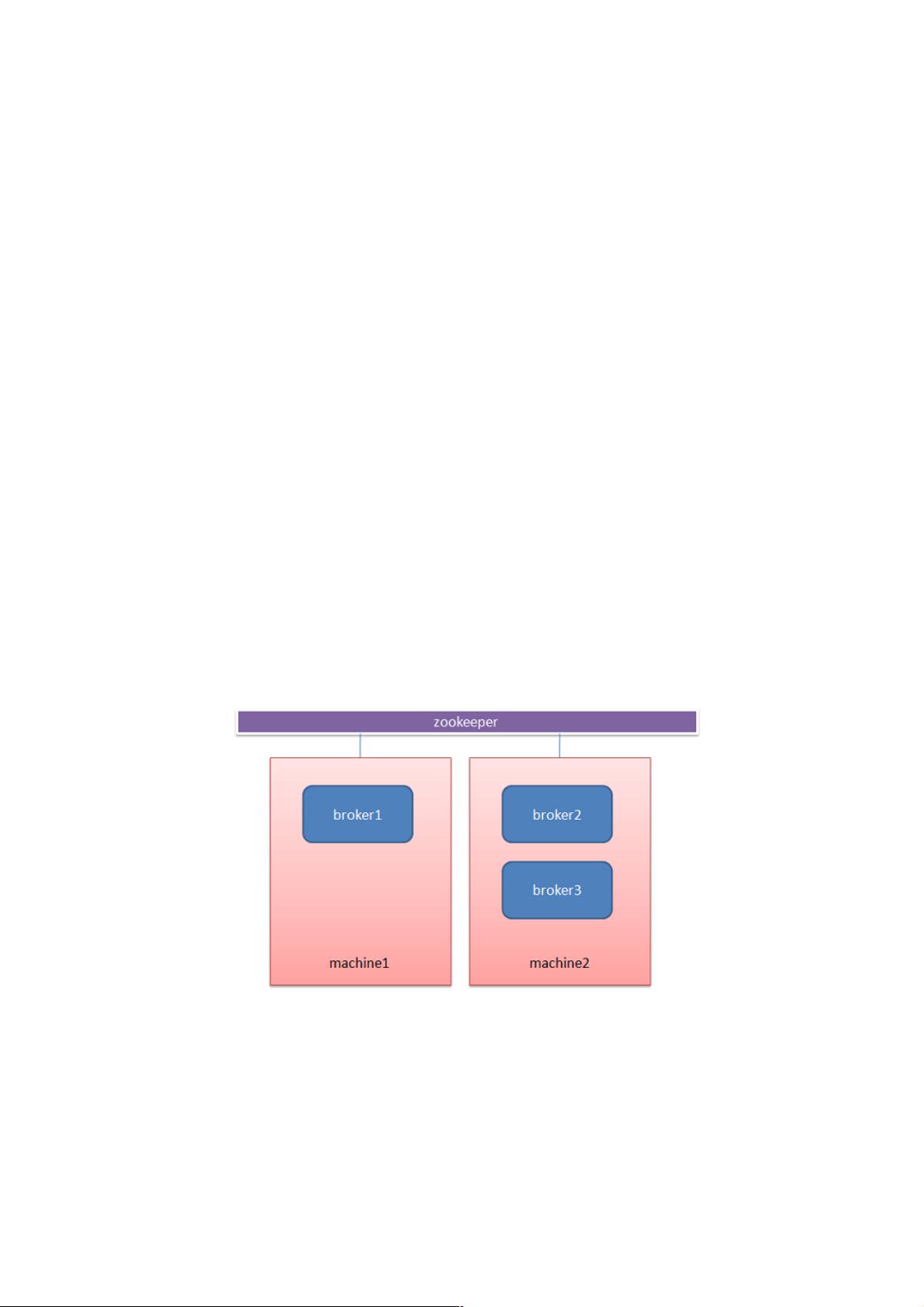
2.1 Broker
每个kafka server称为一个Broker,多个borker组成kafka cluster。一个机器上可以部署一个或者多个Broker,这多个Broker连
接到相同的ZooKeeper就组成了Kafka集群。
2.2 主题Topic
让我们先来了解Kafka的核心抽象概念记录流 – 主题。主题是一种分类或发布的一系列记录的名义上的名字。Kafka的主题始
终是支持多用户订阅的; 也就是说,一个主题可以有零个,一个或多个消费者订阅写入的数据。
Topic 与broker
一个Broker上可以创建一个或者多个Topic。同一个topic可以在同一集群下的多个Broker中分布。
下载后可阅读完整内容,剩余8页未读,立即下载
2022-06-09 上传
2023-07-27 上传
2023-06-26 上传
2023-06-28 上传
2024-04-09 上传
2024-01-10 上传
2024-04-11 上传
2023-06-07 上传

weixin_38668243
- 粉丝: 5
- 资源: 956
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
