OPTICS算法:揭示数据聚类结构
需积分: 9 186 浏览量
更新于2024-09-19
收藏 252KB PDF 举报
"OPTICS: Order Points To Identify the Clustering Structure"
OPTICS,全称为Ordering Points To Identify the Clustering Structure,是一种在数据挖掘领域中用于聚类分析的算法。聚类分析是数据库挖掘的核心技术之一,它能帮助我们洞察数据集的分布特性,或者作为进一步分析和数据处理的前置步骤,也能为其他在此基础上运行的算法提供预处理结果。传统的聚类算法,如K-Means、DBSCAN等,通常需要用户设定输入参数,这些参数的确定难度高且对聚类结果有显著影响。
在许多真实世界的数据集中,很难找到一个全局的参数设置,使得算法能够准确地描述内在的聚类结构。为此,OPTICS算法应运而生。它采取了一种不同的方法,不直接生成聚类结果,而是生成一个增强的数据库排序,这个排序反映了数据的密度基聚类结构。这种“聚类排序”包含了与广泛参数设置下的密度基础聚类相对应的信息,因此它对于自动和交互式的聚类分析非常灵活。
在OPTICS算法中,每个数据点根据其到达半径(reachability distance)被排序,这是一种衡量数据点之间联系紧密程度的度量。到达半径结合了数据点之间的距离和一个可变的最小密度阈值(epsilon),使得算法能在不同密度区域中捕捉到聚类。通过这种方式,OPTICS能够处理具有不同密度和大小的聚类,甚至可以识别出噪声和离群点。
算法的主要优点在于其对参数的鲁棒性。虽然仍需要设定epsilon和最小点数(minPts),但OPTICS的结果并不严重依赖于这些参数的具体值。它能够生成一个连续的聚类顺序,展示出数据点从低密度区域到高密度区域的过渡,从而揭示出数据的层次结构。这使得用户可以在后续分析中选择感兴趣的聚类级别,而不需要预先确定理想的聚类数量。
为了自动和有效地利用OPTICS的输出,可以通过设定阈值来分割聚类顺序,或者采用交互式的方式探索不同层次的聚类。此外,由于OPTICS能够保留所有可能的聚类结构,它也适用于发现动态变化或时序数据中的聚类模式。
OPTICS算法提供了一种更为灵活且适应性强的聚类方法,尤其适合那些具有复杂分布和多尺度聚类特征的数据集。它在无需精确预设参数的情况下,能够揭示数据的内在结构,对于数据挖掘和分析工作具有重要的价值。
hierarchical data structure designed for a multiphase clustering
method. First, the database is scanned to build an initial in-
memory CF-tree which can be seen as a multi-level compres-
sion of the data that tries to preserve the inherent clustering
structure of the data. Second, an arbitrary clustering algorithm
can be used to cluster the leaf nodes of the CF-tree. Because
BIRCH is reasonably fast, it can be used as a more intelligent
alternative to data sampling in order to improve the scalability
of clustering algorithms.
3. Ordering The Database With Respect To
The Clustering Structure
3.1 Motivation
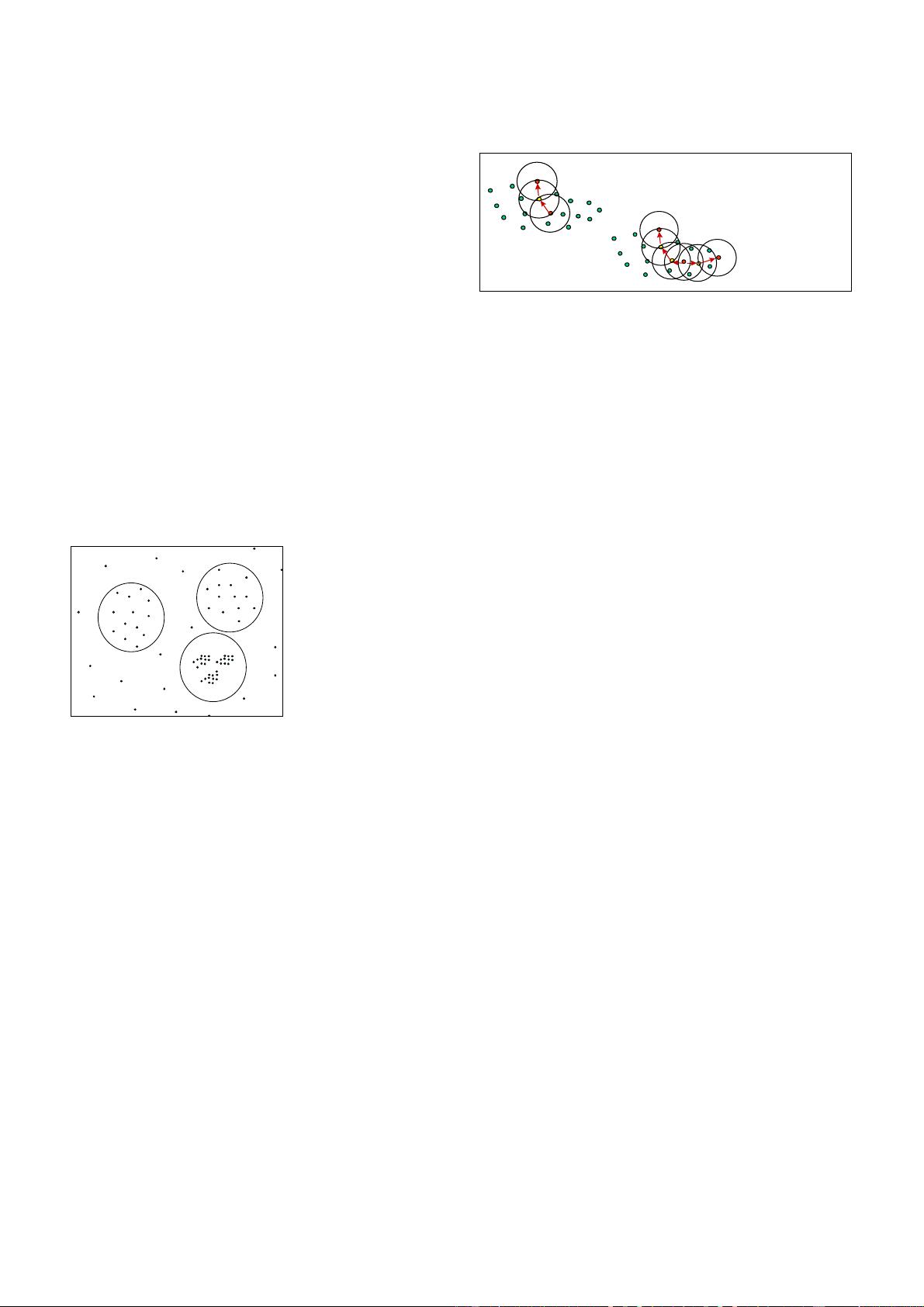
An important property of many real-data sets is that their intrin-
sic cluster structure cannot be characterized by global density
parameters. Very different local densities may be needed to re-
veal clusters in different regions of the data space. For example,
in the data set depicted in Figure 1, it is not possible to detect the
clusters A, B, C
1
, C
2
, and C
3
simultaneously using one global
density parameter. A global density-based decomposition
would consist only of the clusters A, B, and C, or C
1
, C
2
, and C
3
.
In the second case, the objects from A and B are noise.
The first alternative to
detect and analyze such
clustering structures is to
use a hierarchical cluster-
ing algorithm, for in-
stance the single-link
method. This alternative,
however, has two draw-
backs. First, in general it
suffers considerably
from the single-link ef-
fect, i.e. from the fact that
clusters which are con-
nected by a line of few points having a small inter-object dis-
tance are not separated. Second, the results produced by
hierarchical algorithms, i.e. the dendrograms, are hard to under-
stand or analyze for more than a few hundred objects.
The second alternative is to use a density-based partitioning al-
gorithm with different parameter settings. However, there are
an infinite number of possible parameter values. Even if we use
a very large number of different values - which requires a lot of
secondary memory to store the different cluster memberships
for each point - it is not obvious how to analyze the results and
we may still miss the interesting clustering levels.
The basic idea to overcome these problems is to run an algo-
rithm which produces a special order of the database with re-
spect to its density-based clustering structure containing the
information about every clustering level of the data set (up to a
“generating distance” ε), and is very easy to analyze.
3.2 Density-Based Clustering
The key idea of density-based clustering is that for each object
of a cluster the neighborhood of a given radius (ε) has to contain
at least a minimum number of objects (MinPts), i.e. the cardi-
nality of the neighborhood has to exceed a threshold. The for-
mal definitions for this notion of a clustering are shortly
introduced in the following. For a detailed presentation see
[EKSX 96].
Definition 1: (directly density-reachable)
Object p is directly density-reachable from object q wrt. ε
and MinPts in a set of objects D if
1) p ∈ N
ε
(q) (N
ε
(q) is the subset of D contained in the
ε-neighborhood of q.)
2) Card(N
ε
(q)) ≥ MinPts (Card(N) denotes the cardinal-
ity of the set N)
The condition Card(N
ε
(q)) ≥ MinPts is called the “core object
condition”. If this condition holds for an object p, then we call
p a “core object”. Only from core objects, other objects can be
directly density-reachable.
Definition 2: (density-reachable)
An object p is density-reachable from an object q wrt. ε
and MinPts in the set of objects D if there is a chain of ob-
jects p
1
, ..., p
n
, p
1
= q, p
n
= p such that p
i
∈D and p
i+1
is
directly density-reachable from p
i
wrt. ε and MinPts.
Density-reachability is the transitive hull of direct density-
reachability. This relation is not symmetric in general. Only
core objects can be mutually density-reachable.
Definition 3: (density-connected)
Object p is density-connected to object q wrt. ε and MinPts
in the set of objects D if there is an object o ∈D such that
both p and q are density-reachable from o wrt. ε and
MinPts in D.
Density-connectivity is a symmetric relation. Figure 2 illus-
trates the definitions on a sample database of 2-dimensional
points from a vector space. Note that the above definitions only
require a distance measure and will also apply to data from a
metric space.
A density-based cluster is now defined as a set of density-con-
nected objects which is maximal wrt. density-reachability and
the noise is the set of objects not contained in any cluster.
Definition 4: (cluster and noise)
Let D be a set of objects. A cluster C wrt. ε and MinPts in
D is a non-empty subset of D satisfying the following con-
ditions:
1) Maximality: ∀p,q ∈D: if p ∈C and q is density-reach-
able from p wrt. ε and MinPts, then also q ∈C.
2) Connectivity: ∀p,q ∈ C: p is density-connected to q wrt.
ε and MinPts in D.
Every object not contained in any cluster is noise.
Note that a cluster contains not only core objects but also ob-
jects that do not satisfy the core object condition. These objects
Figure 1. Clusters wrt. different
density parameters
A
B
C
C
1
C
2
C
3
p
q
o
p
q
Figure 2. Density-reachability and connectivity
p density-reachable from q
q not density-reachable from p
p and q density-connected
to each other by o
剩余11页未读,继续阅读
109 浏览量
191 浏览量
145 浏览量
2022-07-11 上传
2024-01-04 上传
216 浏览量
点击了解资源详情
234 浏览量
892 浏览量

cykiko
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 小学水墨风学校网站模板设计
- 深入理解线程池的实现原理与应用
- MSP430编程代码集锦:实用例程源码分享
- 绿色大图幻灯商务响应式企业网站开发源码包
- 深入理解CSS与Web标准的专业解决方案
- Qt/C++集成Google拼音输入法演示Demo
- Apache Hive 0.13.1 版本安装包详解
- 百度地图范围标注技术及应用
- 打造个性化的Windows 8锁屏体验
- Atlantis移动应用开发深度解析
- ASP.NET实验教程:源代码详细解析与实践
- 2012年工业观察杂志完整版
- 全国综合缴费营业厅系统11.5:一站式缴费与运营管理解决方案
- JAVA原生实现HTTP请求的简易指南
- 便携PDF浏览器:随时随地快速查看文档
- VTF格式图片编辑工具:深入起源引擎贴图修改
